flash attention
v2.7.0
Repositori ini memberikan implementasi resmi flashattention dan flashattention-2 dari makalah berikut.
Flashattention: Perhatian yang cepat dan efisien memori dengan kesadaran IO-
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
Kertas: https://arxiv.org/abs/2205.14135
Artikel IEEE Spectrum tentang pengiriman kami ke tolok ukur MLPERF 2.0 menggunakan flashattention. 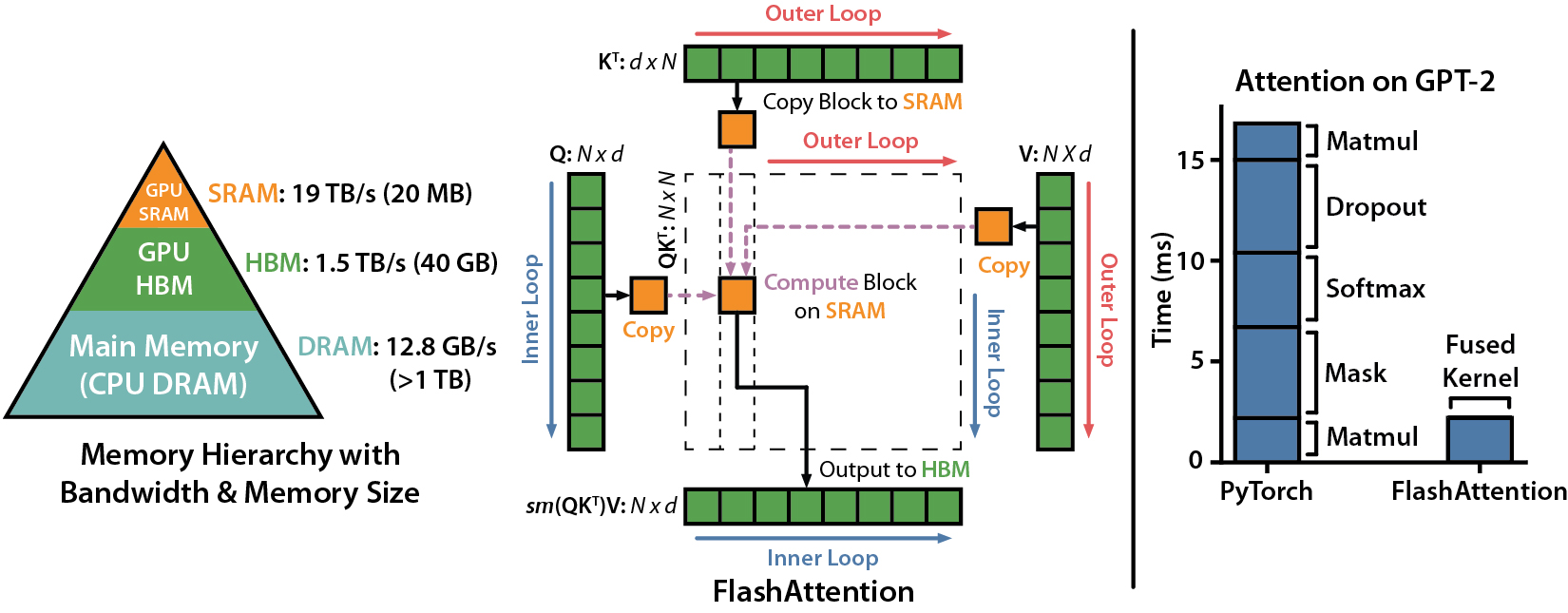
Flashattention-2: Perhatian yang lebih cepat dengan paralelisme yang lebih baik dan partisi kerja
Tri dao
Kertas: https://tridao.me/publications/flash2/flash2.pdf

Kami sangat senang melihat flashattention diadopsi secara luas dalam waktu yang singkat setelah dirilis. Halaman ini berisi sebagian daftar tempat di mana flashattention sedang digunakan.
Flashattention dan flashattention-2 bebas untuk digunakan dan memodifikasi (lihat lisensi). Harap kutip dan kredit flashattention jika Anda menggunakannya.
Flashattention-3 dioptimalkan untuk Hopper GPU (misalnya H100).
BlogPost: https://tridao.me/blog/2024/flash3/
Kertas: https://tridao.me/publications/flash3/flash3.pdf
Ini adalah rilis beta untuk pengujian / pembandingan sebelum kami mengintegrasikannya dengan sisa repo.
Saat ini dirilis:
Persyaratan: H100 / H800 GPU, CUDA> = 12.3.
Untuk saat ini, kami sangat merekomendasikan CUDA 12.3 untuk kinerja terbaik.
Untuk menginstal:
cd hopper
python setup.py installUntuk menjalankan tes:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyPersyaratan:
packaging ( pip install packaging )ninja Python ( pip install ninja ) * * Pastikan ninja diinstal dan berfungsi dengan benar (misalnya ninja --version kemudian echo $? Haruskah mengembalikan kode keluar 0). Jika tidak (kadang -kadang ninja --version kemudian echo $? Mengembalikan kode keluar nol), uninstall kemudian instal ulang ninja ( pip uninstall -y ninja && pip install ninja ). Tanpa ninja , kompilasi bisa memakan waktu yang sangat lama (2 jam) karena tidak menggunakan beberapa inti CPU. Dengan kompilasi ninja membutuhkan waktu 3-5 menit pada mesin 64-core menggunakan CUDA Toolkit.
Untuk menginstal:
pip install flash-attn --no-build-isolationAtau Anda dapat mengkompilasi dari sumber:
python setup.py install Jika mesin Anda memiliki RAM kurang dari 96GB dan banyak core CPU, ninja mungkin menjalankan terlalu banyak pekerjaan kompilasi paralel yang dapat menghabiskan jumlah RAM. Untuk membatasi jumlah pekerjaan kompilasi paralel, Anda dapat mengatur variabel lingkungan MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation Antarmuka: src/flash_attention_interface.py
Persyaratan:
Kami merekomendasikan wadah Pytorch dari NVIDIA, yang memiliki semua alat yang diperlukan untuk menginstal flashattention.
Flashattention-2 dengan CUDA saat ini mendukung:
Versi ROCM menggunakan Composable_Kernel sebagai backend. Ini memberikan implementasi flashattention-2.
Persyaratan:
Kami merekomendasikan wadah Pytorch dari ROCM, yang memiliki semua alat yang diperlukan untuk menginstal flashattention.
Flashattention-2 dengan ROCM saat ini mendukung:
Fungsi utama mengimplementasikan perhatian produk yang diskalakan (softmax (q @ k^t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""Untuk melihat bagaimana fungsi-fungsi ini digunakan dalam lapisan perhatian multi-kepala (yang mencakup proyeksi QKV, proyeksi output), lihat implementasi MHA.
Meningkatkan dari flashattention (1.x) ke flashattention-2
Fungsi -fungsi ini telah diganti namanya:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcJika input memiliki panjang urutan yang sama dalam batch yang sama, lebih sederhana dan lebih cepat menggunakan fungsi -fungsi ini:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )Jika seqlen_q! = Seqlen_k dan kausal = true, topeng kausal disejajarkan dengan sudut kanan bawah matriks perhatian, bukan sudut kiri atas.
Misalnya, jika seqlen_q = 2 dan seqlen_k = 5, mask kausal (1 = Keep, 0 = bertopeng keluar) adalah:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
Jika seqlen_q = 5 dan seqlen_k = 2, topeng kausal adalah:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
Jika baris topeng semuanya nol, output akan nol.
Optimalkan untuk inferensi (decoding iterative) Ketika kueri memiliki panjang urutan yang sangat kecil (misalnya, panjang urutan kueri = 1). Hambatan di sini adalah memuat cache KV secepat mungkin, dan kami membagi pemuatan di berbagai blok benang, dengan kernel terpisah untuk menggabungkan hasil.
Lihat fungsi flash_attn_with_kvcache dengan lebih banyak fitur untuk inferensi (lakukan embedding rotary, memperbarui cache kv di tempat).
Terima kasih kepada tim XFORMERS, dan khususnya Daniel Haziza, untuk kolaborasi ini.
Menerapkan perhatian jendela geser (yaitu, perhatian lokal). Terima kasih kepada Mistral AI dan khususnya Timothée Lacroix untuk kontribusi ini. Jendela geser digunakan dalam model 7B Mistral.
Menerapkan alibi (Press et al., 2021). Terima kasih kepada Sanghun Cho dari Kakao Brain untuk kontribusi ini.
Menerapkan pass mundur deterministik. Terima kasih kepada para insinyur dari Meituan untuk kontribusi ini.
Dukungan Paged KV Cache (yaitu, Pagetedattention). Terima kasih kepada @Beginlner untuk kontribusi ini.
Dukung perhatian dengan softcapping, seperti yang digunakan dalam model Gemma-2 dan Grok. Terima kasih kepada @narsil dan @lucidrains untuk kontribusi ini.
Terima kasih kepada @ANI300 untuk kontribusi ini.
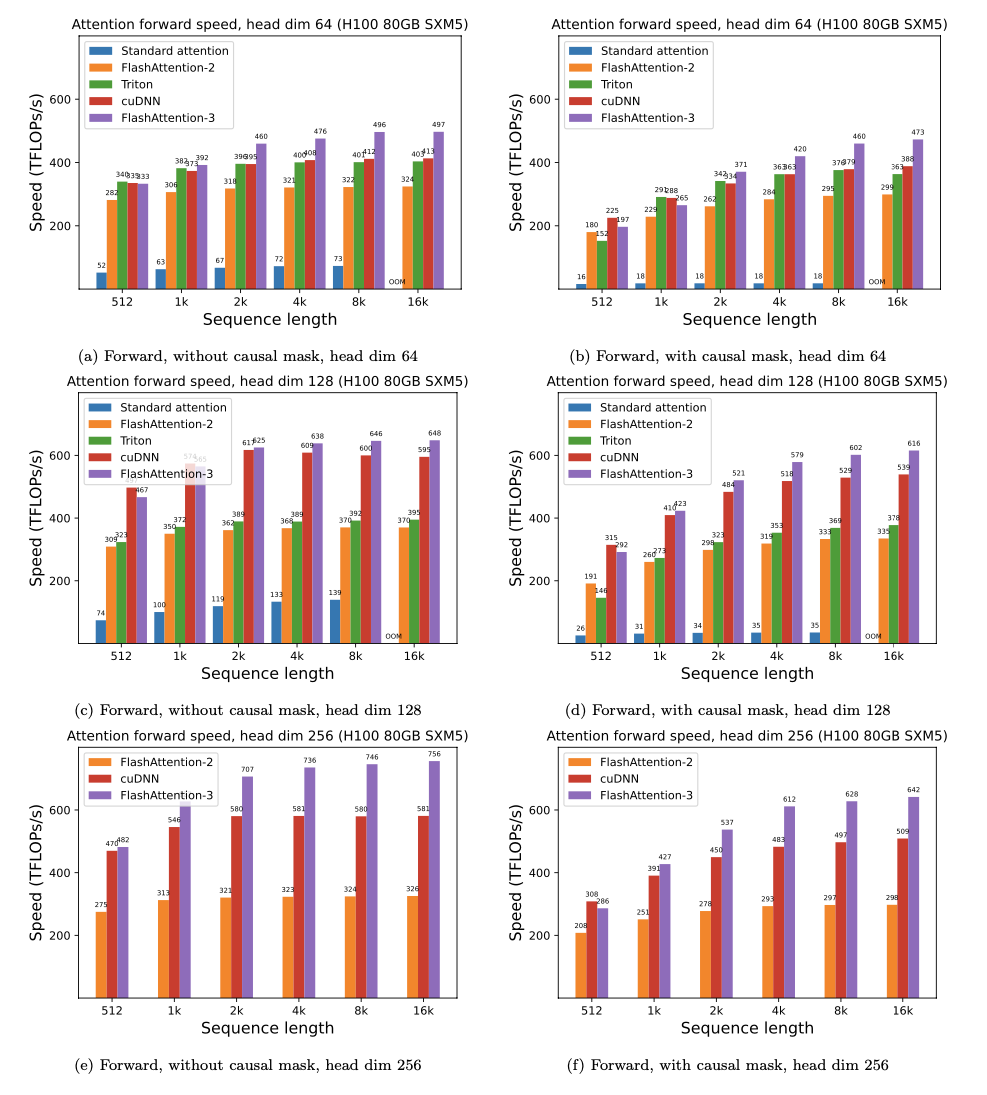
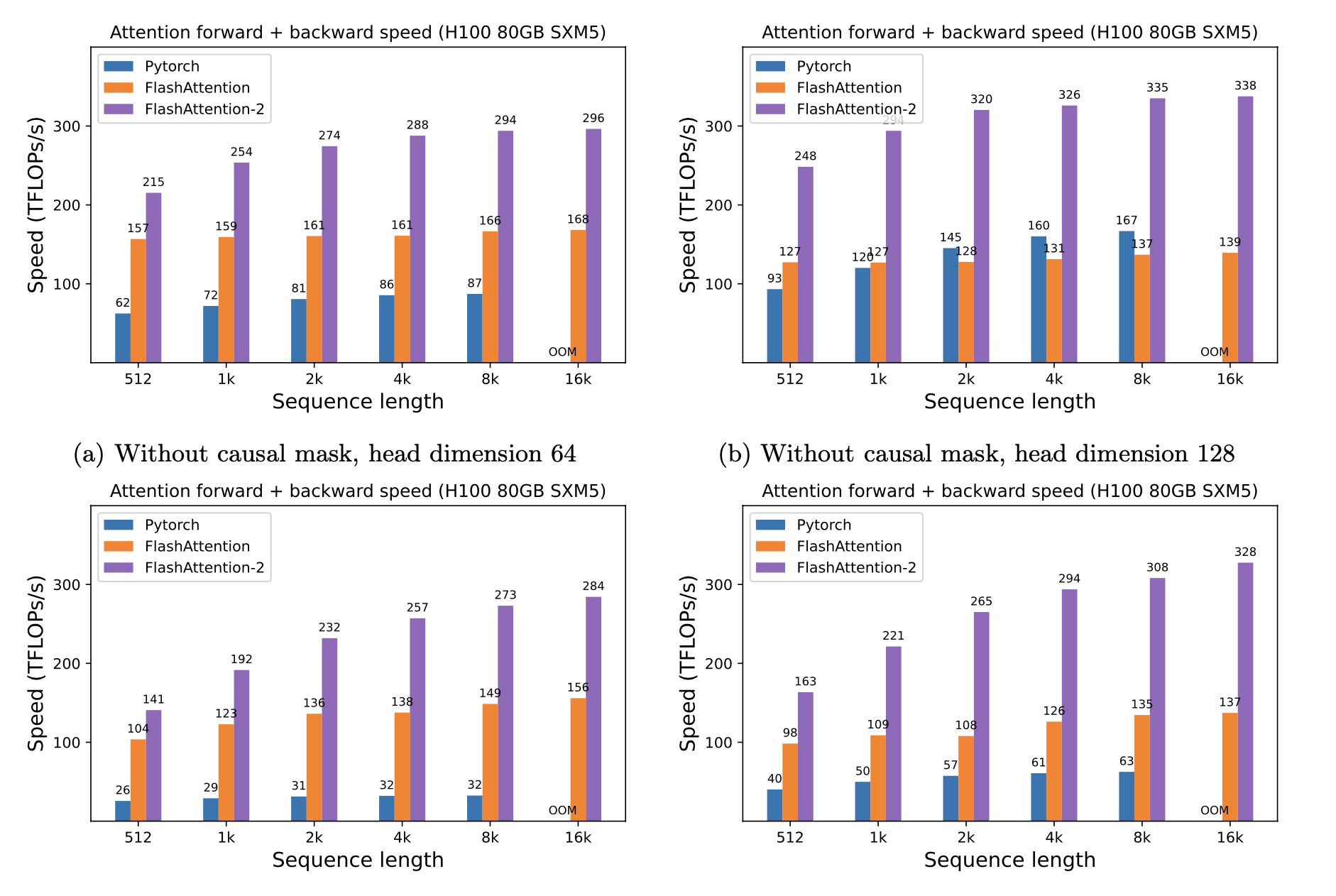
Kami menyajikan speedup yang diharapkan (gabungan maju + backward pass) dan penghematan memori dari menggunakan flashattention terhadap perhatian standar pytorch, tergantung pada panjang urutan, pada GPU yang berbeda (speedup tergantung pada bandwidth memori - kami melihat lebih banyak speedup pada memori GPU yang lebih lambat).
Kami saat ini memiliki tolok ukur untuk GPU ini:
Kami menampilkan speedup flashattention menggunakan parameter ini:
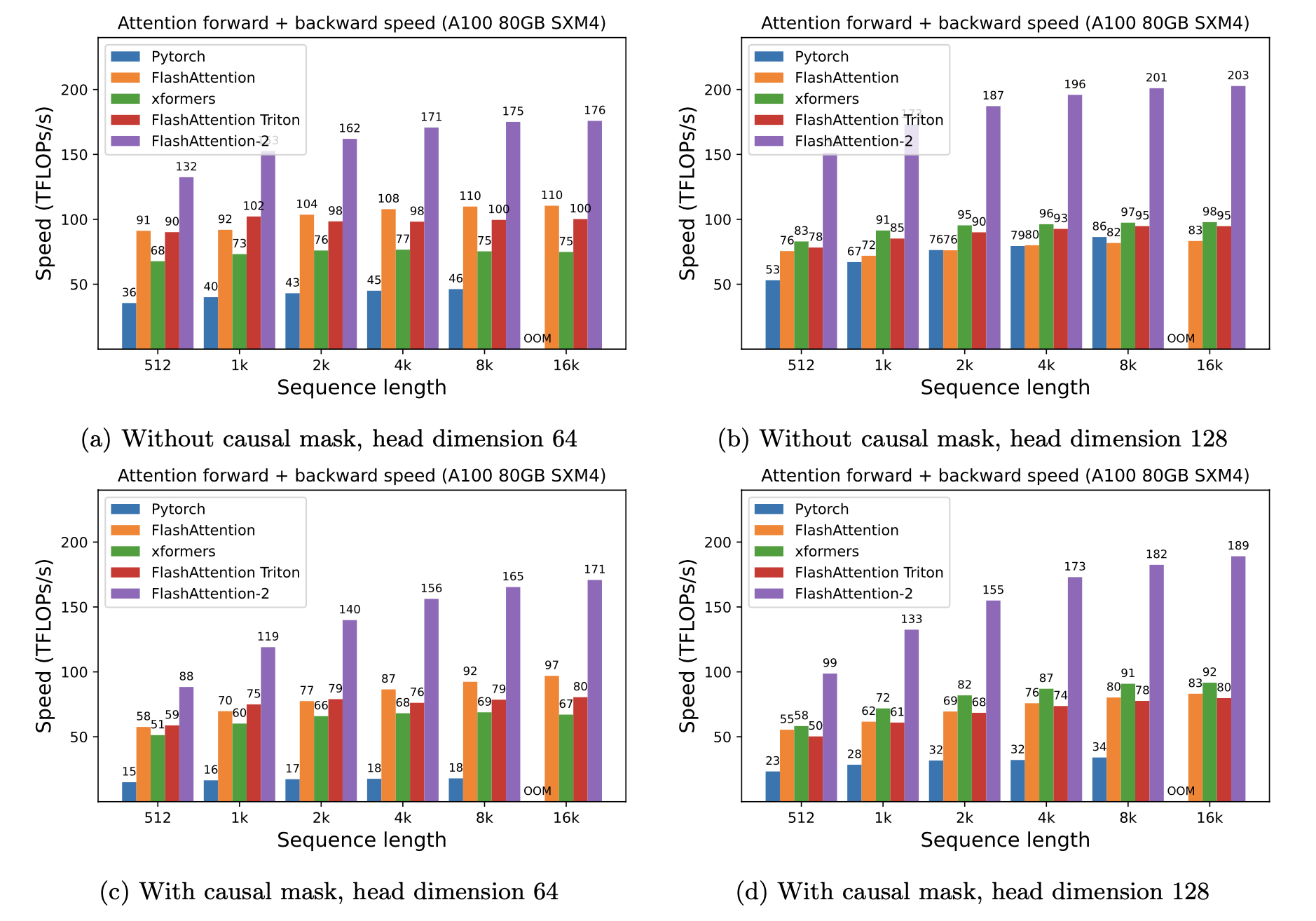
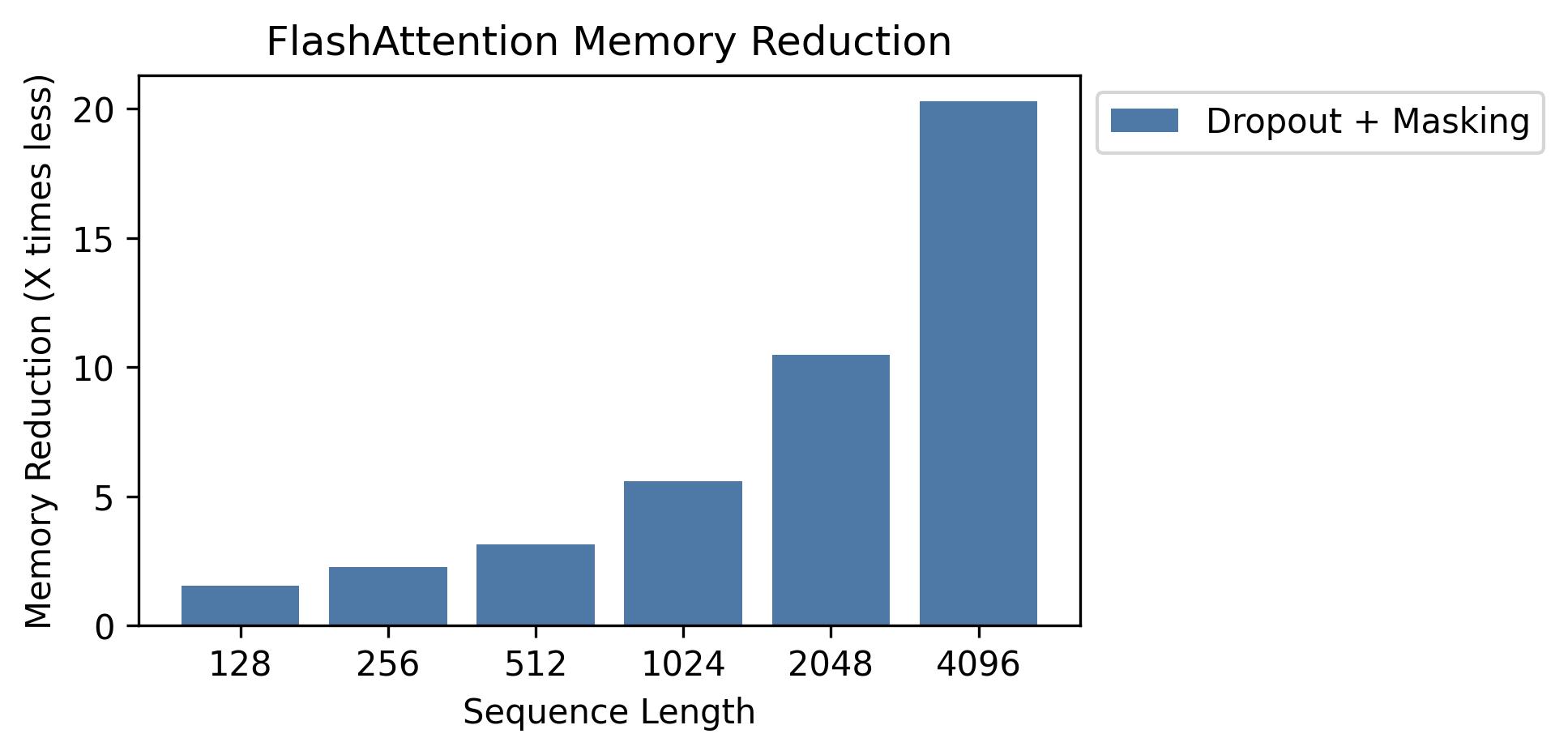
Kami menunjukkan penghematan memori dalam grafik ini (perhatikan bahwa jejak memori adalah sama tidak peduli jika Anda menggunakan dropout atau masking). Penghematan memori sebanding dengan panjang urutan - karena perhatian standar memiliki kuadratik memori dalam panjang urutan, sedangkan flashattention memiliki memori linier dalam panjang urutan. Kita melihat penghematan memori 10x pada panjang urutan 2K, dan 20x pada 4K. Akibatnya, flashattention dapat skala ke panjang urutan yang lebih lama.
Kami telah merilis implementasi model GPT lengkap. Kami juga memberikan implementasi yang dioptimalkan dari lapisan lain (misalnya, MLP, Layernorm, kehilangan entropi silang, penyematan putar). Secara keseluruhan ini mempercepat pelatihan dengan 3-5x dibandingkan dengan implementasi dasar dari Huggingface, mencapai hingga 225 TFLOPS/Sec per A100, setara dengan 72% model pemanfaatan flop (kami tidak memerlukan pemeriksaan aktivasi).
Kami juga menyertakan skrip pelatihan untuk melatih GPT2 di OpenWebtext dan GPT3 di tumpukan.
Phil Tillet (Openai) memiliki implementasi eksperimental flashattention di Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
Karena Triton adalah bahasa tingkat yang lebih tinggi daripada CUDA, mungkin lebih mudah untuk dipahami dan bereksperimen. Notasi dalam implementasi Triton juga lebih dekat dengan apa yang digunakan dalam makalah kami.
Kami juga memiliki implementasi eksperimental di Triton yang mendukung bias perhatian (misalnya alibi): https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
Kami menguji bahwa flashattention menghasilkan output dan gradien yang sama dengan implementasi referensi, hingga beberapa toleransi numerik. Secara khusus, kami memeriksa bahwa kesalahan numerik maksimum flashattention adalah paling banyak dua kali kesalahan numerik dari implementasi dasar dalam pytorch (untuk dimensi kepala yang berbeda, input dType, panjang urutan, kausal / non-kausal).
Untuk menjalankan tes:
pytest -q -s tests/test_flash_attn.pyRilis baru Flashattention-2 ini telah diuji pada beberapa model gaya GPT, sebagian besar pada A100 GPU.
Jika Anda menemukan bug, buka masalah github!
Untuk menjalankan tes:
pytest tests/test_flash_attn_ck.pyJika Anda menggunakan basis kode ini, atau menemukan pekerjaan kami berharga, silakan kutip:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


