nano neuron
1.0.0
7 fungsi JavaScript sederhana yang akan memberi Anda gambaran tentang bagaimana mesin sebenarnya bisa "belajar".
Dalam bahasa lain: Русский, Português
Anda mungkin juga tertarik? Eksperimen Pembelajaran Mesin Interaktif
NanoNeuron adalah versi konsep Neuron yang terlalu disederhanakan dari Neural Networks. NanoNeuron dilatih untuk mengubah nilai suhu dari Celsius ke Fahrenheit.
Contoh kode NanoNeuron.js berisi 7 fungsi JavaScript sederhana (yang menyentuh prediksi model, penghitungan biaya, propagasi maju/mundur, dan pelatihan) yang akan memberi Anda gambaran tentang bagaimana mesin sebenarnya dapat "belajar". Tidak ada perpustakaan pihak ketiga, tidak ada kumpulan data atau ketergantungan eksternal, hanya fungsi JavaScript murni dan sederhana.
☝?Fungsi-fungsi ini BUKAN merupakan panduan lengkap untuk pembelajaran mesin. Banyak konsep pembelajaran mesin yang dilewati dan disederhanakan secara berlebihan! Penyederhanaan ini dilakukan dengan tujuan untuk memberikan pembaca pemahaman dan perasaan yang benar-benar mendasar tentang bagaimana mesin dapat belajar dan pada akhirnya memungkinkan pembaca untuk menyadari bahwa ini bukanlah "machine learning MAGIC" melainkan "machine learning MATH"?.
Anda mungkin pernah mendengar tentang Neuron dalam konteks Jaringan Syaraf Tiruan. NanoNeuron hanya itu tetapi lebih sederhana dan kami akan mengimplementasikannya dari awal. Untuk alasan kesederhanaan kami bahkan tidak akan membangun jaringan di NanoNeurons. Kami akan membuat semuanya bekerja dengan sendirinya, melakukan beberapa prediksi ajaib untuk kami. Yaitu, kami akan mengajarkan NanoNeuron tunggal ini untuk mengubah (memprediksi) suhu dari Celsius ke Fahrenheit.
Rumus untuk mengubah Celsius ke Fahrenheit adalah sebagai berikut:
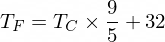
Tapi untuk saat ini NanoNeuron kita belum mengetahuinya...
Mari terapkan fungsi model NanoNeuron kita. Ini mengimplementasikan ketergantungan linier dasar antara x dan y yang terlihat seperti y = w * x + b . Sederhananya NanoNeuron kita adalah "anak" di "sekolah" yang diajari menggambar garis lurus dalam koordinat XY .
Variabel w , b adalah parameter model. NanoNeuron hanya mengetahui dua parameter fungsi linier ini. Parameter ini adalah sesuatu yang akan "dipelajari" oleh NanoNeuron selama proses pelatihan.
Satu-satunya hal yang dapat dilakukan NanoNeuron adalah meniru ketergantungan linier. Dalam metode predict() nya, ia menerima beberapa masukan x dan memprediksi keluaran y . Tidak ada keajaiban di sini.
function NanoNeuron ( w , b ) {
this . w = w ;
this . b = b ;
this . predict = ( x ) => {
return x * this . w + this . b ;
}
}(...tunggu... regresi linier ya?) ?
Nilai suhu dalam Celsius dapat dikonversi ke Fahrenheit menggunakan rumus berikut: f = 1.8 * c + 32 , dengan c adalah suhu dalam Celsius dan f adalah suhu yang dihitung dalam Fahrenheit.
function celsiusToFahrenheit ( c ) {
const w = 1.8 ;
const b = 32 ;
const f = c * w + b ;
return f ;
} ; Pada akhirnya kami ingin mengajarkan NanoNeuron kami untuk meniru fungsi ini (untuk mempelajari bahwa w = 1.8 dan b = 32 ) tanpa mengetahui parameter ini sebelumnya.
Seperti inilah tampilan fungsi konversi Celsius ke Fahrenheit:
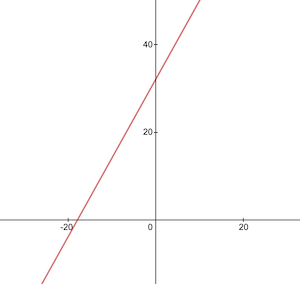
Sebelum pelatihan kita perlu membuat kumpulan data pelatihan dan pengujian berdasarkan fungsi celsiusToFahrenheit() . Kumpulan data terdiri dari pasangan nilai masukan dan nilai keluaran yang diberi label dengan benar.
Dalam kehidupan nyata, dalam sebagian besar kasus, data ini dikumpulkan, bukan dihasilkan. Misalnya, kita mungkin memiliki sekumpulan gambar angka yang digambar tangan dan kumpulan angka terkait yang menjelaskan angka apa yang tertulis pada setiap gambar.
Kami akan menggunakan data contoh PELATIHAN untuk melatih NanoNeuron kami. Sebelum NanoNeuron kita tumbuh dan dapat mengambil keputusan sendiri, kita perlu mengajarinya apa yang benar dan apa yang salah menggunakan contoh pelatihan.
Kami akan menggunakan contoh TEST untuk mengevaluasi seberapa baik kinerja NanoNeuron kami pada data yang tidak dilihatnya selama pelatihan. Di sinilah kita bisa melihat bahwa “anak” kita sudah tumbuh dan bisa mengambil keputusan sendiri.
function generateDataSets ( ) {
// xTrain -> [0, 1, 2, ...],
// yTrain -> [32, 33.8, 35.6, ...]
const xTrain = [ ] ;
const yTrain = [ ] ;
for ( let x = 0 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTrain . push ( x ) ;
yTrain . push ( y ) ;
}
// xTest -> [0.5, 1.5, 2.5, ...]
// yTest -> [32.9, 34.7, 36.5, ...]
const xTest = [ ] ;
const yTest = [ ] ;
// By starting from 0.5 and using the same step of 1 as we have used for training set
// we make sure that test set has different data comparing to training set.
for ( let x = 0.5 ; x < 100 ; x += 1 ) {
const y = celsiusToFahrenheit ( x ) ;
xTest . push ( x ) ;
yTest . push ( y ) ;
}
return [ xTrain , yTrain , xTest , yTest ] ;
} Kita perlu memiliki beberapa metrik yang akan menunjukkan seberapa dekat prediksi model kita dengan nilai yang benar. Perhitungan biaya (kesalahan) antara nilai keluaran y dan prediction yang benar, yang dibuat oleh NanoNeuron kita, akan dilakukan dengan menggunakan rumus berikut:
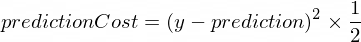
Ini adalah perbedaan sederhana antara dua nilai. Semakin dekat nilainya satu sama lain, semakin kecil perbedaannya. Kita menggunakan pangkat 2 di sini hanya untuk menghilangkan bilangan negatif sehingga (1 - 2) ^ 2 sama dengan (2 - 1) ^ 2 . Pembagian dengan 2 dilakukan hanya untuk menyederhanakan rumus propagasi mundur (lihat di bawah).
Fungsi biaya dalam hal ini akan sesederhana:
function predictionCost ( y , prediction ) {
return ( y - prediction ) ** 2 / 2 ; // i.e. -> 235.6
} Melakukan propagasi maju berarti melakukan prediksi untuk semua contoh pelatihan dari kumpulan data xTrain dan yTrain dan menghitung biaya rata-rata dari prediksi tersebut selama prosesnya.
Kita biarkan NanoNeuron mengutarakan pendapatnya, pada saat ini, dengan membiarkannya menebak cara mengubah suhu. Mungkin ada kesalahan bodoh di sini. Biaya rata-rata akan menunjukkan betapa salahnya model kita saat ini. Nilai biaya ini sangat penting karena mengubah parameter NanoNeuron w dan b , dan dengan melakukan propagasi maju lagi; kita akan dapat mengevaluasi apakah NanoNeuron kita menjadi lebih pintar atau tidak setelah parameter ini berubah.
Biaya rata-rata akan dihitung menggunakan rumus berikut:
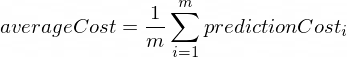
Dimana m adalah sejumlah contoh pelatihan (dalam kasus kami: 100 ).
Inilah cara kami mengimplementasikannya dalam kode:
function forwardPropagation ( model , xTrain , yTrain ) {
const m = xTrain . length ;
const predictions = [ ] ;
let cost = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
const prediction = nanoNeuron . predict ( xTrain [ i ] ) ;
cost += predictionCost ( yTrain [ i ] , prediction ) ;
predictions . push ( prediction ) ;
}
// We are interested in average cost.
cost /= m ;
return [ predictions , cost ] ;
}Ketika kita mengetahui seberapa benar atau salah prediksi NanoNeuron kita (berdasarkan biaya rata-rata saat ini), apa yang harus kita lakukan untuk membuat prediksi tersebut lebih tepat?
Propagasi mundur memberi kita jawaban atas pertanyaan ini. Propagasi mundur adalah proses mengevaluasi biaya prediksi dan menyesuaikan parameter NanoNeuron w dan b agar prediksi selanjutnya dan yang akan datang lebih tepat.
Di sinilah pembelajaran mesin tampak seperti keajaiban ?♂️. Konsep kuncinya di sini adalah turunan yang menunjukkan langkah apa yang harus diambil untuk mendekati fungsi biaya minimum.
Ingat, menemukan fungsi biaya minimum adalah tujuan akhir dari proses pelatihan. Jika kita menemukan nilai w dan b sedemikian rupa sehingga fungsi biaya rata-rata kita menjadi kecil, itu berarti model NanoNeuron memberikan prediksi yang sangat baik dan tepat.
Derivatif adalah topik besar dan terpisah yang tidak akan kami bahas dalam artikel ini. MathIsFun adalah sumber yang bagus untuk mendapatkan pemahaman dasar tentangnya.
Satu hal tentang turunan yang akan membantu Anda memahami cara kerja perambatan mundur adalah bahwa turunan, menurut maknanya, adalah garis singgung kurva fungsi yang mengarah ke arah minimum fungsi.
Sumber gambar: MathIsFun
Misalnya, pada plot di atas, Anda dapat melihat bahwa jika kita berada di titik (x=2, y=4) maka kemiringannya menyuruh kita ke left dan down untuk mencapai fungsi minimum. Perhatikan juga bahwa semakin besar kemiringannya, semakin cepat kita harus bergerak ke minimum.
Turunan dari fungsi averageCost untuk parameter w dan b terlihat seperti ini:
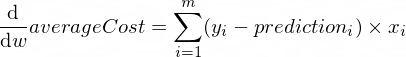
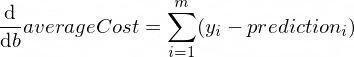
Dimana m adalah sejumlah contoh pelatihan (dalam kasus kami: 100 ).
Anda dapat membaca lebih lanjut tentang aturan turunan dan cara mendapatkan turunan fungsi kompleks di sini.
function backwardPropagation ( predictions , xTrain , yTrain ) {
const m = xTrain . length ;
// At the beginning we don't know in which way our parameters 'w' and 'b' need to be changed.
// Therefore we're setting up the changing steps for each parameters to 0.
let dW = 0 ;
let dB = 0 ;
for ( let i = 0 ; i < m ; i += 1 ) {
dW += ( yTrain [ i ] - predictions [ i ] ) * xTrain [ i ] ;
dB += yTrain [ i ] - predictions [ i ] ;
}
// We're interested in average deltas for each params.
dW /= m ;
dB /= m ;
return [ dW , dB ] ;
} Sekarang kita tahu bagaimana mengevaluasi kebenaran model kita untuk semua contoh set pelatihan ( propagasi maju ). Kami juga mengetahui cara melakukan sedikit penyesuaian pada parameter w dan b model NanoNeuron ( propagasi mundur ). Namun masalahnya adalah jika kita menjalankan propagasi maju dan kemudian propagasi mundur hanya sekali, model kita tidak akan cukup mempelajari hukum/tren apa pun dari data pelatihan. Anda dapat membandingkannya dengan menghadiri satu hari sekolah dasar untuk anak tersebut. Dia harus pergi ke sekolah tidak hanya sekali tetapi hari demi hari dan tahun demi tahun untuk mempelajari sesuatu.
Jadi kita perlu mengulangi propagasi maju dan mundur untuk model kita berkali-kali. Itulah tepatnya yang dilakukan fungsi trainModel() . Ini seperti "guru" untuk model NanoNeuron kami:
epochs ) dengan model NanoNeuron kami yang sedikit bodoh dan mencoba untuk melatih/mengajarkannya,xTrain dan yTrain ) untuk pelatihan,alpha Beberapa kata tentang kecepatan pembelajaran alpha . Ini hanyalah pengali untuk nilai dW dan dB yang telah kita hitung selama propagasi mundur. Jadi, turunan mengarahkan kita ke arah yang perlu kita ambil untuk mencari fungsi biaya minimum (tanda dW dan dB ) dan juga menunjukkan seberapa cepat kita harus menuju ke arah tersebut (nilai absolut dW dan dB ). Sekarang kita perlu mengalikan ukuran langkah tersebut ke alpha hanya untuk menyesuaikan gerakan kita ke minimum, lebih cepat atau lebih lambat. Terkadang jika kita menggunakan nilai yang besar untuk alpha , kita mungkin melompati nilai minimum dan tidak pernah menemukannya.
Analoginya dengan guru adalah semakin keras dia mendorong "anak nano" kita, semakin cepat "anak nano" kita akan belajar tetapi jika guru mendorong terlalu keras, "anak" tersebut akan mengalami gangguan saraf dan menang. tidak bisa belajar apa pun?.
Inilah cara kita memperbarui parameter w dan b model kita:
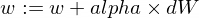
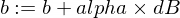
Dan inilah fungsi pelatih kami:
function trainModel ( { model , epochs , alpha , xTrain , yTrain } ) {
// The is the history array of how NanoNeuron learns.
const costHistory = [ ] ;
// Let's start counting epochs.
for ( let epoch = 0 ; epoch < epochs ; epoch += 1 ) {
// Forward propagation.
const [ predictions , cost ] = forwardPropagation ( model , xTrain , yTrain ) ;
costHistory . push ( cost ) ;
// Backward propagation.
const [ dW , dB ] = backwardPropagation ( predictions , xTrain , yTrain ) ;
// Adjust our NanoNeuron parameters to increase accuracy of our model predictions.
nanoNeuron . w += alpha * dW ;
nanoNeuron . b += alpha * dB ;
}
return costHistory ;
}Sekarang mari kita gunakan fungsi yang telah kita buat di atas.
Mari kita buat contoh model NanoNeuron kita. Saat ini NanoNeuron tidak mengetahui nilai apa yang harus ditetapkan untuk parameter w dan b . Jadi mari kita atur w dan b secara acak.
const w = Math . random ( ) ; // i.e. -> 0.9492
const b = Math . random ( ) ; // i.e. -> 0.4570
const nanoNeuron = new NanoNeuron ( w , b ) ;Hasilkan kumpulan data pelatihan dan pengujian.
const [ xTrain , yTrain , xTest , yTest ] = generateDataSets ( ) ; Mari kita latih model dengan langkah tambahan kecil ( 0.0005 ) untuk 70000 epoch. Anda dapat bermain-main dengan parameter ini, parameter tersebut ditentukan secara empiris.
const epochs = 70000 ;
const alpha = 0.0005 ;
const trainingCostHistory = trainModel ( { model : nanoNeuron , epochs , alpha , xTrain , yTrain } ) ;Mari kita periksa bagaimana fungsi biaya berubah selama pelatihan. Kami berharap biaya setelah pelatihan akan jauh lebih rendah dibandingkan sebelumnya. Ini berarti NanoNeuron menjadi lebih pintar. Hal sebaliknya juga mungkin terjadi.
console . log ( 'Cost before the training:' , trainingCostHistory [ 0 ] ) ; // i.e. -> 4694.3335043
console . log ( 'Cost after the training:' , trainingCostHistory [ epochs - 1 ] ) ; // i.e. -> 0.0000024 Beginilah perubahan biaya pelatihan dari waktu ke waktu. Pada sumbu x adalah nomor epoch x1000.
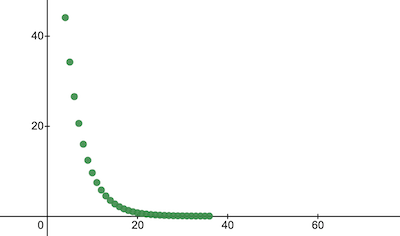
Mari kita lihat parameter NanoNeuron untuk melihat apa yang telah dipelajarinya. Kami berharap parameter NanoNeuron w dan b serupa dengan yang kami miliki di fungsi celsiusToFahrenheit() ( w = 1.8 dan b = 32 ) karena NanoNeuron kami mencoba menirunya.
console . log ( 'NanoNeuron parameters:' , { w : nanoNeuron . w , b : nanoNeuron . b } ) ; // i.e. -> {w: 1.8, b: 31.99}Evaluasi akurasi model untuk kumpulan data pengujian untuk melihat seberapa baik NanoNeuron kami menangani prediksi data baru yang tidak diketahui. Biaya prediksi pada set pengujian diperkirakan mendekati biaya pelatihan. Ini berarti NanoNeuron kami bekerja dengan baik pada data yang dikenal dan tidak diketahui.
[ testPredictions , testCost ] = forwardPropagation ( nanoNeuron , xTest , yTest ) ;
console . log ( 'Cost on new testing data:' , testCost ) ; // i.e. -> 0.0000023Sekarang, karena kita melihat bahwa "anak" NanoNeuron kita telah berkinerja baik di "sekolah" selama pelatihan dan dia dapat mengubah suhu Celsius ke Fahrenheit dengan benar, bahkan untuk data yang belum dilihatnya, kita dapat menyebutnya "pintar" dan menanyakan beberapa pertanyaan padanya. Ini adalah tujuan akhir dari keseluruhan proses pelatihan.
const tempInCelsius = 70 ;
const customPrediction = nanoNeuron . predict ( tempInCelsius ) ;
console . log ( `NanoNeuron "thinks" that ${ tempInCelsius } °C in Fahrenheit is:` , customPrediction ) ; // -> 158.0002
console . log ( 'Correct answer is:' , celsiusToFahrenheit ( tempInCelsius ) ) ; // -> 158Sangat dekat! Sebagai kita semua manusia, NanoNeuron kita bagus tapi tidak ideal :)
Selamat belajar untuk Anda!
Anda dapat mengkloning repositori dan menjalankannya secara lokal:
git clone https://github.com/trekhleb/nano-neuron.git
cd nano-neuronnode ./NanoNeuron.jsKonsep pembelajaran mesin berikut dilewati dan disederhanakan untuk menyederhanakan penjelasan.
Pelatihan/pengujian pemisahan kumpulan data
Biasanya Anda memiliki satu set data yang besar. Bergantung pada jumlah contoh dalam set tersebut, Anda mungkin ingin membaginya dalam proporsi 70/30 untuk set pelatihan/pengujian. Data dalam kumpulan harus diacak secara acak sebelum dipecah. Jika jumlah contohnya besar (yaitu jutaan) maka pemisahan mungkin terjadi dalam proporsi yang mendekati 90/10 atau 95/5 untuk kumpulan data pelatihan/pengujian.
Jaringan memberikan kekuatan
Biasanya Anda tidak akan memperhatikan penggunaan hanya satu neuron yang berdiri sendiri. Kekuatannya ada pada jaringan neuron tersebut. Jaringan mungkin mempelajari fitur-fitur yang jauh lebih kompleks. NanoNeuron sendiri lebih mirip regresi linier sederhana daripada jaringan saraf.
Normalisasi masukan
Sebelum pelatihan, akan lebih baik untuk menormalkan nilai input.
Implementasi vektor
Untuk jaringan, penghitungan vektorisasi (matriks) bekerja jauh lebih cepat dibandingkan for . Biasanya propagasi maju/mundur bekerja lebih cepat jika diimplementasikan dalam bentuk vektor dan dihitung menggunakan, misalnya, pustaka Numpy Python.
Minimum fungsi biaya
Fungsi biaya yang kami gunakan dalam contoh ini terlalu disederhanakan. Itu harus memiliki komponen logaritmik. Mengubah fungsi biaya juga akan mengubah turunannya sehingga langkah propagasi mundur juga akan menggunakan rumus yang berbeda.
Fungsi aktivasi
Biasanya keluaran dari sebuah neuron harus dilewatkan melalui fungsi aktivasi seperti Sigmoid atau ReLU atau lainnya.


