video diffusion pytorch
0.7.0
kembang api ini tidak ada
Teks ke video, itu sedang terjadi! Halaman Proyek Resmi
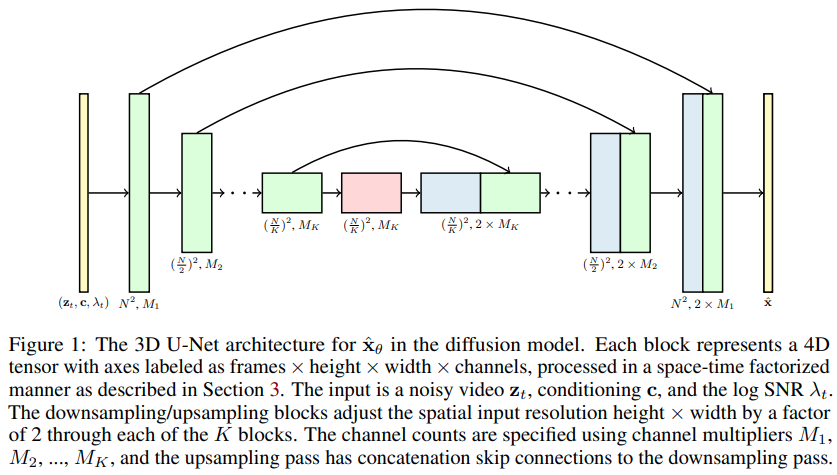
Implementasi Model Difusi Video, makalah baru Jonathan Ho memperluas DDPM ke Pembuatan Video - di Pytorch. Ia menggunakan U-net dengan faktor ruang-waktu khusus, memperluas generasi dari gambar 2D ke video 3D
14k untuk mnist yang sulit bergerak (berkonvergensi jauh lebih cepat dan lebih baik daripada NUWA) - wip

Eksperimen di atas hanya mungkin dilakukan berkat sumber daya yang disediakan oleh Stability.ai
Setiap perkembangan baru untuk sintesis teks-ke-video akan dipusatkan di Imagen-pytorch
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)Untuk pengkondisian pada teks, mereka memperoleh penyematan teks dengan terlebih dahulu meneruskan teks yang diberi token melalui BERT-large. Maka Anda hanya perlu melatihnya seperti itu
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)Anda juga dapat langsung meneruskan deskripsi video sebagai string, jika Anda berencana menggunakan BERT-base untuk pengkondisian teks
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) Repositori ini juga berisi kelas Trainer yang berguna untuk pelatihan pada folder gifs . Setiap gif harus memiliki dimensi image_size dan num_frames yang benar.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () Contoh video (sebagai file gif ) akan disimpan ke ./results secara berkala, begitu pula parameter model difusi.
Salah satu klaim dalam makalah ini adalah bahwa dengan melakukan perhatian ruang-waktu yang terfaktor, seseorang dapat memaksa jaringan untuk hadir pada saat ini untuk melatih gambar dan video secara bersamaan, sehingga memberikan hasil yang lebih baik.
Tidak jelas bagaimana mereka mencapai hal ini, tapi saya terus menebak.
Untuk menarik perhatian pada momen saat ini untuk persentase tertentu dari sampel video batch, cukup berikan prob_focus_present = <prob> pada metode difusi maju
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()Jika Anda memiliki gagasan yang lebih baik bagaimana hal ini dilakukan, buka saja masalah github.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

