meshgpt pytorch
1.8.1
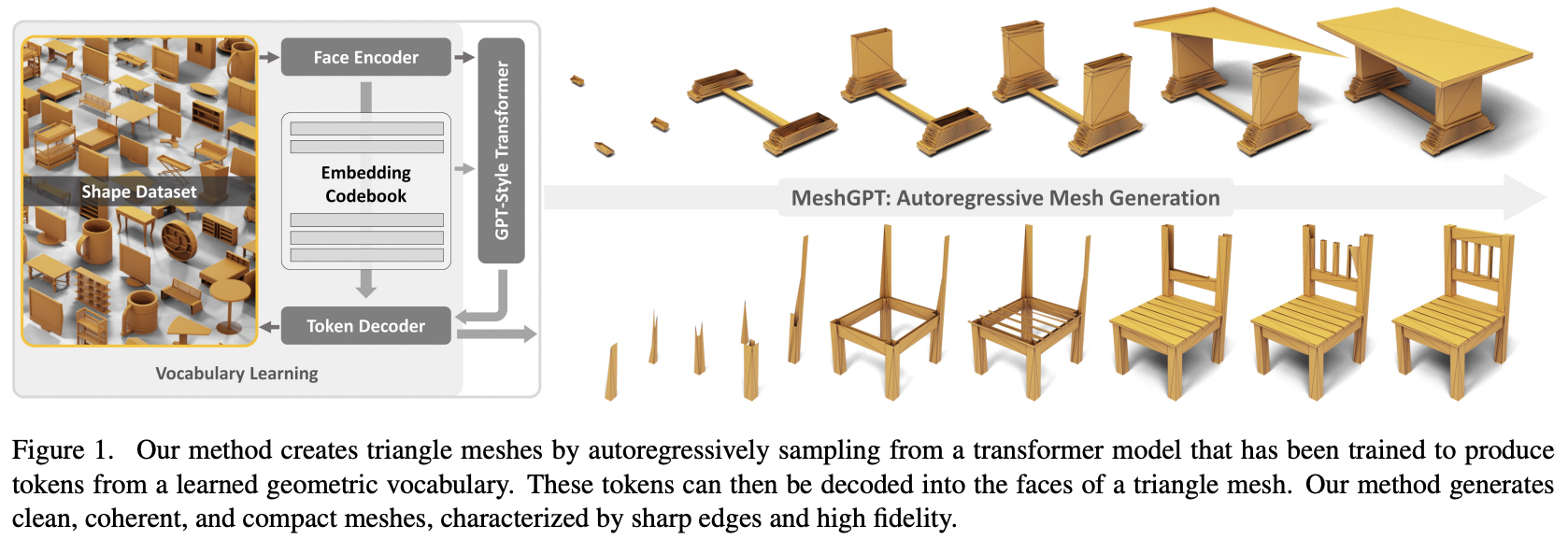
Implementasi MeshGPT, pembuatan SOTA Mesh menggunakan Attention, di Pytorch
Juga akan menambahkan pengondisian teks, untuk aset teks-ke-3d
Silakan bergabung jika Anda tertarik berkolaborasi dengan orang lain untuk mereplikasi karya ini
Pembaruan: Marcus telah melatih dan mengunggah model kerja ke ? Wajah berpelukan!
StabilityAI, Program Hibah AI Sumber Terbuka A16Z, dan? Huggingface atas sponsor yang murah hati, serta sponsor saya yang lain, yang telah memberi saya kebebasan untuk melakukan penelitian kecerdasan buatan terkini secara open source
Einops karena membuat hidupku mudah
Marcus untuk peninjauan kode awal (menunjukkan beberapa fitur turunan yang hilang) serta menjalankan eksperimen end-to-end pertama yang berhasil
Marcus untuk pelatihan pertama yang berhasil mengenai kumpulan bentuk yang dikondisikan pada label
Quexi Ma untuk menemukan banyak bug dengan penanganan eos otomatis
Yingtian untuk menemukan bug dengan pengaburan gaussian pada posisi untuk perataan label spasial
Marcus sekali lagi menjalankan eksperimen untuk memvalidasi kemungkinan memperluas sistem dari segitiga ke segi empat
Marcus yang telah mengidentifikasi masalah pengkondisian teks dan menjalankan semua eksperimen yang menyebabkan masalah tersebut terselesaikan
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset Untuk sintesis bentuk 3d yang dikondisikan teks, cukup setel condition_on_text = True pada MeshTransformer Anda, lalu masukkan daftar deskripsi Anda sebagai argumen kata kunci texts
mantan.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) Jika Anda ingin membuat tokenisasi jerat, untuk digunakan dalam transformator multimodal Anda, cukup aktifkan .tokenize pada autoencoder Anda (atau metode yang sama pada instance pelatih autoencoder untuk model yang dihaluskan secara eksponensial)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) Di root proyek, jalankan
$ cp .env.sample .envautoencoder
face_edges secara otomatis langsung dari wajah dan simpul transformator
pembungkus pelatih dengan akselerasi hf
pengkondisian teks menggunakan perpustakaan CFG sendiri
trafo hierarkis (menggunakan trafo RQ)
perbaiki caching di lapisan gateloop sederhana di repo lain
perhatian lokal
memperbaiki kv caching untuk trafo hierarki dua tahap - 7x lebih cepat sekarang, dan lebih cepat dari trafo non-hierarki asli
memperbaiki caching untuk lapisan gateloop
memungkinkan penyesuaian dimensi model jaringan perhatian halus vs kasar
mencari tahu apakah autoencoder benar-benar diperlukan - perlu, ablasi ada di kertas
membuat transformator menjadi efisien
opsi decoding spekulatif
menghabiskan satu hari untuk dokumentasi
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

