yoloface
1.0.0
YOLOv3 (Anda Hanya Melihat Sekali) adalah algoritma deteksi objek real-time yang canggih. Model yang dipublikasikan mengenali 80 objek berbeda dalam gambar dan video. Untuk lebih jelasnya, Anda dapat merujuk pada makalah ini.
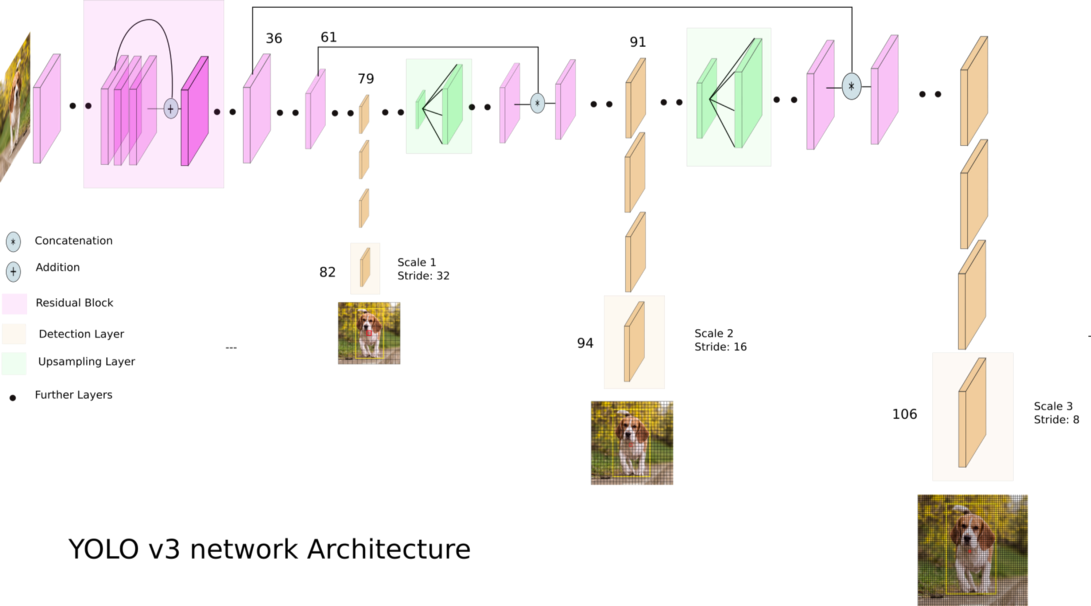
Kredit: Ayoosh Kathuria
Modul OpenCV dnn mendukung inferensi yang berjalan pada model pembelajaran mendalam yang telah dilatih sebelumnya dari kerangka kerja populer seperti TensorFlow, Torch, Darknet, dan Caffe.
Pengembangan proyek ini akan diisolasi dalam lingkungan virtual Python. Hal ini memungkinkan kita bereksperimen dengan versi dependensi yang berbeda.
Ada banyak cara untuk menginstal virtual environment (virtualenv) , lihat Python Virtual Environments: Panduan Primer untuk berbagai platform, namun berikut ada beberapa cara:
$ pip install virtualenv$ pip install --upgrade virtualenvBuat lingkungan virtual Python 3.6 untuk proyek ini dan aktifkan virtualenv:
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activateSelanjutnya, instal dependensi untuk proyek ini:
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface Untuk deteksi wajah, Anda harus mengunduh file bobot YOLOv3 terlatih yang dilatih pada WIDER FACE: kumpulan data Tolok Ukur Deteksi Wajah dari tautan ini dan menempatkannya di direktori model-weights/ .
Jalankan perintah berikut:
masukan gambar
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/masukan video
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/kamera web
$ python yoloface.py --src 1 --output-dir outputs/
Proyek ini dilisensikan di bawah Lisensi MIT - lihat file LICENSE.md untuk lebih jelasnya.


