Repositori terdiri dari VQ-VAE yang diimplementasikan di Pytorch dan dilatih pada dataset MNIST.
VQ-VAE mengikuti konsep dasar yang sama seperti di balik variasional auto-encoder (VAE). VQ-VAE menggunakan embeddings laten diskrit untuk encoder otomatis variasional , yaitu setiap dimensi z (vektor laten) adalah bilangan bulat diskrit, alih-alih distribusi normal kontinu yang umumnya digunakan saat mengkode input.
VAE terdiri dari 3 bagian:
Nah, Anda mungkin bertanya tentang perbedaan yang dibawa VQ-VAE ke meja. Mari kita daftarkan mereka:
Banyak objek dunia nyata yang penting diskrit. Misalnya dalam gambar kita mungkin memiliki kategori seperti "kucing", "mobil", dll. Dan mungkin tidak masuk akal untuk menginterpolasi antara kategori -kategori ini. Representasi diskrit juga lebih mudah dimodelkan.
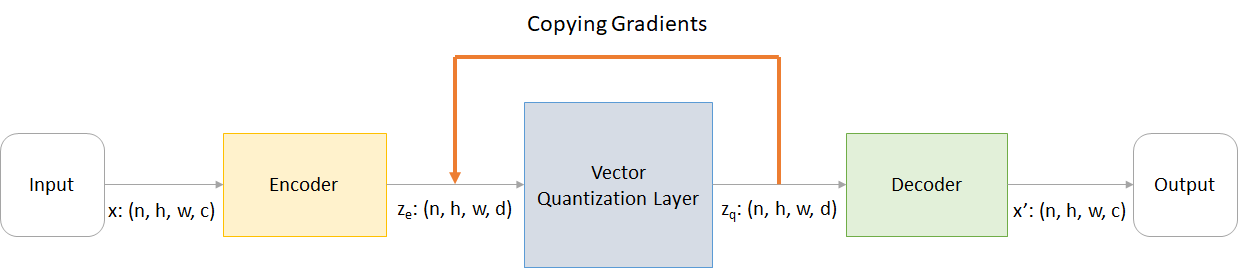
Di mana:
n : Ukuran Batchh : Tinggi gambarw : Lebar gambarc : Jumlah saluran dalam gambar inputd : Jumlah saluran dalam keadaan tersembunyi Berikut gambaran singkat tentang kerja jaringan VQ-VAE:
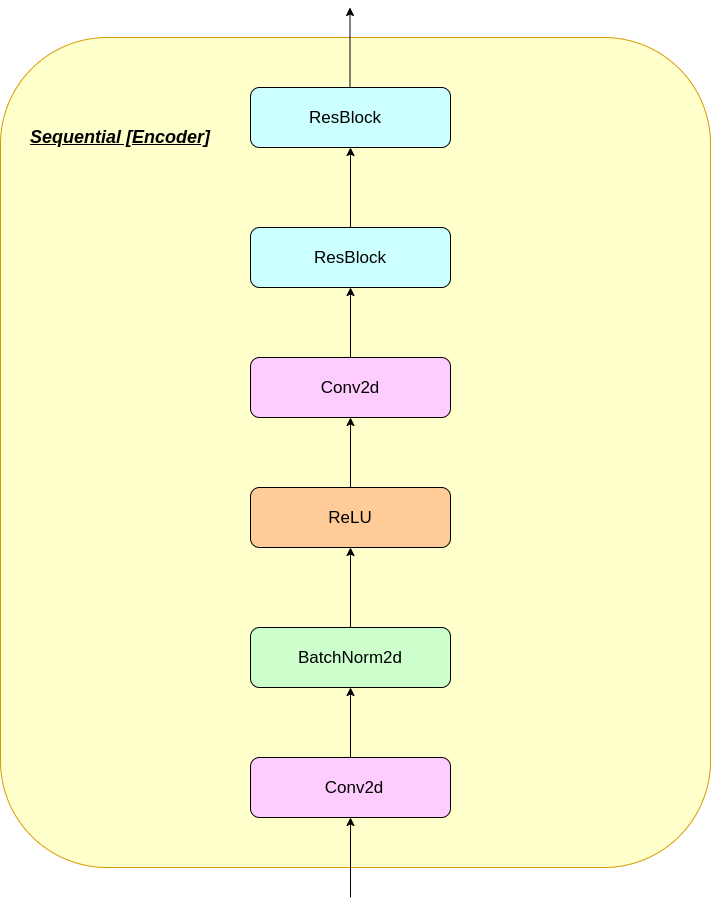
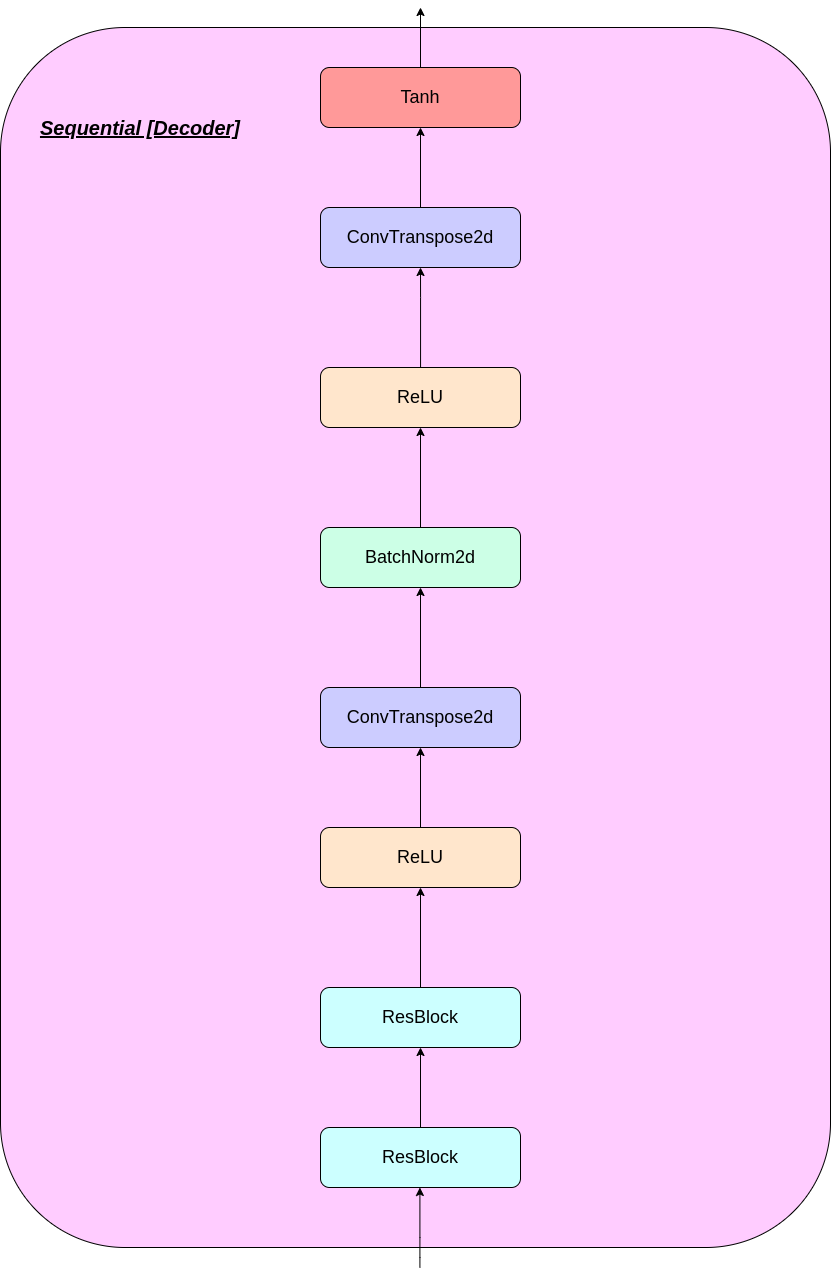
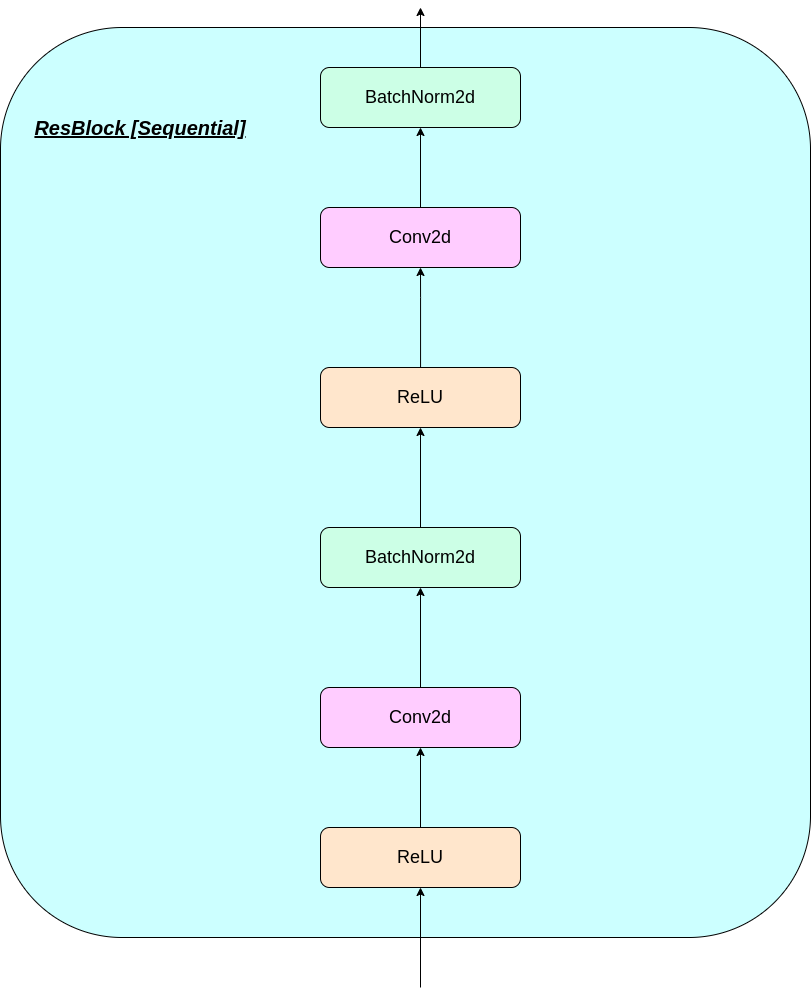
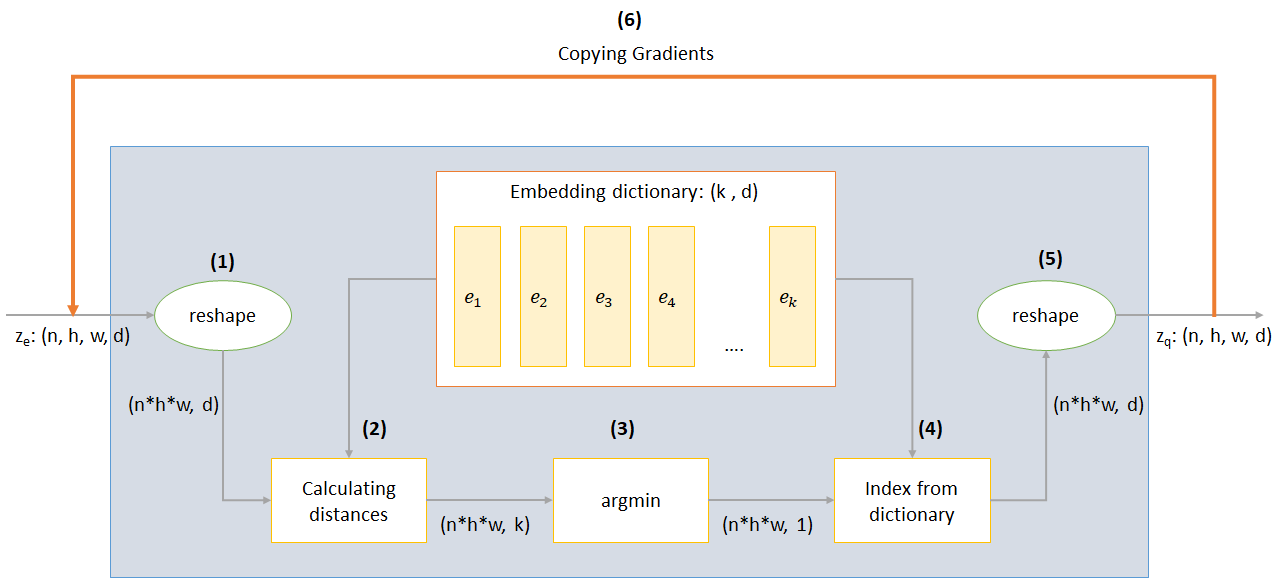
Kerja lapisan VQ dapat dijelaskan dalam enam langkah yang diberi nomor dalam gambar:
VQ-VAE menggunakan 3 kerugian untuk menghitung total kerugian selama pelatihan:
Kehilangan Rekonstruksi: Mengoptimalkan Decoder dan Encoder sebagai VAE, yaitu perbedaan antara gambar input dan rekonstruksi:
reconstruction_loss = -log( p(x|z_q) )
Kehilangan Codebook: Karena fakta bahwa gradien memotong embedding, algoritma pembelajaran kamus yang menggunakan kesalahan L2 untuk memindahkan vektor embedding E_I ke arah output enkoder digunakan.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG mewakili operator gradien stop yang berarti tidak ada gradien mengalir melalui apa pun yang diterapkan)
Kehilangan komitmen: Karena volume ruang embedding tidak berdimensi, ia dapat tumbuh secara sewenang -wenang jika embeddings e_i tidak berlatih secepat parameter encoder, dan dengan demikian kehilangan komitmen ditambahkan untuk memastikan bahwa encoder berkomitmen untuk penyematan.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β adalah hiperparameter yang mengontrol seberapa besar kami ingin menimbang kehilangan komitmen dibandingkan dengan komponen lain)
Anda dapat mengunduh repo atau mengkloningnya dengan menjalankan yang berikut di cmd prompt
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Anda dapat melatih model dari awal dengan perintah berikut (di Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Nama folder datadata-folder - Nama folder datadevice - Atur perangkat (CPU atau CUDA, default: CPU)hidden-size - ukuran vektor laten (default: 40)k - Jumlah vektor laten (default: 512)batch-size - Ukuran Batch (Default: 128)num-epochs - Jumlah zaman (default: 10)lr - Tingkat Pembelajaran untuk Adam Optimizer (Default: 2E -4)beta - Kontribusi kehilangan komitmen, antara 0,1 dan 2.0 (default: 1.0)num-workers - Jumlah Pekerja untuk Lintasan Sampel (Default: CPU_Count () - 1) Program secara otomatis mengunduh dataset MNIST dan menyimpannya di folder PATH_TO_MNIST_dataset (Anda perlu membuat folder ini). Ini hanya terjadi sekali.
Ini juga membuat folder logs dan folder models dan di dalamnya membuat folder dengan nama yang dilewatkan oleh Anda untuk menyimpan log dan model pos pemeriksaan di dalamnya masing -masing.
Untuk menghasilkan gambar baru dari Z sampel secara acak dari unit Gaussian menjalankan perintah berikut (di Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - Nama file yang berisi modelinput - Mnist atau Randomdevice - Atur perangkat (CPU atau CUDA, default: CPU)hidden-size - ukuran vektor laten (default: 40)k - Jumlah vektor laten (default: 512)filename - nama dengan file mana yang akan disimpan Ini menghasilkan grid gambar 10*10 yang disimpan dalam folder bernama generatedImages .
Anda dapat menggunakan model pra-terlatih dengan mengunduhnya dari tautan di model.txt .
Repositori berisi file berikut
modules.py - berisi berbagai modul yang digunakan untuk membuat model kamiVQ-VAE.py -berisi fungsi dan kode untuk melatih model VQ-VAE kamivector_quantizer.py - Kelas kuantisasi vektor didefinisikan dalam file inigenerate-py -Menghasilkan gambar baru dari model pra-terlatihmodel.txt - Berisi tautan ke model pra -terlatihREADME.md - Readme memberikan gambaran umum tentang reporeferences.txt - referensi yang digunakan saat membuat repo inireadme_images - memiliki berbagai gambar untuk readmeMNIST - Berisi dataset mnist zip (meskipun akan diunduh secara otomatis jika diperlukan)Training track for VQ-VAE.txt -berisi nilai kerugian selama pelatihan model VQ-VAE kamilogs_VQ-VAE -berisi log tensorboard zip untuk model VQ-VAE kami (secara otomatis dibuat oleh program)testers.py - berisi beberapa fungsi untuk menguji modul yang kami tentukanPerintah untuk menjalankan Tensorboard (di Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Gambar pelatihan
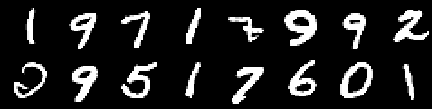
Gambar dari zaman ke -0

Gambar dari zaman ke -2
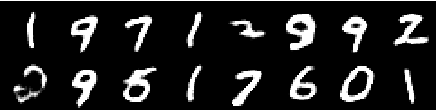
Gambar dari zaman ke -4
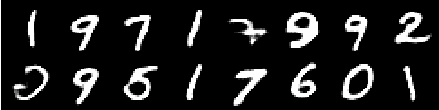
Gambar dari zaman ke -6
Gambar dari zaman ke -8
Gambar dari zaman ke -10
Rekonstruksi terus meningkat dan pada akhirnya hampir menyerupai gambar pelatihan_set yang tercermin dalam nilai kerugian (periksa Training track for VQ-VAE.txt ).
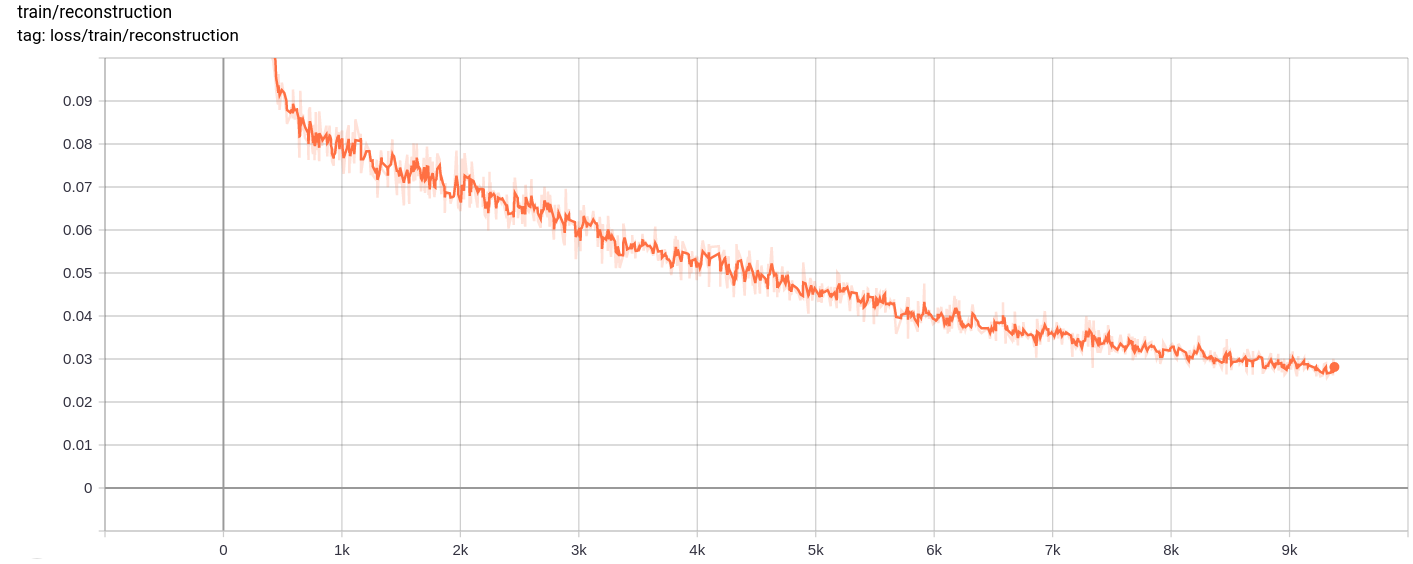
Kerugian rekonstruksi
Kerugian kuantisasi
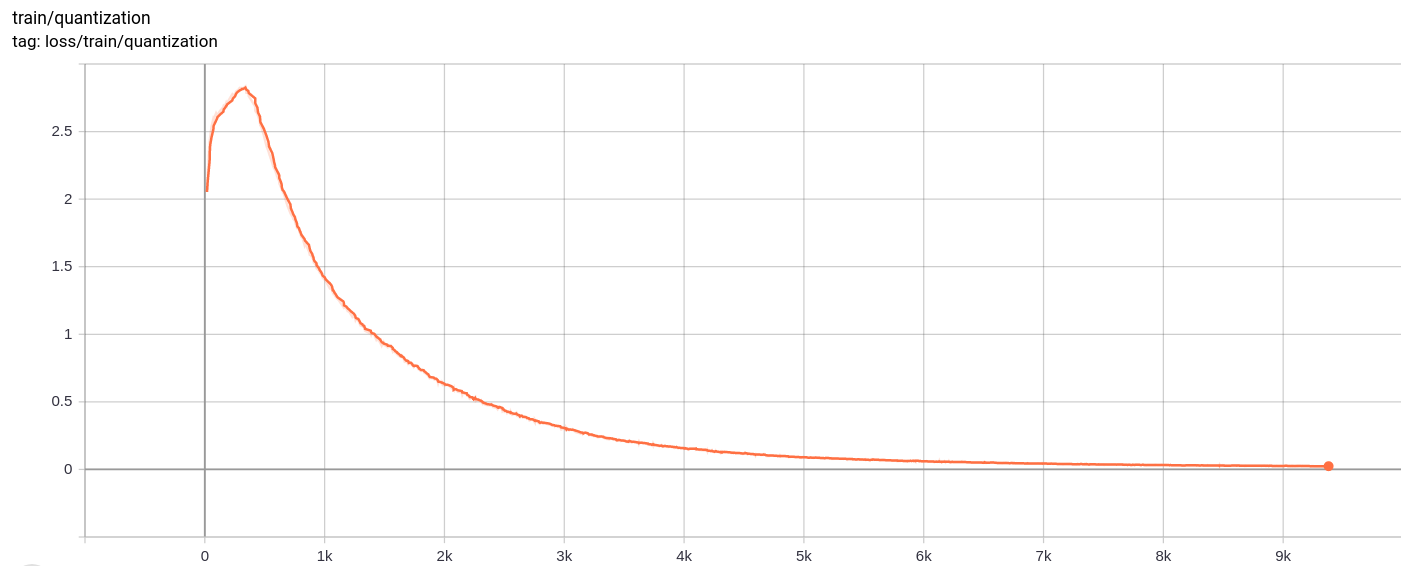
Total_loss
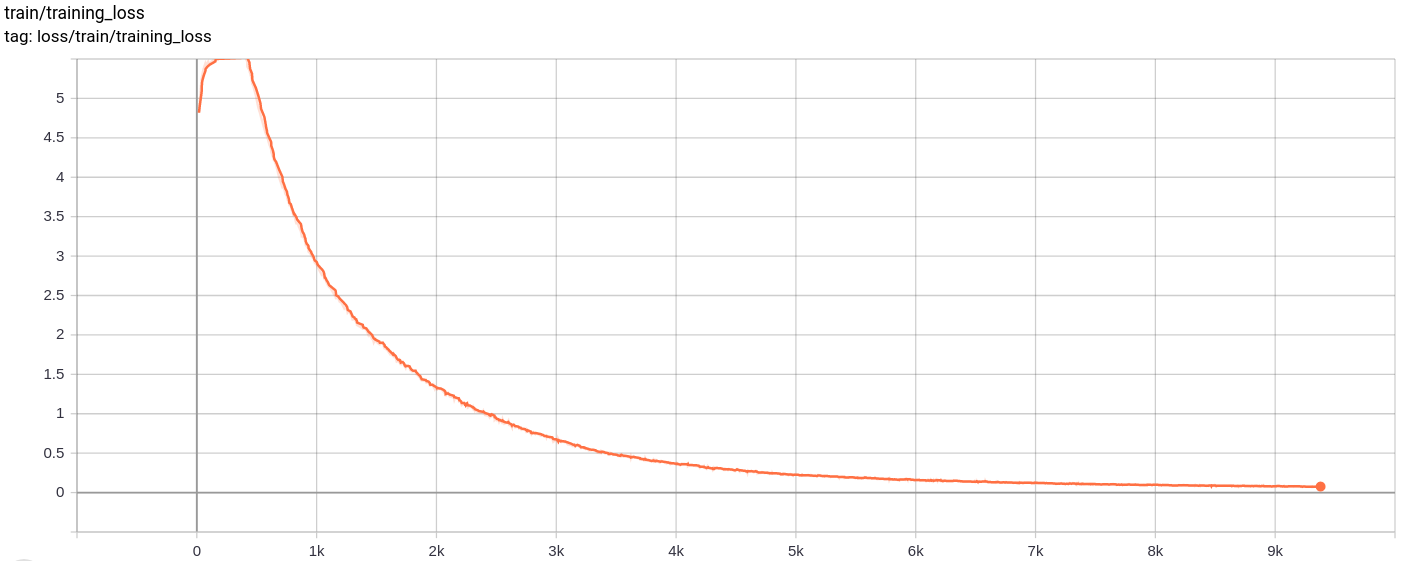
Kehilangan total, kerugian rekonstruksi dan kerugian kuantisasi menurun secara seragam seperti yang diharapkan.
Testing_loss
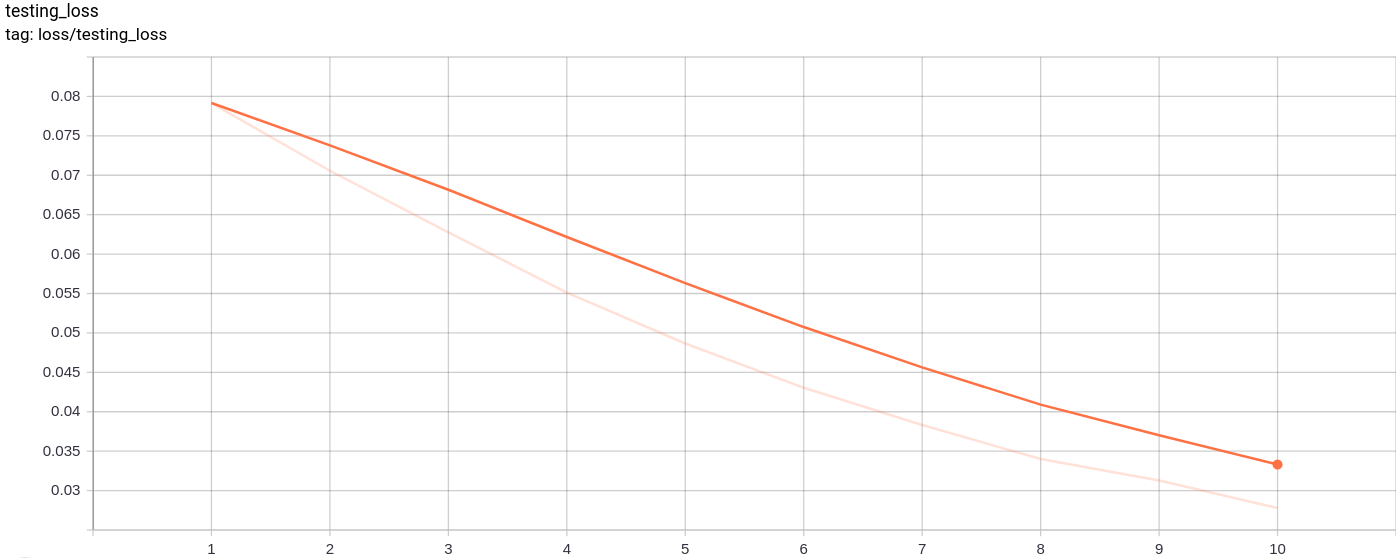
Kehilangan pengujian berkurang secara seragam seperti yang diharapkan.
Kisi gambar berikut dihasilkan setelah melewati gambar mnist sebagai input:

Generasi ini cukup bagus.
Kisi -kisi gambar berikut dihasilkan setelah melewati AZ sampel secara acak dari unit Gaussian sebagai input ke model dan kemudian melewati decoder


Gambar tidak terlihat sempurna. Menyetel dimensi ruang laten, jumlah vektor embedding dll dapat membantu dalam menghasilkan gambar acak yang lebih baik.
Model ini dilatih di Google Colab selama 10 zaman, dengan ukuran batch 128.
Setelah pelatihan, model ini dapat merekonstruksi gambar input dengan cukup baik, dan juga dapat menghasilkan gambar baru meskipun gambar yang dihasilkan tidak begitu baik.
Pelatihan serta kehilangan pengujian juga terus menurun hampir secara monoton.
Saya mengamati bahwa melatih model untuk lebih dari 10-20 zaman menghasilkan hasil yang menyarankan kemungkinan tanda overfitting dalam model. Juga, saya bereksperimen dengan dimensi yang berbeda dari ruang berlarut dan pada dimension = 40 menghasilkan hasil terbaik. Kisaran terbaik untuk dimensi keluar antara 16-42.
Sumber -sumber berikut banyak membantu membuat repositori ini


