LongNet
0.4.8

Ini adalah implementasi open source untuk makalah LongNet: Scaling Transformers to 1,000,000,000 Tokens oleh Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei. LongNet adalah varian Transformer yang dirancang untuk menskalakan panjang rangkaian hingga lebih dari 1 miliar token tanpa mengorbankan kinerja pada rangkaian yang lebih pendek.
pip install longnet Setelah Anda menginstal LongNet, Anda dapat menggunakan kelas DilatedAttention sebagai berikut:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerModel trafo pelatihan yang sepenuhnya siap dengan blok trafo dilatasi dengan Feedforward dengan layernorm, SWIGLU, dan blok trafo paralel
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
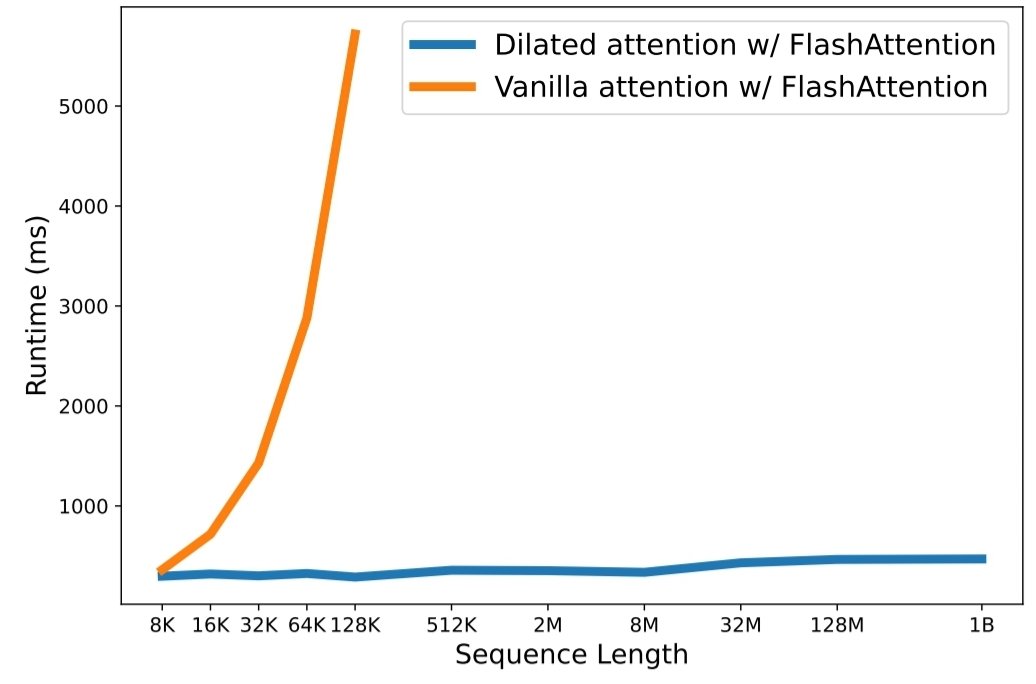
python3 train.py Penskalaan panjang urutan telah menjadi hambatan penting di era model bahasa besar. Namun, metode yang ada kesulitan dengan kompleksitas komputasi atau ekspresivitas model, sehingga panjang urutan maksimum menjadi terbatas. Dalam makalah ini, mereka memperkenalkan LongNet, varian Transformer yang dapat menskalakan panjang rangkaian hingga lebih dari 1 miliar token, tanpa mengorbankan kinerja pada rangkaian yang lebih pendek. Secara khusus, mereka mengusulkan perhatian melebar, yang memperluas bidang perhatian secara eksponensial seiring bertambahnya jarak.
LongNet memiliki keunggulan signifikan:
Hasil eksperimen menunjukkan bahwa LongNet menghasilkan kinerja yang kuat pada pemodelan urutan panjang dan tugas bahasa umum. Pekerjaan mereka membuka kemungkinan baru untuk memodelkan rangkaian yang sangat panjang, misalnya memperlakukan keseluruhan korpus atau bahkan seluruh Internet sebagai suatu rangkaian.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

