q transformer
0.3.0
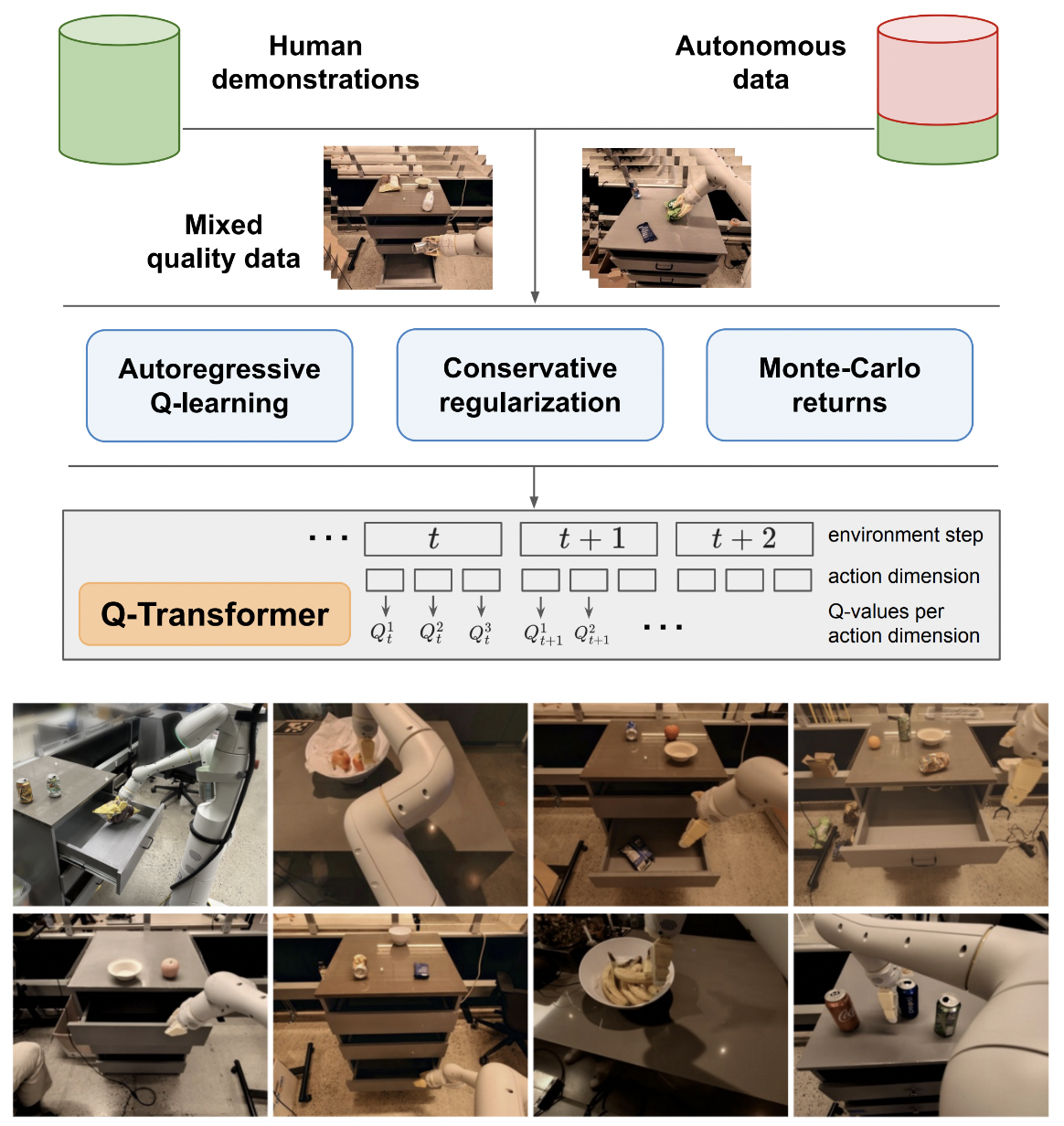
Penerapan Q-Transformer, Pembelajaran Penguatan Offline yang Dapat Diskalakan melalui Fungsi Q Autoregresif, dari Google Deepmind
Saya akan tetap menggunakan logika Q-learning pada tindakan tunggal hanya untuk perbandingan akhir dengan usulan Q-learning autoregresif pada beberapa tindakan. Juga sebagai edukasi bagi saya dan masyarakat.
Formulasi Q-learning autoregresif telah direproduksi oleh Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )cara kerja pertama menuju dukungan tindakan tunggal
menawarkan varian maxvit tanpa batchnorm, seperti yang dilakukan dalam model cuaca SOTA metnet3
tambahkan arsitektur duel mendalam opsional
tambahkan pembelajaran Q n-langkah
membangun regularisasi konservatif
menyusun proposal utama di atas kertas (tindakan diskrit autoregresif hingga tindakan terakhir, hadiah hanya diberikan pada tindakan terakhir)
mengimprovisasi varian kepala dekoder, alih-alih menggabungkan tindakan sebelumnya pada tahap bingkai + token yang dipelajari. dengan kata lain, gunakan encoder - decoder klasik
ulangi maxvit dengan penyematan putar aksial + gerbang sigmoid tanpa memperhatikan apa pun. aktifkan perhatian flash untuk maxvit dengan perubahan ini
membangun kelas pembuat kumpulan data sederhana, dengan mengambil lingkungan dan model serta mengembalikan folder yang dapat diterima oleh ReplayDataset
ReplayDataset yang mengambil folder menangani banyak instruksi dengan benar
tampilkan contoh ujung-ke-ujung yang sederhana, dengan gaya yang sama seperti semua repo lainnya
tidak menangani instruksi, manfaatkan kondisioner nol di perpustakaan CFG
cache kv untuk decoding tindakan
untuk eksplorasi, izinkan pengacakan sebagian tindakan, dan tidak semua tindakan sekaligus
konsultasikan dengan beberapa pakar RL dan cari tahu apakah ada kemajuan baru dalam menyelesaikan bias delusi
mencari tahu apakah seseorang dapat berlatih dengan urutan tindakan yang diacak - urutan dapat dikirim sebagai pengondisian yang digabungkan atau dijumlahkan sebelum lapisan perhatian
fungsi pencarian sinar sederhana untuk tindakan optimal
berimprovisasi dengan perhatian silang terhadap tindakan masa lalu dan status langkah waktu, mode transformator-xl (dengan putusnya memori terstruktur)
lihat apakah ide utama dalam makalah ini dapat diterapkan pada model bahasa di sini
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

