gigagan pytorch
0.2.20

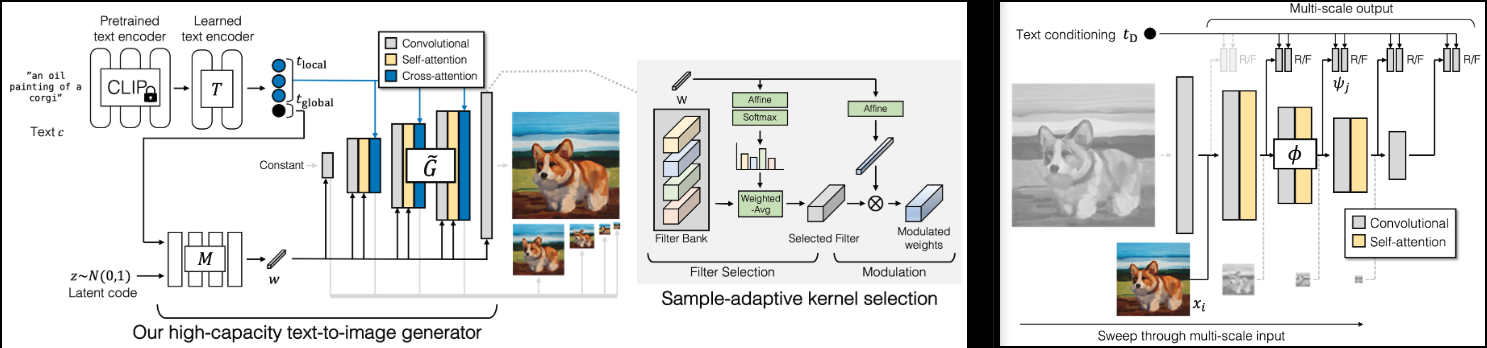
Implementasi GigaGAN (halaman proyek), SOTA GAN baru dari Adobe.
Saya juga akan menambahkan beberapa temuan dari ringan gan, untuk konvergensi yang lebih cepat (lewati eksitasi lapisan) dan stabilitas yang lebih baik (rekonstruksi kerugian tambahan dalam diskriminator)
Ini juga akan berisi kode untuk upsampler 1k - 4k, yang menurut saya menjadi sorotan makalah ini.
Silakan bergabung jika Anda tertarik membantu replikasi bersama komunitas LAION
StabilitasAI dan ? Huggingface atas sponsor yang murah hati, serta sponsor saya yang lain, yang telah memberi saya kebebasan terhadap kecerdasan buatan sumber terbuka.
? Huggingface untuk perpustakaan akselerasi mereka
Semua pengelola di OpenClip, untuk model teks-gambar pembelajaran kontrastif sumber terbuka SOTA mereka
Xavier untuk tinjauan kode yang sangat membantu, dan untuk diskusi tentang bagaimana invariansi skala dalam diskriminator harus dibangun!
@CerebralSeed untuk permintaan tarik kode pengambilan sampel awal untuk generator dan upsampler!
Keerth untuk tinjauan kode dan menunjukkan beberapa perbedaan dengan makalah!
$ pip install gigagan-pytorchGAN sederhana tanpa syarat, sebagai permulaan
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Untuk Unet Upsampler tanpa syarat
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - PembangkitMSG - Generator MultiskalaD - DiskriminatorMSD - Diskriminator MultiskalaGP - Penalti GradienSSL - Rekonstruksi Tambahan dalam Diskriminator (dari GAN Ringan)VD - Diskriminator dengan bantuan penglihatanVG - Generator dengan bantuan penglihatanCL - Generator Kerugian KonstrasifMAL - Mencocokkan Sadar Kalah Lari yang sehat akan memiliki G , MSG , D , MSD dengan nilai berkisar antara 0 hingga 10 , dan biasanya tetap konstan. Jika suatu saat setelah 1.000 langkah pelatihan, nilai-nilai ini tetap pada tiga digit, itu berarti ada sesuatu yang salah. Tidak masalah jika nilai generator dan diskriminator kadang-kadang turun menjadi negatif, tetapi nilai tersebut akan berayun kembali ke kisaran di atas.
GP dan SSL harus didorong menuju 0 . GP terkadang bisa melonjak; Saya suka membayangkannya sebagai jaringan yang mengalami pencerahan
Kelas GigaGAN kini dilengkapi dengan ? Akselerator. Anda dapat dengan mudah melakukan pelatihan multi-gpu dalam dua langkah menggunakan CLI accelerate
Di direktori root proyek, tempat skrip pelatihan berada, jalankan
$ accelerate configKemudian, di direktori yang sama
$ accelerate launch train . py pastikan itu dapat dilatih tanpa syarat
baca makalah yang relevan dan hilangkan ketiga kerugian tambahan
hapus upsampler
dapatkan tinjauan kode untuk input dan output multiskala, karena makalahnya agak kabur
tambahkan arsitektur jaringan upsampling
membuat pekerjaan tanpa syarat untuk generator dasar dan upsampler
membuat pelatihan terkondisi teks berfungsi untuk base dan upsampler
membuat pengintaian lebih efisien dengan pengambilan sampel acak
pastikan generator dan diskriminator juga dapat menerima pengkodean teks CLIP yang telah dikodekan sebelumnya
melakukan peninjauan terhadap kerugian pembantu
tambahkan beberapa augmentasi yang dapat dibedakan, teknik yang telah terbukti dari masa GAN dulu
pindahkan semua proyeksi modulasi ke kelas konv2d adaptif
tambahkan percepatan
clip harus bersifat opsional untuk semua modul, dan dikelola oleh GigaGAN , dengan text -> text embeds diproses satu kali
tambahkan kemampuan untuk memilih subset acak dari dimensi multiskala, untuk efisiensi
port melalui CLI dari ringan|stylegan2-pytorch
menghubungkan kumpulan data laion untuk gambar teks
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

