self rewarding lm pytorch
0.2.12
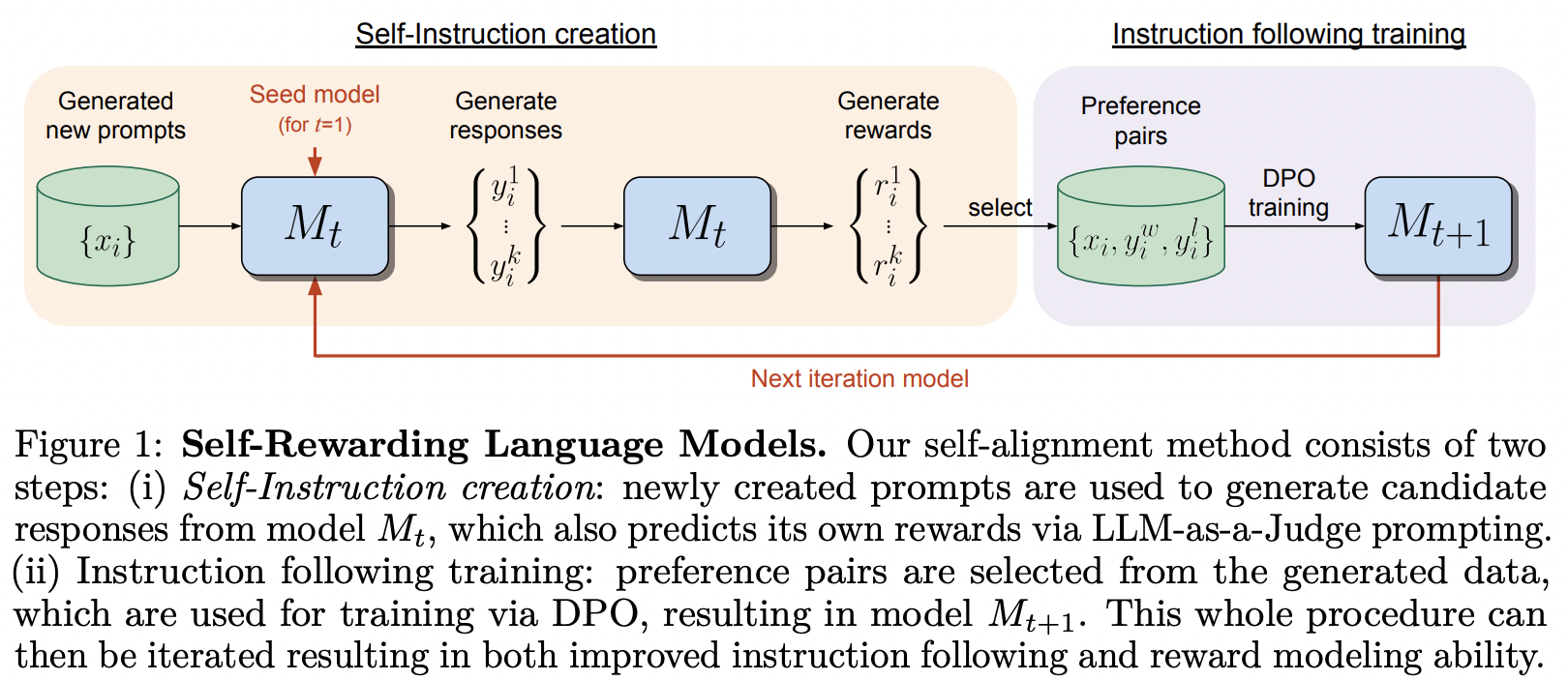
Implementasi kerangka pelatihan yang diusulkan dalam Self-Rewarding Language Model, dari MetaAI
Mereka sangat mencamkan judul makalah DPO tersebut.
Perpustakaan ini juga berisi implementasi SPIN, yang mana Teknium dari Nous Research telah menyatakan optimismenya.
$ pip install self-rewarding-lm-pytorch import torch
from torch import Tensor
from self_rewarding_lm_pytorch import (
SelfRewardingTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 1 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
prompt_dataset = create_mock_dataset ( 100 , lambda : 'mock prompt' )
def decode_tokens ( tokens : Tensor ) -> str :
decode_token = lambda token : str ( chr ( max ( 32 , token )))
return '' . join ( list ( map ( decode_token , tokens )))
def encode_str ( seq_str : str ) -> Tensor :
return Tensor ( list ( map ( ord , seq_str )))
trainer = SelfRewardingTrainer (
transformer ,
finetune_configs = dict (
train_sft_dataset = sft_dataset ,
self_reward_prompt_dataset = prompt_dataset ,
dpo_num_train_steps = 1000
),
tokenizer_decode = decode_tokens ,
tokenizer_encode = encode_str ,
accelerate_kwargs = dict (
cpu = True
)
)
trainer ( overwrite_checkpoints = True )
# checkpoints after each finetuning stage will be saved to ./checkpointsSPIN dapat dilatih sebagai berikut - SPIN juga dapat ditambahkan ke pipeline fine-tuning seperti yang ditunjukkan pada contoh terakhir di readme.
import torch
from self_rewarding_lm_pytorch import (
SPINTrainer ,
create_mock_dataset
)
from x_transformers import TransformerWrapper , Decoder
transformer = TransformerWrapper (
num_tokens = 256 ,
max_seq_len = 1024 ,
attn_layers = Decoder (
dim = 512 ,
depth = 6 ,
heads = 8
)
)
sft_dataset = create_mock_dataset ( 100 , lambda : ( torch . randint ( 0 , 256 , ( 256 ,)), torch . tensor ( 1 )))
spin_trainer = SPINTrainer (
transformer ,
max_seq_len = 16 ,
train_sft_dataset = sft_dataset ,
checkpoint_every = 100 ,
spin_kwargs = dict (
λ = 0.1 ,
),
)
spin_trainer () Katakanlah Anda ingin bereksperimen dengan permintaan hadiah Anda sendiri (selain LLM-as-Judge). Pertama, Anda perlu mengimpor RewardConfig , selanjutnya meneruskannya ke pelatih sebagai reward_prompt_config
# first import
from self_rewarding_lm_pytorch import RewardConfig
# then say you want to try asking the transformer nicely
# reward_regex_template is the string that will be looked for in the LLM response, for parsing out the reward where {{ reward }} is defined as a number
trainer = SelfRewardingTrainer (
transformer ,
...,
self_reward_prompt_config = RewardConfig (
prompt_template = """
Pretty please rate the following user prompt and response
User: {{ prompt }}
Response: {{ response }}
Format your score as follows:
Rating: <rating as integer from 0 - 10>
""" ,
reward_regex_template = """
Rating: {{ reward }}
"""
)
) Terakhir, jika Anda ingin bereksperimen dengan urutan penyesuaian yang sewenang-wenang, Anda juga akan memiliki fleksibilitas tersebut, dengan meneruskan instance FinetuneConfig ke finetune_configs sebagai daftar
mantan. katakanlah Anda ingin melakukan penelitian tentang interleaving SPIN, External Rewarding, dan Self-Rewarding
Ide ini berawal dari Teknium dari saluran perselisihan pribadi.
# import the configs
from self_rewarding_lm_pytorch import (
SFTConfig ,
SelfRewardDPOConfig ,
ExternalRewardDPOConfig ,
SelfPlayConfig ,
)
trainer = SelfRewardingTrainer (
model ,
finetune_configs = [
SFTConfig (...),
SelfPlayConfig (...),
ExternalRewardDPOConfig (...),
SelfRewardDPOConfig (...),
SelfPlayConfig (...),
SelfRewardDPOConfig (...)
],
...
)
trainer ()
# checkpoints after each finetuning stage will be saved to ./checkpoints menggeneralisasi pengambilan sampel sehingga dapat berkembang pada posisi berbeda dalam batch, memperbaiki semua pengambilan sampel yang akan di-batch. juga mengizinkan urutan empuk kiri, jika beberapa orang memiliki transformator dengan posisi relatif yang memungkinkan hal itu
menangani eos
tunjukkan contoh untuk menggunakan prompt hadiah Anda sendiri alih-alih llm-as-judge default
memungkinkan strategi yang berbeda untuk pengambilan sampel pasangan
penghenti awal
urutan sft, spin, dpo self-rewarding, dpo dengan model reward eksternal
mengizinkan fungsi validasi pada hadiah (misalnya hadiah harus berupa bilangan bulat, mengambang, di antara rentang tertentu, dll)
cari tahu cara terbaik untuk menangani impl cache kv yang berbeda, untuk saat ini lakukan saja tanpa itu
tanda lingkungan yang secara otomatis menghapus semua folder pos pemeriksaan
@misc { yuan2024selfrewarding ,
title = { Self-Rewarding Language Models } ,
author = { Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Sainbayar Sukhbaatar and Jing Xu and Jason Weston } ,
year = { 2024 } ,
eprint = { 2401.10020 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @article { Chen2024SelfPlayFC ,
title = { Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models } ,
author = { Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.01335 } ,
url = { https://api.semanticscholar.org/CorpusID:266725672 }
} @article { Rafailov2023DirectPO ,
title = { Direct Preference Optimization: Your Language Model is Secretly a Reward Model } ,
author = { Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.18290 } ,
url = { https://api.semanticscholar.org/CorpusID:258959321 }
} @inproceedings { Guo2024DirectLM ,
title = { Direct Language Model Alignment from Online AI Feedback } ,
author = { Shangmin Guo and Biao Zhang and Tianlin Liu and Tianqi Liu and Misha Khalman and Felipe Llinares and Alexandre Rame and Thomas Mesnard and Yao Zhao and Bilal Piot and Johan Ferret and Mathieu Blondel } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267522951 }
}

