perfusion pytorch
0.1.23
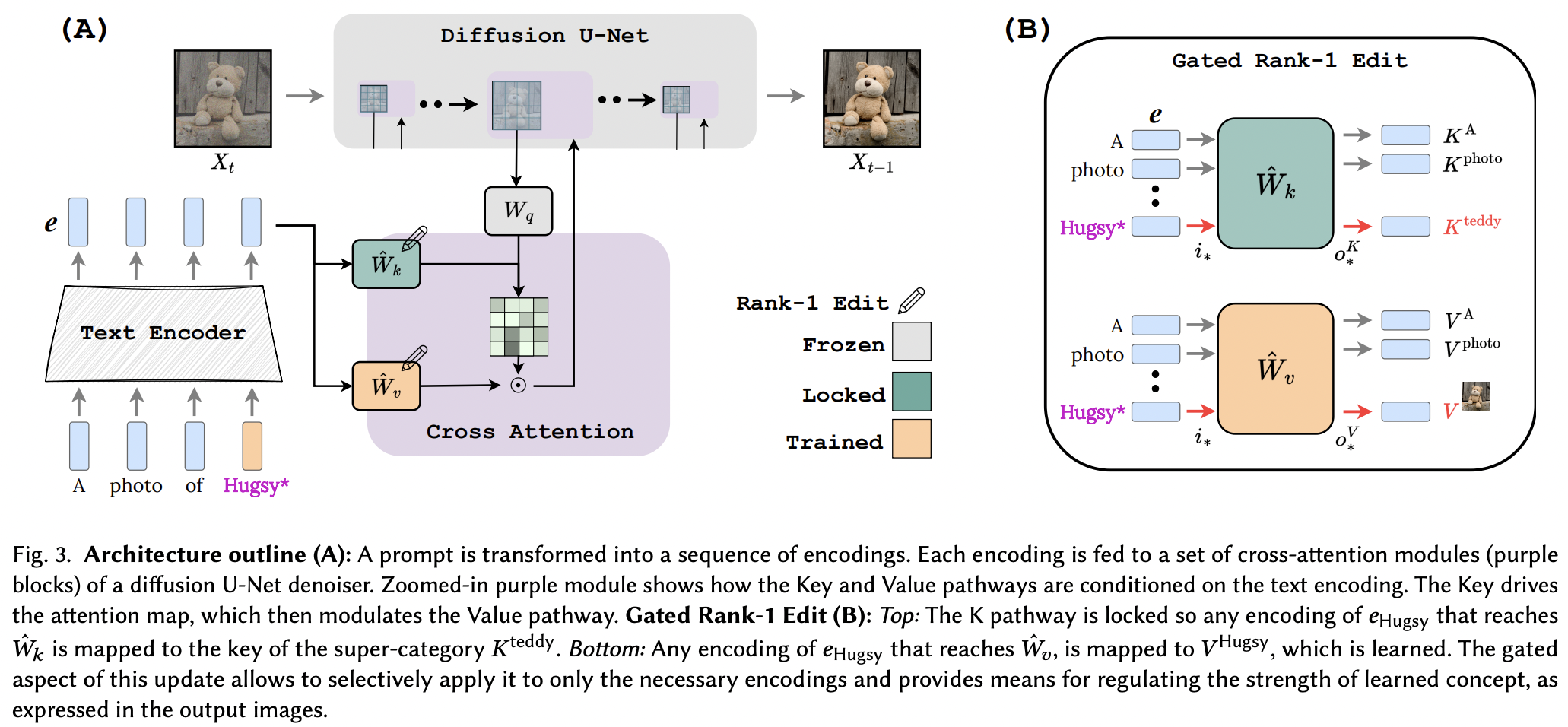
Penerapan Pengeditan Peringkat Satu Kunci Terkunci. Halaman proyek
Nilai jual makalah ini adalah parameter tambahan yang sangat rendah per konsep yang ditambahkan, hingga 100kb.
Tampaknya mereka berhasil menerapkan teknik pengeditan Peringkat-1 dari makalah pengeditan memori untuk LLM, dengan beberapa perbaikan. Mereka juga mengidentifikasi bahwa kunci menentukan "di mana" konsep baru, sedangkan nilai menentukan "apa", dan mengusulkan penguncian kunci lokal/global ke konsep superkelas (sambil mempelajari nilai).
Bagi para peneliti di luar sana, jika makalah ini berhasil, alat-alat dalam repositori ini harusnya berfungsi untuk jaringan text-to- <insert modality> lainnya yang menggunakan pengondisian perhatian silang. Hanya sebuah pemikiran
StabilityAI atas sponsor yang murah hati, serta sponsor saya yang lain di luar sana
Yoad Tewel untuk ulasan beberapa kode dan email klarifikasi
Brad Vidler untuk menghitung terlebih dahulu matriks kovarians untuk CLIP yang digunakan dalam Difusi Stabil 1.5!
Semua pengelola di OpenClip, untuk model teks-gambar pembelajaran kontrastif sumber terbuka SOTA mereka
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) Repositori juga berisi EmbeddingWrapper yang memudahkan pelatihan konsep baru (dan untuk inferensi pada akhirnya dengan banyak konsep)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Jika Anda dapat mengidentifikasi instance CLIP dalam instance difusi stabil, Anda juga dapat meneruskannya langsung ke OpenClipEmbedWrapper untuk mendapatkan semua yang Anda perlukan untuk lapisan perhatian silang
mantan.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) terhubung dengan SD 1.5, dimulai dengan dreambooth-sd xiao
tampilkan contoh di readme untuk inferensi dengan banyak konsep
secara otomatis menyimpulkan di mana proyeksi kunci dan nilai jika tidak ditentukan untuk fungsi make_key_value_proj_rank1_edit_modules_
pembungkus penyematan harus melakukan penggantian dengan id token kelas super dan mengembalikan penyematan dengan kelas super
meninjau berbagai konsep - terima kasih kepada Yoad
menawarkan fungsi yang menarik perhatian silang
menangani banyak konsep dalam satu perintah pada inferensi - penjumlahan suku sigmoid + keluaran
menawarkan cara untuk menggabungkan konsep yang dipelajari secara terpisah dari beberapa Rank1EditModule menjadi satu untuk inferensi
Rank1EditModule s tambahkan konsep zero-shot masking yang diusulkan dalam makalah
menangani fungsi yang menggunakan kumpulan data dan encoder teks serta menghitung terlebih dahulu matriks kovarians yang diperlukan untuk pembaruan peringkat-1
daripada membuat peneliti mengkhawatirkan kecepatan pembelajaran yang berbeda, tawarkan trik gradien pecahan dari makalah lain (untuk mempelajari penyematan konsep)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

