byol pytorch
0.8.2
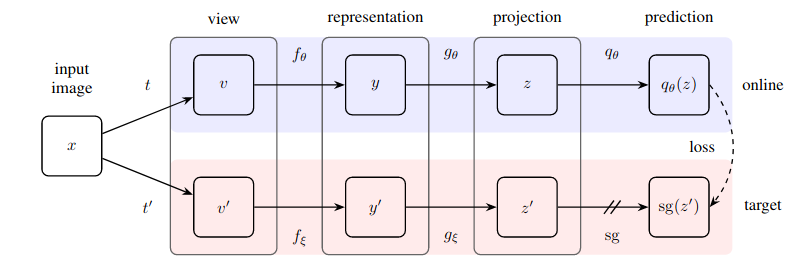
Implementasi praktis dari metode pembelajaran mandiri yang sangat sederhana yang mencapai tingkat seni baru (melampaui SimCLR) tanpa pembelajaran kontrastif dan harus menentukan pasangan negatif.
Repositori ini menawarkan modul yang dapat dengan mudah menggabungkan jaringan saraf berbasis gambar apa pun (jaringan sisa, diskriminator, jaringan kebijakan) untuk segera mulai memanfaatkan data gambar yang tidak berlabel.
Pembaruan 1: Kini terdapat bukti baru bahwa normalisasi batch adalah kunci untuk membuat teknik ini bekerja dengan baik
Pembaruan 2: Makalah baru telah berhasil menggantikan norma batch dengan norma kelompok + standardisasi bobot, menyangkal bahwa statistik batch diperlukan agar BYOL dapat berfungsi
Pembaruan 3: Terakhir, kami memiliki beberapa analisis mengapa ini berhasil
Penjelasan Yannic Kilcher yang luar biasa
Sekarang selamatkan organisasi Anda dari keharusan membayar label :)
$ pip install byol-pytorchCukup pluginkan jaringan saraf Anda, tentukan (1) dimensi gambar serta (2) nama (atau indeks) lapisan tersembunyi, yang keluarannya digunakan sebagai representasi laten yang digunakan untuk pelatihan yang diawasi sendiri.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Cukup banyak. Setelah banyak pelatihan, jaringan sisa kini akan berkinerja lebih baik pada tugas-tugas hilirnya yang diawasi.
Makalah baru dari Kaiming menunjukkan bahwa BYOL bahkan tidak memerlukan encoder target untuk menjadi rata-rata pergerakan eksponensial dari encoder online. Saya telah memutuskan untuk membangun opsi ini sehingga Anda dapat dengan mudah menggunakan varian tersebut untuk pelatihan, cukup dengan menyetel tanda use_momentum ke False . Anda tidak perlu lagi memanggil update_moving_average jika Anda menggunakan rute ini seperti yang ditunjukkan pada contoh di bawah.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Meskipun hyperparameter telah disetel ke tingkat optimal yang menurut makalah, Anda dapat mengubahnya dengan argumen kata kunci tambahan ke kelas pembungkus dasar.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) Secara default, perpustakaan ini akan menggunakan augmentasi dari makalah SimCLR (yang juga digunakan dalam makalah BYOL). Namun, jika Anda ingin menentukan saluran augmentasi Anda sendiri, Anda cukup meneruskan fungsi augmentasi khusus Anda sendiri dengan kata kunci augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)Dalam makalah tersebut, mereka tampaknya memastikan bahwa salah satu augmentasi memiliki kemungkinan keburaman gaussian yang lebih tinggi dibandingkan yang lain. Anda juga bisa menyesuaikannya dengan keinginan hati Anda.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Untuk mengambil embeddings atau proyeksi, Anda cukup meneruskan tanda return_embeddings = True ke instance pelajar BYOL
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) Repositori sekarang menawarkan pelatihan terdistribusi dengan ? Mempercepat Wajah Memeluk. Anda hanya perlu memasukkan Dataset Anda sendiri ke BYOLTrainer yang diimpor
Pertama-tama siapkan konfigurasi untuk pelatihan terdistribusi dengan menjalankan CLI akselerasi
$ accelerate config Kemudian buat skrip pelatihan Anda seperti yang ditunjukkan di bawah ini, misalnya di ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Kemudian gunakan CLI akselerasi lagi untuk meluncurkan skrip
$ accelerate launch ./train.pyJika tugas hilir Anda melibatkan segmentasi, silakan lihat repositori berikut, yang memperluas BYOL ke pembelajaran tingkat 'piksel'.
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

