PALM E
0.0.4

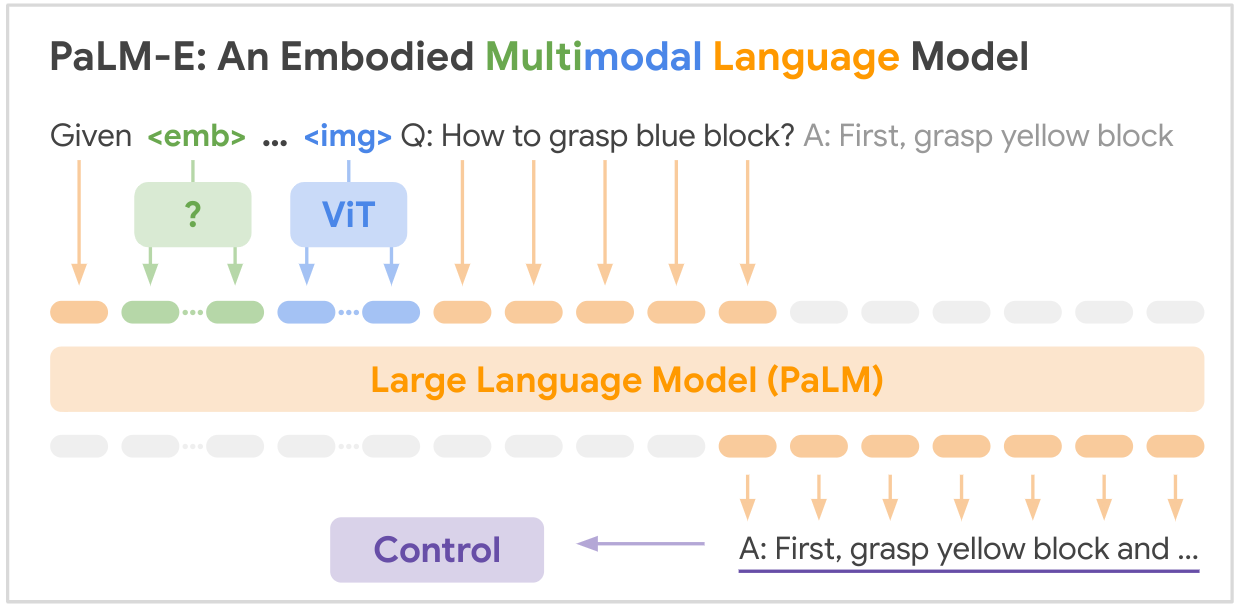
Ini adalah implementasi open source dari model dasar multi-modalitas SOTA "PALM-E: An Embodied Multimodal Language Model" dari Google, PALM-E adalah model multimodal tunggal yang besar, yang dapat menangani berbagai tugas penalaran yang diwujudkan, mulai dari berbagai modalitas observasi, pada berbagai perwujudan, dan lebih jauh lagi, menunjukkan transfer positif: model ini mendapat manfaat dari beragam pelatihan bersama di domain bahasa, visi, dan bahasa visual berskala internet.
PAPER LINK: PaLM-E: Model Bahasa Multimodal yang Terwujud
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
Berikut adalah tabel ringkasan kumpulan data utama yang disebutkan dalam makalah:
| Kumpulan data | Tugas | Ukuran | Link |
|---|---|---|---|
| MEMADATKAN | Perencanaan manipulasi robot, VQA | 96.000 adegan | Kumpulan data khusus |
| Tabel Bahasa | Perencanaan manipulasi robot | Kumpulan data khusus | Link |
| Manipulasi Seluler | Navigasi robot dan perencanaan manipulasi, VQA | 2912 urutan | Berdasarkan kumpulan data SayCan |
| WebLI | Pengambilan gambar-teks | 66 juta pasangan keterangan gambar | Link |
| VQAv2 | Menjawab pertanyaan visual | 1,1 juta pertanyaan tentang gambar COCO | Link |
| Oke-VQA | Menjawab pertanyaan visual membutuhkan pengetahuan eksternal | 14.031 pertanyaan tentang gambar COCO | Link |
| KELAPA | Keterangan gambar | 330 ribu gambar dengan teks | Link |
| Wikipedia | Korpus teks | T/A | Link |
Kumpulan data robotika utama dikumpulkan secara khusus untuk pekerjaan ini, sedangkan kumpulan data bahasa visi yang lebih besar (WebLI, VQAv2, OK-VQA, COCO) adalah tolok ukur standar di bidang tersebut. Kumpulan datanya berkisar dari puluhan ribu contoh untuk domain robotika hingga puluhan juta untuk data bahasa visi berskala internet.
Kecemerlangan Anda dibutuhkan! Bergabunglah bersama kami, dan bersama-sama, mari jadikan PALM-E lebih menakjubkan:
? Perbaikan,? penyempurnaan, dokumen, atau ide – semuanya diterima! Mari kita bersama-sama membentuk masa depan AI.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

