LLaMA Omni
1.0.0
Penulis: Qinggai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng*
Llama-Omni adalah model bahasa-bahasa yang dibangun di atas llama-3.1-8b-instruct. Ini mendukung interaksi latensi rendah dan berkualitas tinggi, secara bersamaan menghasilkan respons teks dan bicara berdasarkan instruksi bicara.
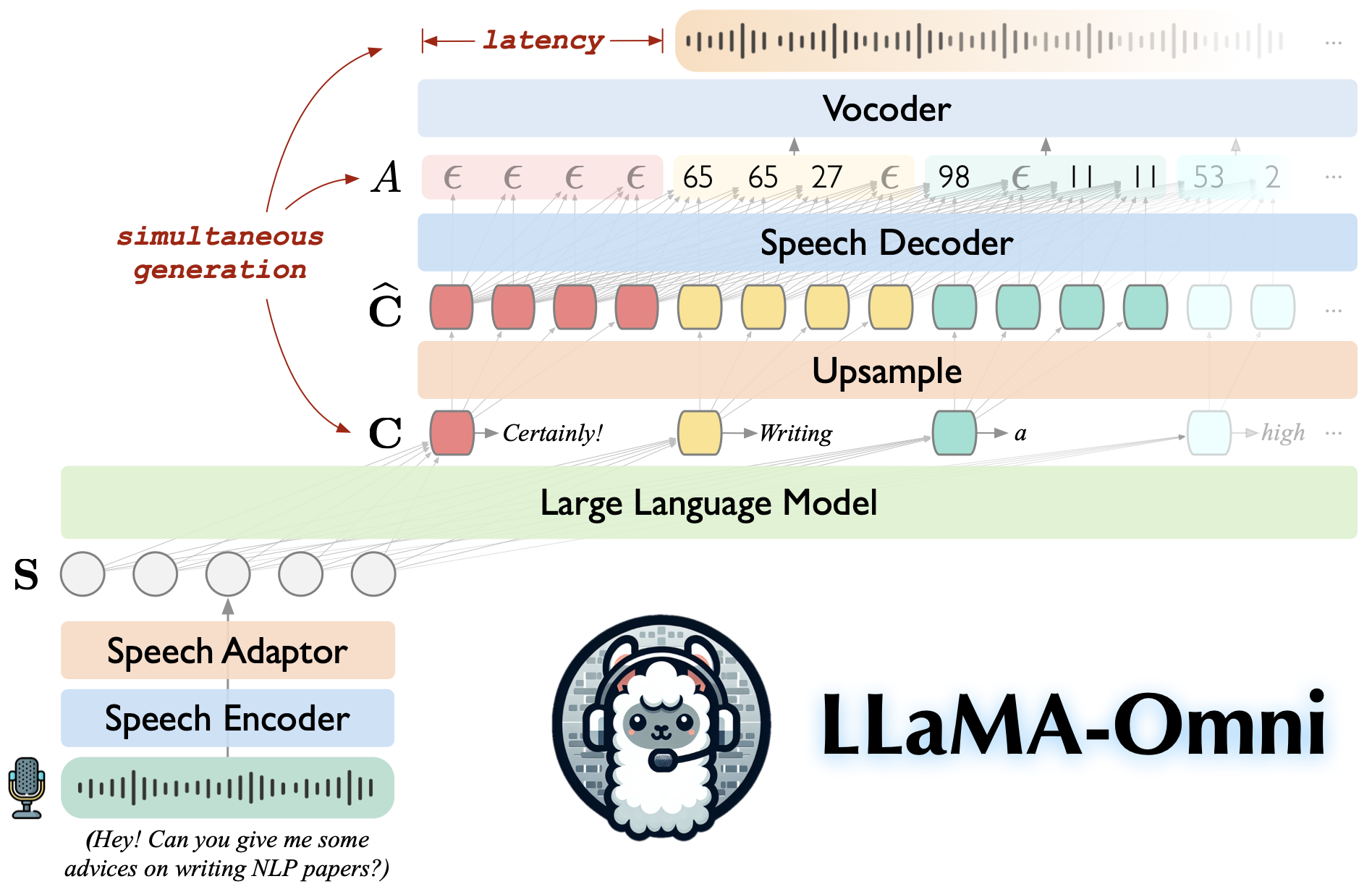
Dibangun di atas llama-3.1-8b-instruct, memastikan respons berkualitas tinggi.
Interaksi ucapan latensi rendah dengan latensi serendah 226ms.
Generasi simultan dari tanggapan teks dan bicara.
♻️ dilatih dalam waktu kurang dari 3 hari menggunakan hanya 4 GPU.
Kloning repositori ini.
git clone https://github.com/ictnlp/llama-omnicd llama-omni
Instal Paket.
conda create -n llama -omni python = 3.10 conda mengaktifkan llama-omni Pip Instal Pip == 24.0 Pip Instal -e.
Instal fairseq .
git clone https://github.com/pytorch/fairseqcd fairseq Pip Instal -e. ---no-build-isolation
Instal flash-attention .
PIP menginstal flash-attn ---no-build-isolation
Unduh model Llama-3.1-8B-Omni dari? Huggingface.
Unduh model Whisper-large-v3 .
Impor bisikan
model = whisper.load_model ("besar-v3", download_root = "model/pidato_encoder/")Unduh Vocoder HiFi-Gan berbasis unit.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 vocoder/POCOODER/ wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p vocoder/
Luncurkan pengontrol.
python -m omni_speech.serve.controller --host 0.0.0.0 --port 10000
Luncurkan server web gradio.
python -m omni_speech.serve.gradio_web_server --controller http: // localhost: 10000 --port 8000 --model-list-mode Reload-Vocoder Vocoder/G_00500000 --Vocoder-CFG Vocoder/Config.json
Luncurkan model pekerja.
python -m omni_speech.serve.model_worker --host 0.0.0.0 ---controller http: // localhost: 10000 --port 40000 --Kokor http: // localhost: 40000-Model-Path llama-3.1-8b-omni --Model-name llama-3.1-8b-omni --s2s
Kunjungi http: // localhost: 8000/dan berinteraksi dengan llama-3.1-8b-omni!
Catatan: Karena ketidakstabilan streaming pemutaran audio di gradio, kami hanya menerapkan sintesis audio streaming tanpa mengaktifkan autoplay. Jika Anda memiliki solusi yang baik, jangan ragu untuk mengirimkan PR. Terima kasih!
Untuk menjalankan inferensi secara lokal, silakan atur file instruksi ucapan sesuai dengan format dalam direktori omni_speech/infer/examples , lalu lihat skrip berikut.
Bash omni_speech/infer/run.sh omni_speech/infer/contoh
Kode kami dirilis di bawah lisensi Apache-2.0. Model kami dimaksudkan untuk tujuan penelitian akademik saja dan tidak dapat digunakan untuk tujuan komersial.
Anda bebas menggunakan, memodifikasi, dan mendistribusikan model ini dalam pengaturan akademik, asalkan kondisi berikut dipenuhi:
Penggunaan non-komersial : Model tidak dapat digunakan untuk tujuan komersial apa pun.
Kutipan : Jika Anda menggunakan model ini dalam penelitian Anda, silakan kutip karya aslinya.
Untuk pertanyaan penggunaan komersial atau untuk mendapatkan lisensi komersial, silakan hubungi [email protected] .
LLAVA: Basis kode yang kami bangun.
Slam-llm: Kami meminjam beberapa kode tentang ucapan ucapan dan adaptor ucapan.
Jika Anda memiliki pertanyaan, jangan ragu untuk mengirimkan masalah atau hubungi [email protected] .
Jika pekerjaan kami berguna untuk Anda, silakan kutip sebagai:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

