sinkhorn transformer
0.11.4
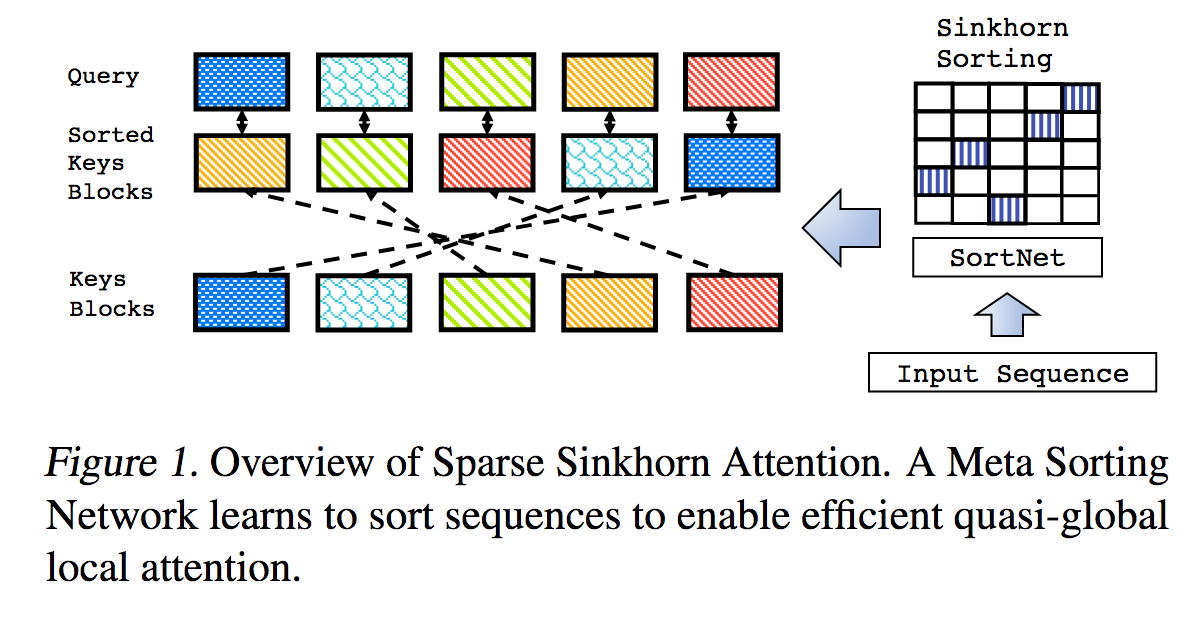
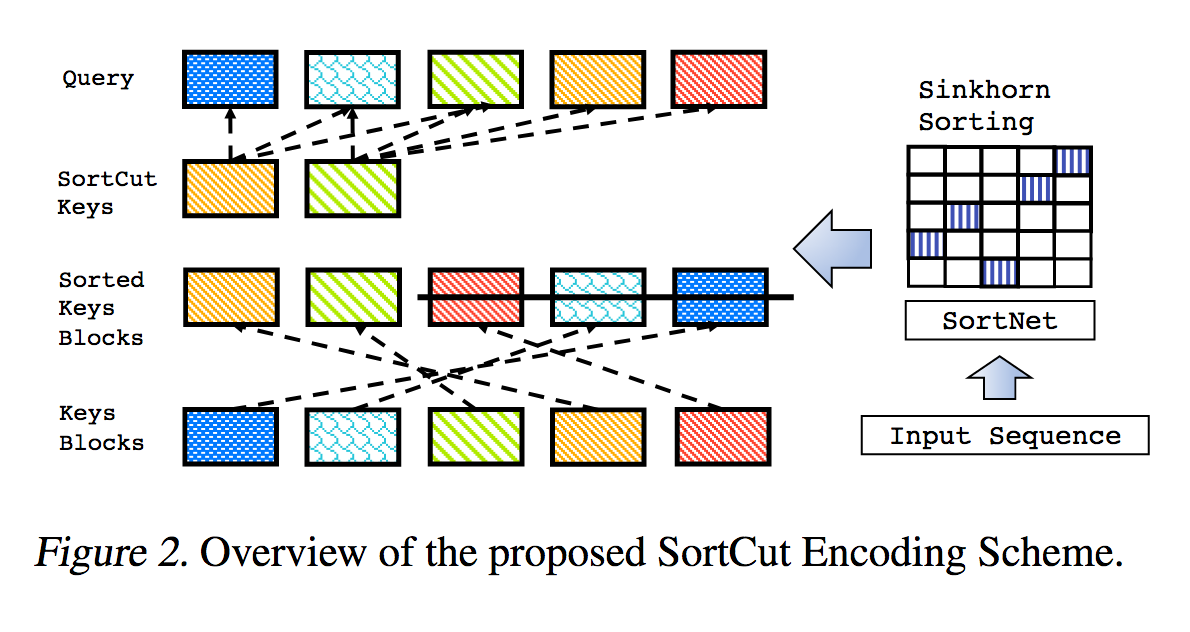
Ini adalah reproduksi karya yang diuraikan dalam Sparse Sinkhorn Attention, dengan penyempurnaan tambahan.
Ini mencakup jaringan pengurutan berparameter, menggunakan normalisasi sinkhorn untuk mengambil sampel matriks permutasi yang cocok dengan kumpulan kunci yang paling relevan dengan kumpulan kueri.
Pekerjaan ini juga menghadirkan jaringan reversibel dan feed forward chunking (konsep yang diperkenalkan dari Reformer) untuk menghasilkan penghematan memori lebih lanjut.
Token 204k (tujuan demonstrasi)
$ pip install sinkhorn_transformerModel bahasa berbasis Sinkhorn Transformer
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)Transformator Sinkhorn polos, lapisan perhatian sinkhorn
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)Transformator Enkoder / Dekoder Sinkhorn
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) Secara default model akan melakukan komplain jika diberikan input yang bukan kelipatan dari ukuran bucket. Untuk menghindari keharusan membuat perhitungan padding yang sama setiap kali, Anda dapat menggunakan kelas pembantu Autopadder . Ini juga akan menangani input_mask untuk Anda, jika diberikan. Kunci/nilai kontekstual dan mask juga didukung.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) Repositori ini telah menyimpang dari kertas dan sekarang menggunakan perhatian sebagai pengganti jaring penyortiran asli + pengambilan sampel gumbel sinkhorn. Saya belum menemukan perbedaan nyata dalam kinerjanya, dan skema baru ini memungkinkan saya menggeneralisasi jaringan ke panjang urutan yang fleksibel. Jika Anda ingin mencoba Sinkhorn, silakan gunakan pengaturan berikut, yang hanya berfungsi untuk jaringan non-kausal.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) Untuk melihat manfaat penggunaan PKM, nilai kecepatan pemelajaran harus ditetapkan lebih tinggi daripada parameter lainnya. (Direkomendasikan menjadi 1e-2 )
Anda dapat mengikuti petunjuk di sini untuk mengaturnya dengan benar https://github.com/lucidrains/product-key-memory#learning-rates
Sinkhorn, ketika dilatih pada rangkaian dengan panjang tetap, tampaknya mengalami kesulitan dalam menguraikan rangkaian dari awal, terutama karena fakta bahwa jaring penyortiran mengalami kesulitan dalam menggeneralisasi ketika sebagian ember diisi dengan token bantalan.
Untungnya, saya rasa saya telah menemukan solusi sederhana. Selama pelatihan, untuk jaringan sebab akibat, potong urutannya secara acak dan paksa jaring penyortiran untuk menggeneralisasi. Saya telah menyediakan tanda ( randomly_truncate_sequence ) untuk instance AutoregressiveWrapper untuk mempermudahnya.
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)Saya terbuka untuk saran jika seseorang telah menemukan solusi yang lebih baik.
Ada potensi masalah dengan jaringan penyortiran kausal, di mana keputusan mana kunci/nilai keranjang dari jenis masa lalu ke dalam keranjang hanya bergantung pada token pertama dan bukan yang lainnya (karena skema pengelompokan dan mencegah kebocoran masa depan ke masa lalu).
Saya telah mencoba mengatasi masalah ini dengan memutar separuh kepala ke kiri dengan ukuran ember - 1, sehingga mempromosikan token terakhir menjadi yang pertama. Ini juga merupakan alasan mengapa AutoregressiveWrapper secara default menggunakan padding kiri selama pelatihan, untuk selalu memastikan bahwa token terakhir dalam urutan menentukan apa yang harus diambil.
Jika ada yang menemukan solusi yang lebih bersih, beri tahu saya di bagian masalahnya.
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


