algebraic nnhw
1.0.0
Repositori ini berisi kode sumber untuk arsitektur perangkat keras ML yang memerlukan hampir setengah jumlah unit pengali untuk mencapai performa yang sama, dengan mengeksekusi algoritme produk dalam alternatif yang menukar hampir separuh perkalian dengan penambahan bitwidth rendah yang murah, sambil tetap menghasilkan keluaran yang identik seperti produk dalam konvensional. Hal ini meningkatkan throughput teoritis dan batas efisiensi komputasi akselerator ML. Simak publikasi jurnal berikut ini untuk selengkapnya:
TE Pogue dan N. Nicolici, "Algoritma dan Arsitektur Produk Dalam Cepat untuk Akselerator Jaringan Syaraf Dalam," dalam Transaksi IEEE di Komputer, vol. 73, tidak. 2, hal. 495-509, Februari 2024, doi: 10.1109/TC.2023.3334140.
URL artikel: https://ieeexplore.ieee.org/document/10323219
Versi akses terbuka: https://arxiv.org/abs/2311.12224
Abstrak: Kami memperkenalkan algoritma baru yang disebut Free-pipeline Fast Inner Product (FFIP) dan arsitektur perangkat kerasnya yang meningkatkan algoritma produk dalam cepat (FIP) yang belum dieksplorasi yang diusulkan oleh Winograd pada tahun 1968. Berbeda dengan algoritma pemfilteran minimal Winograd yang tidak terkait untuk lapisan konvolusional, FIP berlaku untuk semua lapisan model pembelajaran mesin (ML) yang terutama dapat terdekomposisi menjadi perkalian matriks, termasuk lapisan yang terhubung penuh, konvolusional, berulang, dan perhatian/transformator. Kami menerapkan FIP untuk pertama kalinya dalam akselerator ML, lalu menyajikan algoritme FFIP dan arsitektur umum kami yang secara inheren meningkatkan frekuensi jam FIP dan, sebagai konsekuensinya, throughput dengan biaya perangkat keras yang serupa. Terakhir, kami menyumbangkan pengoptimalan khusus ML untuk algoritma dan arsitektur FIP dan FFIP. Kami menunjukkan bahwa FFIP dapat diintegrasikan secara mulus ke dalam akselerator ML larik sistolik titik tetap tradisional untuk mencapai throughput yang sama dengan setengah jumlah akumulasi perkalian (MAC), atau dapat menggandakan ukuran larik sistolik maksimum yang dapat ditampung pada perangkat dengan anggaran perangkat keras yang tetap. Implementasi FFIP kami untuk model ML non-sparse dengan input titik tetap 8 hingga 16-bit mencapai throughput dan efisiensi komputasi yang lebih tinggi dibandingkan solusi terbaik di kelasnya sebelumnya pada jenis platform komputasi yang sama.
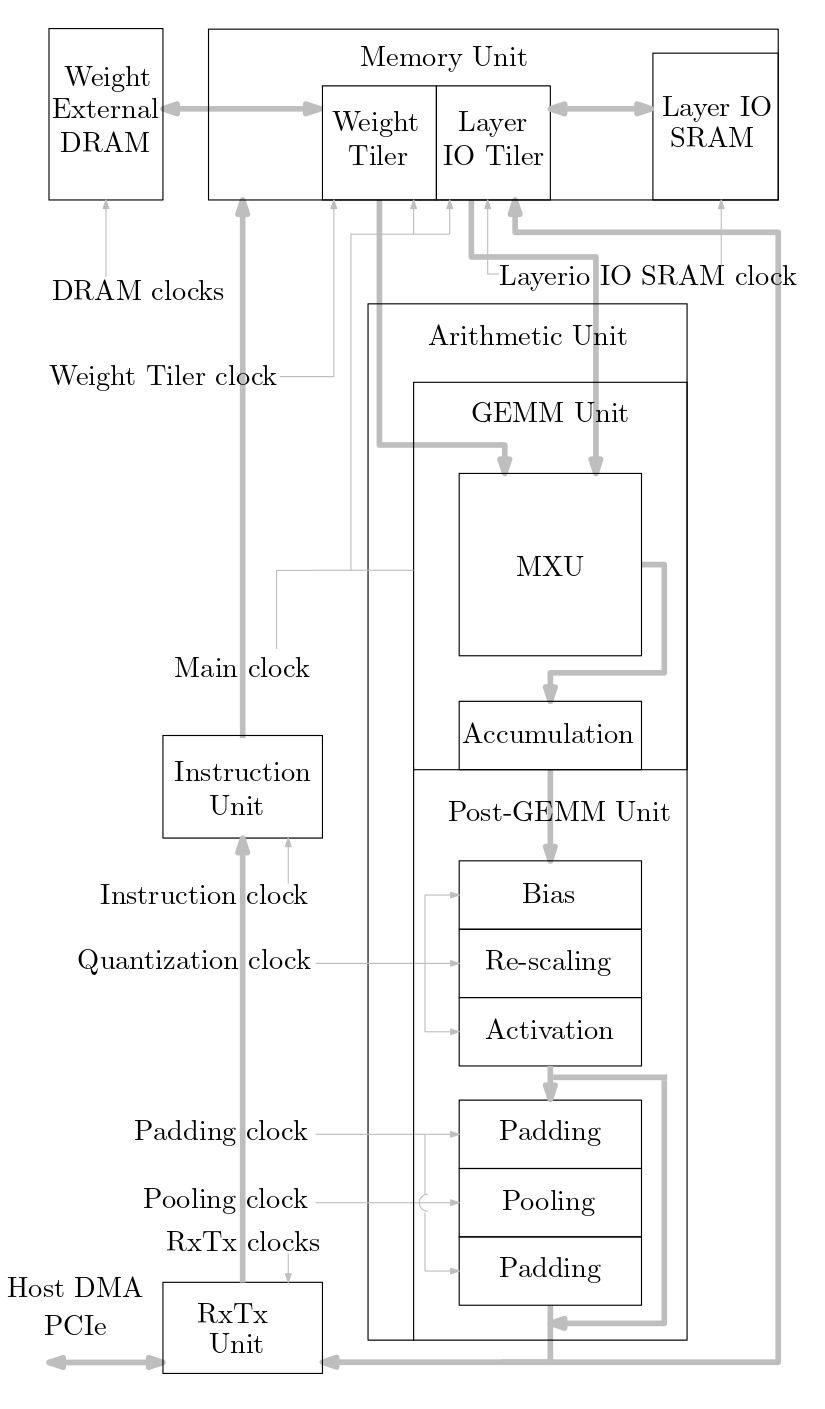
Diagram berikut menunjukkan gambaran umum sistem akselerator ML yang diterapkan dalam kode sumber ini:
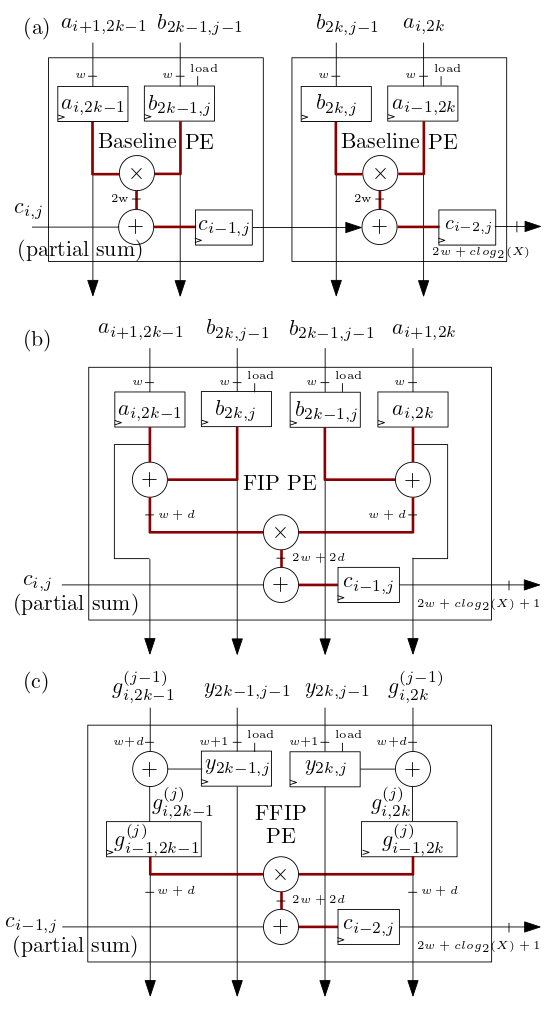
Array sistolik FIP dan FFIP/elemen pemrosesan (PE) MXU yang ditunjukkan di bawah pada (b) dan (c) mengimplementasikan algoritme hasil kali dalam FIP dan FFIP dan masing-masing secara individual memberikan daya komputasi efektif yang sama dengan dua PE dasar yang ditunjukkan pada ( a) gabungan yang mengimplementasikan produk dalam dasar seperti pada akselerator ML array sistolik sebelumnya:
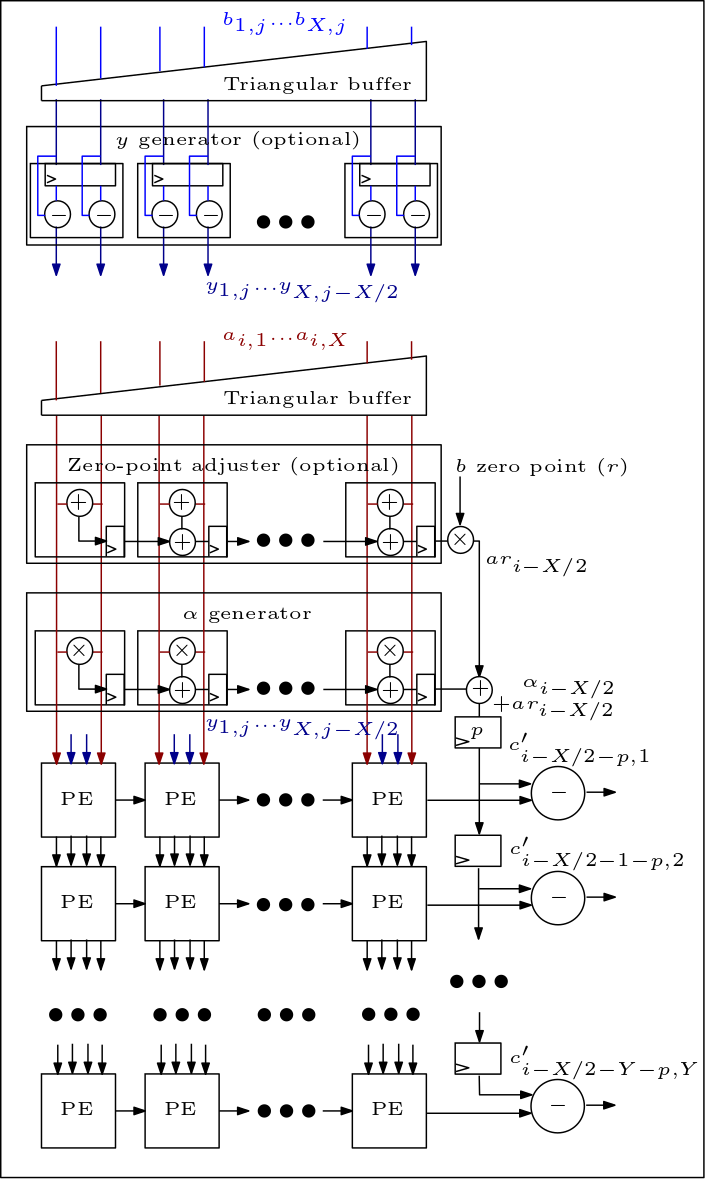
Berikut ini adalah diagram MXU/array sistolik dan menunjukkan bagaimana PE terhubung:
Organisasi kode sumbernya adalah sebagai berikut:
File rtl/top/define.svh dan rtl/top/pkg.sv berisi sejumlah parameter yang dapat dikonfigurasi seperti FIP_METHOD di define.svh yang mendefinisikan tipe array sistolik (baseline, FIP, atau FFIP), SZI dan SZJ yang mendefinisikan tinggi/lebar larik sistolik, dan LAYERIO_WIDTH/WEIGHT_WIDTH yang menentukan bitwidth masukan.
Direktori rtl/arith mencakup mxu.sv dan mac_array.sv yang berisi RTL untuk arsitektur array sistolik baseline, FIP, dan FFIP (tergantung pada nilai parameter FIP_METHOD).


