rtdl revisiting models
1.0.0
Penting
Lihat model DL tabel baru: TabM
arXiv? Paket Python Proyek DL tabel lainnya
Ini adalah implementasi resmi dari makalah "Meninjau Kembali Model Pembelajaran Mendalam untuk Data Tabular".
Singkatnya: model mirip MLP masih menjadi dasar yang bagus, dan FT-Transformer adalah adaptasi baru yang kuat dari arsitektur Transformer untuk masalah data tabular.
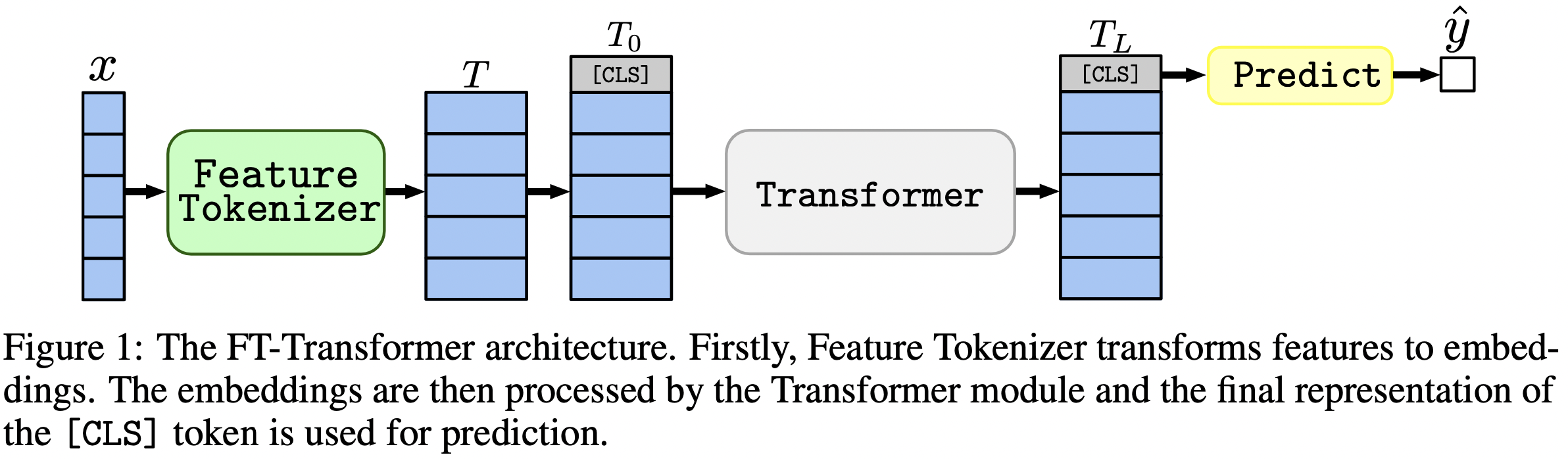
Makalah ini berfokus pada arsitektur untuk masalah data tabular. Hasilnya:
Paket Python di direktori package/ adalah cara yang direkomendasikan untuk menggunakan makalah ini dalam praktik dan untuk pekerjaan di masa mendatang.
Sisa dokumen :
Direktori output/ berisi banyak hasil dan hyperparameter (yang disesuaikan) untuk berbagai model dan kumpulan data yang digunakan dalam makalah ini.
Misalnya, mari kita jelajahi metrik untuk model MLP. Pertama, mari muat laporan (file stats.json ):
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])Sekarang, untuk setiap kumpulan data, mari kita hitung rata-rata skor ujian dari semua benih acak:
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Outputnya sama persis dengan Tabel 2 dari makalah:
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
Pendekatan di atas juga dapat digunakan untuk mengeksplorasi hyperparameter guna mendapatkan intuisi tentang nilai hyperparameter tipikal untuk algoritma yang berbeda. Misalnya, berikut cara menghitung median kecepatan pemelajaran yang disesuaikan untuk model MLP:
Catatan
Untuk beberapa algoritma (misalnya MLP), proyek yang lebih baru menawarkan lebih banyak hasil yang dapat dieksplorasi dengan cara serupa. Misalnya, lihat makalah ini di TabR.
Peringatan
Gunakan pendekatan ini dengan hati-hati. Saat mempelajari nilai hyperparameter:
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536Catatan
Bagian ini panjang. Gunakan fitur "Garis Besar" di GitHub di editor teks Anda untuk mendapatkan ikhtisar bagian ini.
Kode ini disusun sebagai berikut:
bin :ensemble.py melakukan ensemblingtune.py melakukan penyetelan hyperparameteranalysis_gbdt_vs_nn.py menjalankan eksperimencreate_synthetic_data_plots.py membuat plotlib berisi alat umum yang digunakan oleh program di binoutput berisi file konfigurasi (input untuk program di bin ) dan hasil (metrik, konfigurasi yang disetel, dll.)package berisi paket Python untuk makalah ini Instal conda
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsLingkungan ini diperlukan hanya untuk bereksperimen dengan TabNet. Untuk semua kasus lainnya gunakan lingkungan PyTorch.
Petunjuknya sama dengan lingkungan PyTorch (termasuk instalasi PyTorch!), tetapi:
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt lakukan hal berikut:pip install tensorflow-gpu==1.14tensorboard di requirements.txtLISENSI : dengan mengunduh kumpulan data kami, Anda menerima lisensi semua komponennya. Kami tidak menerapkan batasan baru apa pun selain lisensi tersebut. Anda dapat menemukan daftar sumber di bagian "Referensi" makalah kami.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz Bagian ini hanya memberikan perintah khusus dengan sedikit komentar. Setelah menyelesaikan tutorial, kami sarankan untuk memeriksa bagian selanjutnya untuk pemahaman yang lebih baik tentang cara bekerja dengan repositori. Ini juga akan membantu untuk lebih memahami tutorialnya.
Dalam tutorial ini, kami akan mereproduksi hasil MLP pada dataset Perumahan California. Kami akan membahas:
Perhatikan bahwa peluang untuk mendapatkan hasil yang persis sama agak rendah, namun hasilnya tidak jauh berbeda dari kita. Sebelum menjalankan apa pun, buka root repositori dan atur secara eksplisit CUDA_VISIBLE_DEVICES (jika Anda berencana menggunakan GPU):
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0Sebelum kita mulai, mari kita periksa apakah lingkungan telah berhasil dikonfigurasi. Perintah berikut harus melatih satu MLP pada kumpulan data Perumahan California:
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml Hasilnya harus ada di direktori draft/check_environment . Untuk saat ini, isi hasilnya tidak penting.
Konfigurasi kami untuk menyetel MLP pada kumpulan data California Housing terletak di output/california_housing/mlp/tuning/0.toml . Untuk mereproduksi penyetelan, salin konfigurasi kami dan jalankan penyetelan Anda:
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml Hasil tuning Anda akan ditempatkan di output/california_housing/mlp/tuning/reproduced , Anda dapat membandingkannya dengan milik kami: output/california_housing/mlp/tuning/0 . File best.toml berisi konfigurasi terbaik yang akan kami evaluasi di bagian selanjutnya.
Sekarang kita harus mengevaluasi konfigurasi yang disetel dengan 15 seed acak yang berbeda.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done Direktori kami dengan hasil evaluasi terletak tepat di sebelah Anda, yaitu di output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced Hasil Anda akan ditempatkan di output/california_housing/mlp/tuned_reproduced_ensemble , Anda dapat membandingkannya dengan hasil kami: output/california_housing/mlp/tuned_ensemble .
Gunakan pendekatan yang dijelaskan di sini untuk meringkas hasil percobaan yang dilakukan (ubah filter jalur di .glob(...) sesuai: tuned -> tuned_reproduced ).
Langkah serupa dapat dilakukan untuk semua model dan kumpulan data. Proses penyetelan sedikit berbeda dalam kasus pencarian grid: Anda harus menjalankan semua konfigurasi yang diinginkan dan secara manual memilih yang terbaik berdasarkan kinerja validasi . Misalnya, lihat output/epsilon/ft_transformer .
Anda harus menjalankan skrip Python dari root repositori. Kebanyakan program mengharapkan file konfigurasi sebagai satu-satunya argumen. Outputnya akan berupa direktori dengan nama yang sama dengan konfigurasi, tetapi tanpa ekstensi. Konfigurasi ditulis dalam TOML. Daftar kemungkinan argumen untuk program tidak disediakan dan harus disimpulkan dari skrip (biasanya, konfigurasi diwakili dengan variabel args dalam skrip). Jika ingin menggunakan CUDA, Anda harus menyetel variabel lingkungan CUDA_VISIBLE_DEVICES secara eksplisit. Misalnya:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlJika Anda akan menggunakan CUDA sepanjang waktu, Anda dapat menyimpan variabel lingkungan di lingkungan Conda:
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " Opsi -f ( --force ) akan menghapus hasil yang ada dan menjalankan skrip dari awal:
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py mendukung kelanjutan:
python bin/tune.py path/to/config.toml --continuestats.json dan hasil lainnya Untuk semua skrip, stats.json adalah bagian terpenting dari keluaran. Kontennya bervariasi dari satu program ke program lainnya. Ini dapat berisi:
Prediksi untuk rangkaian pelatihan, validasi, dan pengujian biasanya juga disimpan.
Sekarang, Anda mengetahui semua yang Anda perlukan untuk mereproduksi semua hasil dan memperluas repositori ini untuk kebutuhan Anda. Tutorialnya juga harusnya lebih jelas sekarang. Jangan ragu untuk membuka masalah dan mengajukan pertanyaan.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


