atari
1.0.0

Research Playground yang dibangun di atas Atari Gym OpenAI, disiapkan untuk mengimplementasikan berbagai algoritma Reinforcement Learning.
Itu dapat meniru salah satu game berikut:
['Asterix', 'Asteroid', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'Ski', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' Venture', 'Riverraid', 'Kelabang', 'Petualangan', 'BeamRider', 'CrazyClimber', 'TimePilot', 'Karnaval', 'Tenis', 'Seaquest', 'Bowling', 'SpaceInvaders', 'Freeway', 'YarsRevenge', 'RoadRunner', 'JourneyEscape', 'WizardOfWor', 'Gopher ', 'Breakout', 'StarGunner', 'Atlantis', 'DoubleDunk', 'Pahlawan', 'BattleZone', 'Solaris', 'UpNDown', 'Frostbite', 'KungFuMaster', 'Pooyan', 'Pitfall', 'MontezumaRevenge', 'PrivateEye', 'AirRaid', 'Amidar', 'Robotank ', 'Serangan Setan', 'Pembela', 'NamaGame Ini', 'Phoenix', 'Gravitar', 'ElevatorAction', 'Pong', 'VideoPinball', 'IceHockey', 'Boxing', 'Assault', 'Alien', 'Qbert', 'Enduro', 'ChopperCommand', 'Jamesbond']
Lihat artikel Medium terkait: Atari - Pembelajaran Penguatan secara mendalam? (Bagian 1: DDQN)
Tujuan akhir dari proyek ini adalah untuk menerapkan dan membandingkan berbagai pendekatan RL dengan permainan atari sebagai kesamaan.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Jaringan Neural Konvolusional Dalam oleh DeepMind
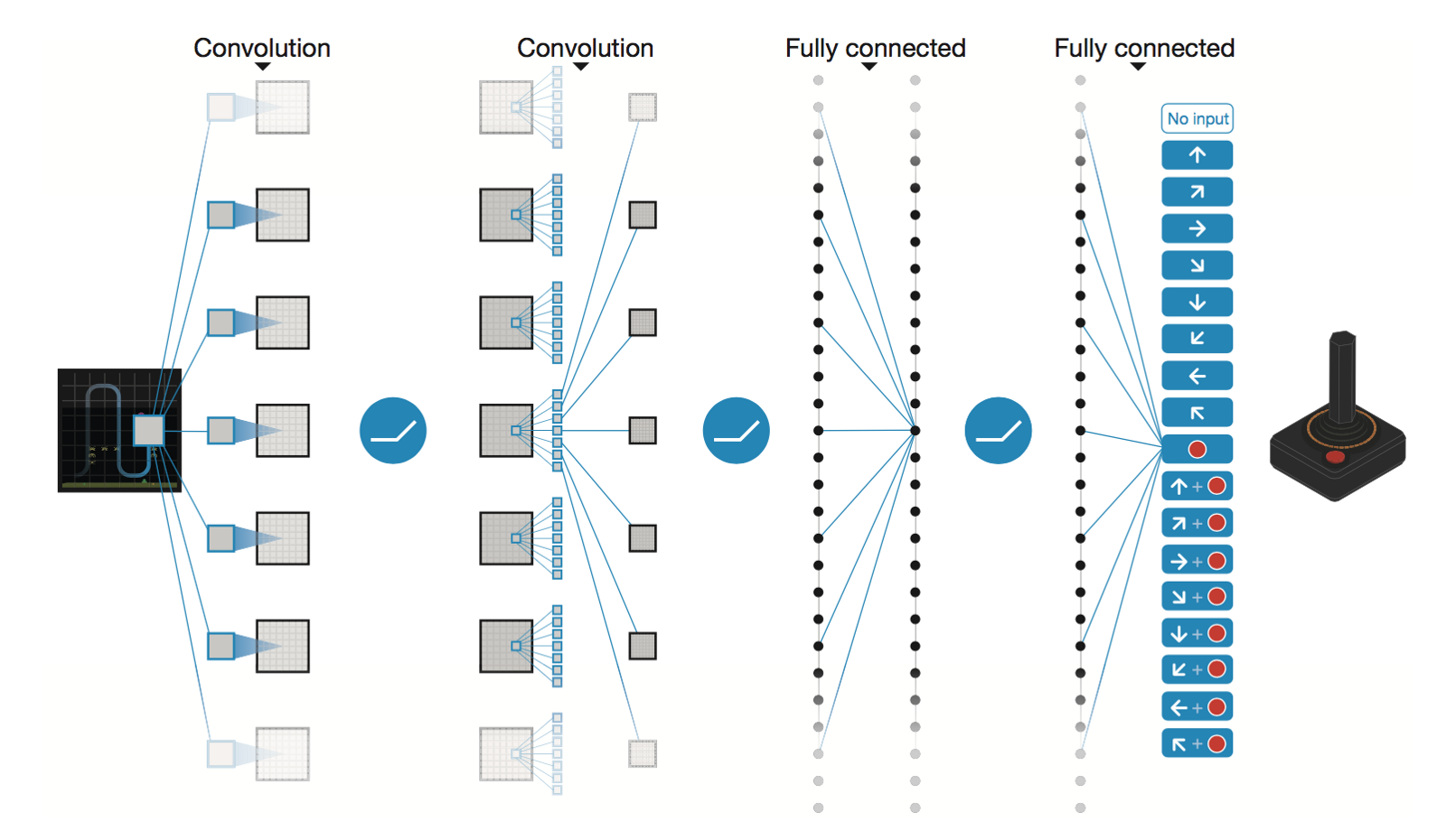
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
Setelah 5M langkah ( ~40 jam pada GPU Tesla K80 atau ~90 jam pada CPU Intel i7 Quad-Core 2,9 GHz):
Pelatihan:
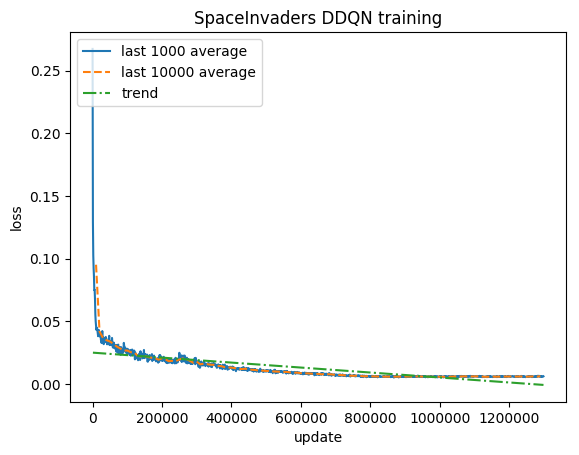
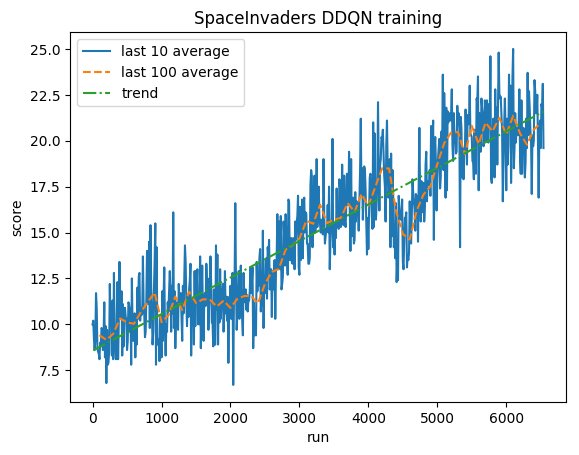
Skor yang dinormalisasi - setiap hadiah dipotong menjadi (-1, 1)
Pengujian:
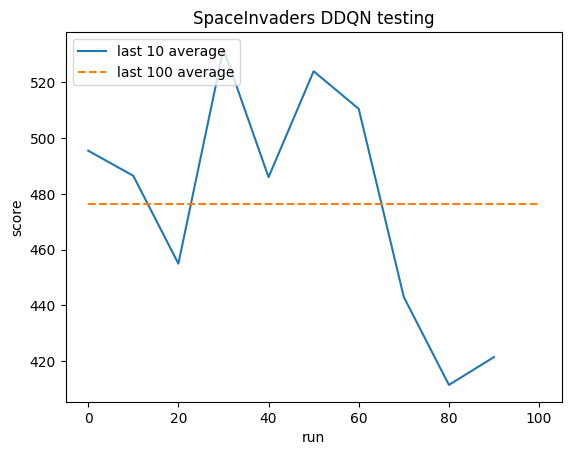
Rata-rata manusia: ~372
Rata-rata DDQN: ~479 (128%)
Pelatihan:
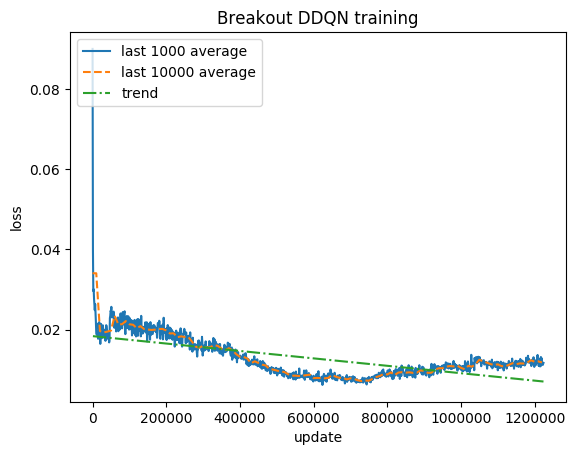
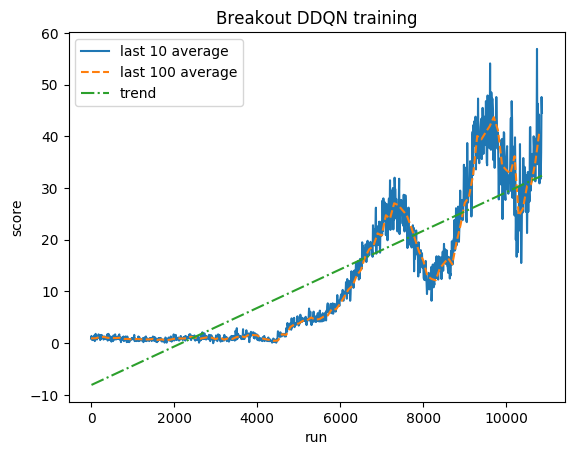
Skor yang dinormalisasi - setiap hadiah dipotong menjadi (-1, 1)
Pengujian:
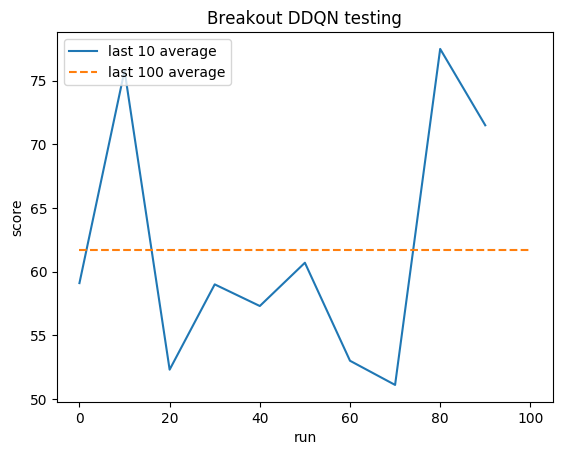
Rata-rata manusia: ~28
Rata-rata DDQN: ~62 (221%)
Pelatihan:
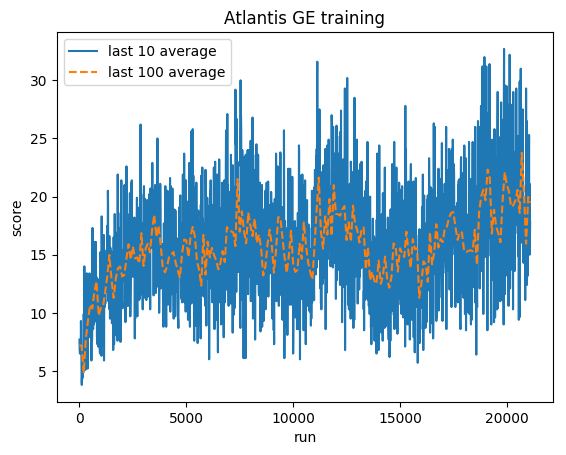
Skor yang dinormalisasi - setiap hadiah dipotong menjadi (-1, 1)
Pengujian:

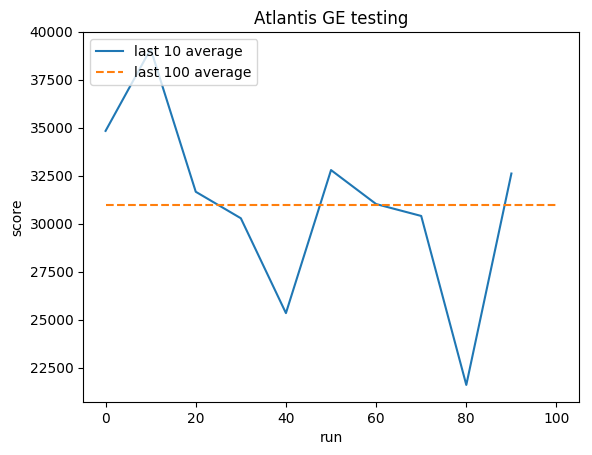
Rata-rata manusia: ~29.000
Rata-rata GE: 31.000 (106%)
Greg (Grzegorz) Surma
PORTOFOLIO
GITHUB
BLOG


