awesome RLHF
1.0.0
Ini adalah kumpulan makalah penelitian untuk pembelajaran penguatan dengan umpan balik manusia (RLHF). Dan repositori akan terus diperbarui untuk melacak perbatasan RLHF.
Selamat datang untuk mengikuti dan membintangi!
RLHF yang luar biasa (RL dengan umpan balik manusia)
2024
2023
2022
2021
2020 dan sebelum
Penjelasan terperinci
Daftar isi
Tinjauan RLHF
Dokumen
Basis kode
Dataset
Blog
Dukungan bahasa lainnya
Berkontribusi
Lisensi
Gagasan RLHF adalah menggunakan metode dari pembelajaran penguatan untuk secara langsung mengoptimalkan model bahasa dengan umpan balik manusia. RLHF telah memungkinkan model bahasa untuk mulai menyelaraskan model yang dilatih pada korpus umum data teks dengan nilai -nilai kemanusiaan yang kompleks.
RLHF untuk Model Bahasa Besar (LLM)
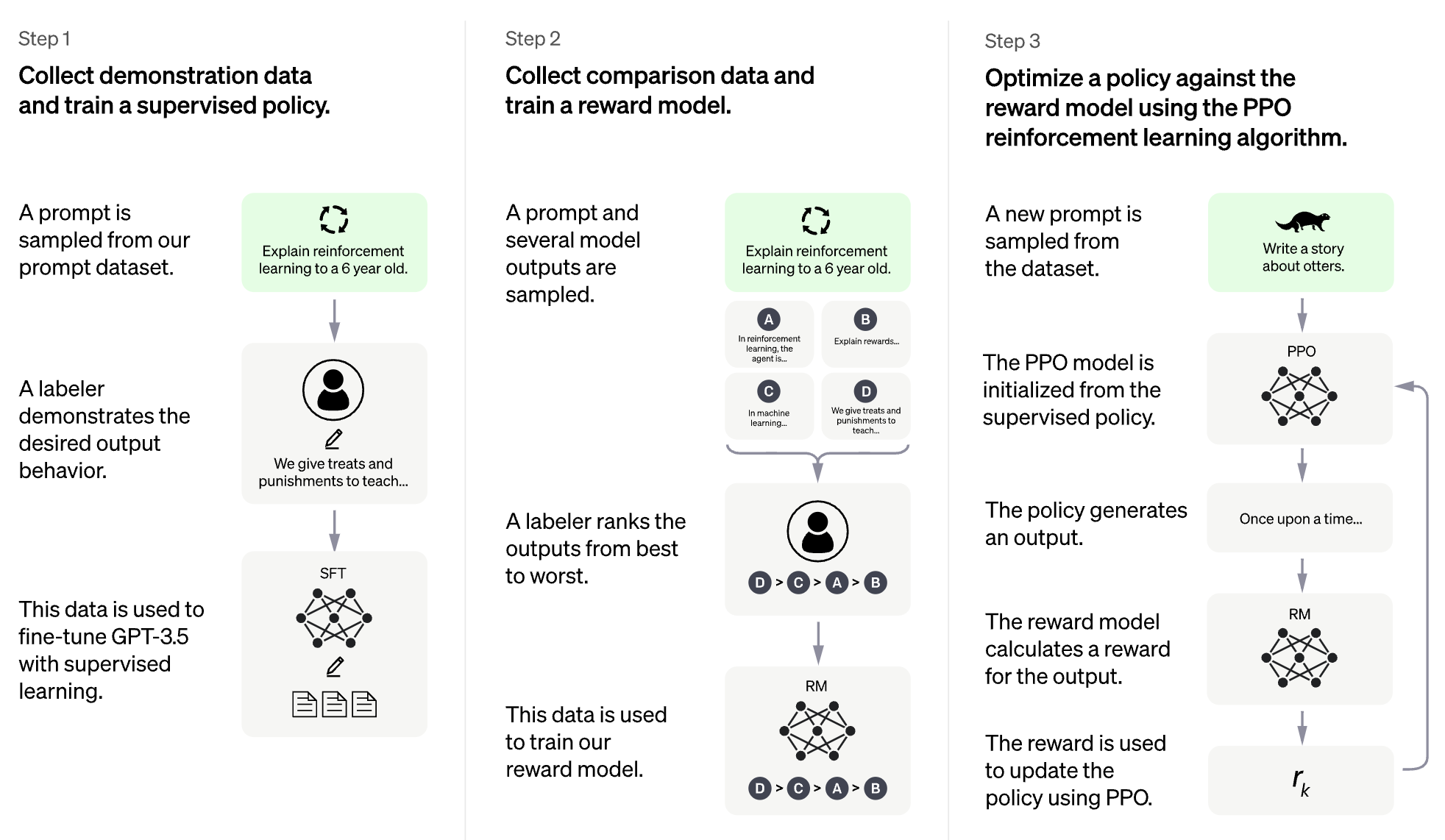
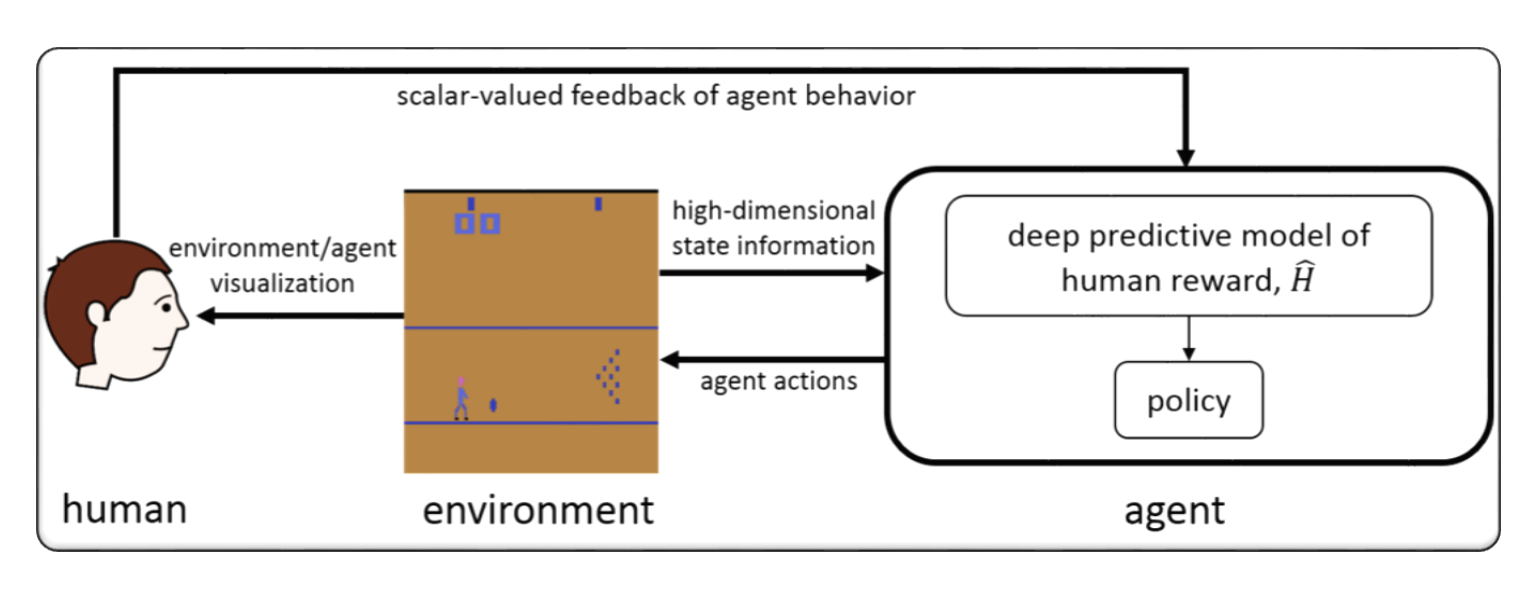
RLHF untuk video game (misalnya Atari)
(Bagian berikut secara otomatis dihasilkan oleh chatgpt)
RLHF biasanya mengacu pada "pembelajaran penguatan dengan umpan balik manusia". Penguatan Penguatan (RL) adalah jenis pembelajaran mesin yang melibatkan pelatihan agen untuk membuat keputusan berdasarkan umpan balik dari lingkungannya. Dalam RLHF, agen juga menerima umpan balik dari manusia dalam bentuk peringkat atau evaluasi tindakannya, yang dapat membantunya belajar lebih cepat dan akurat.
RLHF adalah area penelitian aktif dalam kecerdasan buatan, dengan aplikasi di bidang seperti robotika, permainan, dan sistem rekomendasi yang dipersonalisasi. Ia berupaya mengatasi tantangan RL dalam skenario di mana agen memiliki akses terbatas ke umpan balik dari lingkungan dan membutuhkan input manusia untuk meningkatkan kinerjanya.
Pembelajaran Penguatan dengan Umpan Balik Manusia (RLHF) adalah bidang penelitian yang berkembang pesat dalam kecerdasan buatan, dan ada beberapa teknik canggih yang telah dikembangkan untuk meningkatkan kinerja sistem RLHF. Berikut beberapa contoh:
Inverse Reinforcement Learning (IRL) : IRL adalah teknik yang memungkinkan agen untuk mempelajari fungsi hadiah dari umpan balik manusia, daripada mengandalkan fungsi hadiah yang telah ditentukan sebelumnya. Hal ini memungkinkan agen untuk belajar dari sinyal umpan balik yang lebih kompleks, seperti demonstrasi perilaku yang diinginkan.
Apprenticeship Learning : Pembelajaran magang adalah teknik yang menggabungkan IRL dengan pembelajaran yang diawasi untuk memungkinkan agen belajar dari umpan balik manusia dan demonstrasi ahli. Ini dapat membantu agen belajar lebih cepat dan efektif, karena dapat belajar dari umpan balik positif dan negatif.
Interactive Machine Learning (IML) : IML adalah teknik yang melibatkan interaksi aktif antara agen dan ahli manusia, yang memungkinkan ahli untuk memberikan umpan balik tentang tindakan agen secara real-time. Ini dapat membantu agen belajar lebih cepat dan efisien, karena dapat menerima umpan balik tentang tindakannya pada setiap langkah proses pembelajaran.
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL adalah teknik yang melibatkan mengintegrasikan umpan balik manusia ke dalam proses RL di berbagai tingkatan, seperti pembentukan hadiah, pemilihan tindakan, dan optimasi kebijakan. Ini dapat membantu meningkatkan efisiensi dan efektivitas sistem RLHF dengan memanfaatkan kekuatan manusia dan mesin.
Berikut adalah beberapa contoh pembelajaran penguatan dengan umpan balik manusia (RLHF):
Game Playing : Dalam permainan permainan, umpan balik manusia dapat membantu agen mempelajari strategi dan taktik yang efektif dalam skenario game yang berbeda. Misalnya, dalam permainan populer GO, para ahli manusia dapat memberikan umpan balik kepada agen tentang gerakannya, membantunya meningkatkan gameplay dan pengambilan keputusannya.
Personalized Recommendation Systems : Dalam sistem rekomendasi, umpan balik manusia dapat membantu agen mempelajari preferensi pengguna individu, memungkinkan untuk memberikan rekomendasi yang dipersonalisasi. Misalnya, agen dapat menggunakan umpan balik dari pengguna pada produk yang disarankan untuk mempelajari fitur mana yang paling penting bagi mereka.
Robotics : Dalam robotika, umpan balik manusia dapat membantu agen belajar bagaimana berinteraksi dengan lingkungan fisik dengan cara yang aman dan efisien. Misalnya, robot dapat belajar menavigasi lingkungan baru lebih cepat dengan umpan balik dari operator manusia di jalur terbaik untuk diambil atau objek mana yang harus dihindari.
Education : Dalam pendidikan, umpan balik manusia dapat membantu agen belajar bagaimana mengajar siswa secara lebih efektif. Misalnya, tutor berbasis AI dapat menggunakan umpan balik dari guru di mana strategi pengajaran bekerja paling baik dengan siswa yang berbeda, membantu mempersonalisasikan pengalaman belajar.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
HybridFlow: Kerangka kerja RLHF yang fleksibel dan efisien
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Kata kunci: kerangka kerja RLHF yang fleksibel, efisien
Kode: Resmi
Alarm: Align Bahasa Model melalui Pemodelan Hadiah Hierarkis
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Kata kunci: hadiah hierarkis, tugas pembuatan teks terbuka
Kode: Resmi
TLCR: Token Level Kontinu Riewah Untuk Pembelajaran Penguatan Berbutat Baik Dari Umpan Balik Manusia
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wontae Nam, Daejin Jo, Kyoung-Woon On, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Kata kunci: Token Level Continuous Reward, RLHF
Kode: Resmi
Menyelaraskan model multimodal besar dengan rLHF yang ditambah secara faktual
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Kata kunci: RLHF yang ditambah secara faktual, Visi & Bahasa, Dataset Preferensi Manusia
Kode: Resmi
Penyelarasan Model Bahasa Besar Langsung Melalui Distilasi Prompt Kontras Meningkat
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Kata kunci: tanpa data preferensi manusia, imbalan diri, DPO
Kode: Resmi
Kontrol Aritmatika LLM untuk Beragam Preferensi Pengguna: Penyelarasan Preferensi Directional dengan Hadiah Multi-Objektif
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Diao, Shuang Qiu, Han Zhao, Tong Zhang
Kata kunci: preferensi pengguna, model hadiah multi-objektif, pengambilan sampel penolakan finetuning
Kode: Resmi
Kembali ke Dasar -Dasar: Meninjau kembali optimasi gaya memperkuat untuk belajar dari umpan balik manusia di LLMS
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
Kata kunci: optimasi RL online, biaya komputasi rendah
Kode: Resmi
Meningkatkan model bahasa besar melalui pembelajaran penguatan berbutir halus dengan kendala pengeditan minimum
Zhipeng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Kata kunci: Hadiah Token-Level, LLM
Kode: Resmi
RLAIF vs RLHF: Penskalaan Penguatan Pembelajaran dari Umpan Balik Manusia dengan Umpan Balik AI
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Uskup Colton, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakashant
Kata kunci: RL dari umpan balik AI
Kode: Resmi
Metode berbasis penalti berprinsip untuk pembelajaran penguatan bilevel dan rlhf
Han Shen, Zhuoran Yang, Tianyi Chen
Kata kunci: Optimalisasi bilevel
Kode: Resmi
Hadiah padat secara gratis dalam pembelajaran penguatan dari umpan balik manusia
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Kata kunci: pembentukan hadiah, rlhf
Kode: Resmi
Pendekatan minimaximalis untuk pembelajaran penguatan dari umpan balik manusia
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Kata kunci: pemenang minimax, optimasi preferensi mandiri
Kode: Resmi
RLHF-V: Menuju MLLMS yang dapat dipercaya melalui penyelarasan perilaku dari umpan balik manusia yang berbutir halus
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Kata kunci: Model bahasa besar multimodal, masalah halusinasi, pembelajaran penguatan dari umpan balik manusia
Kode: Resmi
Alur kerja RLHF: Dari pemodelan hadiah ke RLHF online
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Kata kunci: RLHF iteratif online, pemodelan preferensi, model bahasa besar
Kode: Resmi
Maxmin-RLHF: Menuju penyelarasan yang adil dari model bahasa besar dengan preferensi manusia yang beragam
Souradip Chakraborty, JiaHao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Kata kunci: campuran distribusi preferensi, tujuan penyelarasan maxmin
Kode: Resmi
Dataset Reset Optimalisasi Kebijakan untuk RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianté Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Kata kunci: Dataset Reset Optimalisasi Kebijakan
Kode: Resmi
Tampilan hadiah padat tentang menyelaraskan difusi teks-ke-gambar dengan preferensi
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Kata kunci: rlhf untuk pembuatan teks-ke-gambar, peningkatan hadiah yang padat dari DPO, penyelarasan yang efisien
Kode: Resmi
Play fine-tuning mandiri mengubah model bahasa yang lemah menjadi model bahasa yang kuat
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan JI, Quanquan Gu
Kata kunci: Play fine-tuning sendiri
Kode: Resmi
RLHF Diuraikan: Analisis Kritis Pembelajaran Penguatan dari Umpan Balik Manusia untuk LLMS
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Kata kunci: rlhf, hadiah oracular, analisis model hadiah, survei
Menghadapi Overtimisasi Hadiah untuk Model Difusi: Perspektif Bias Induktif dan Keutamaan
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Kata kunci: Model Difusi, Penyelarasan, Pembelajaran Penguatan, RLHF, Hadiah Overtimisasi, Bias Keutamaan
Kode: Resmi
Tentang preferensi yang beragam dari penyelarasan model bahasa besar
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan Du, Zenglin Xu
Kata kunci: Menyelaraskan preferensi bersama, metrik pemodelan hadiah, LLM
Kode: Resmi
Menyelaraskan umpan balik kerumunan melalui pemodelan hadiah preferensi distribusi
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
Kata kunci: rlhf, distribusi preferensi, sejajar, llm
Beyond One-Preference-Fits-All Alignment: Multi-Objective Preferensi Langsung Optimalisasi
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Kata kunci: RLHF multi-objektif tanpa pemodelan hadiah, DPO
Kode: Resmi
Disalignment yang ditiru: Penyelarasan keselamatan untuk model bahasa besar dapat menjadi bumerang!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
Kata kunci: serangan waktu inferensi LLM, DPO, menghasilkan LLM yang berbahaya tanpa pelatihan
Kode: Resmi
Analisis Teoritis Pembelajaran NASH dari Umpan Balik Manusia di bawah Preferensi Umum yang Diatur KL
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Kata kunci: RLHF berbasis game, Nash Learning, Alignment di bawah oracle bebas-model hadiah
Memitigasi Pajak Alignment RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan, Tong Uthang, Tong Yao, Yuan, Tong Uthang, Tong Yi, Yuan, Yuan, Tong, Tong, Yuan, Yuan, Yuan, Tong, Tong, Yuan, Yuan, Yuan, Tong, Yuan, Yuan, Yuan, Yuan, Tong, Tong, Yuan, Yuan, Yuan, Yuan, Yuan, Tong, Yuan.
Kata kunci: RLHF, Pajak Alignment, Catastrophic Forgetting
Melatih model difusi dengan pembelajaran penguatan
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, Sergey Levine
Kata kunci: Pembelajaran Penguatan, RLHF, Model Difusi
Kode: Resmi
Aligndiff: Menyelaraskan beragam preferensi manusia melalui model difusi perilaku yang dapat disesuaikan
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Fan Changjie, Zhipeng Hu
Kata kunci: Pembelajaran Penguatan; Model difusi; Rlhf; Preferensi menyelaraskan
Kode: Resmi
Hadiah padat secara gratis dalam pembelajaran penguatan dari umpan balik manusia
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Kata kunci: RLHF
Kode: Resmi
Mengubah dan menggabungkan hadiah untuk menyelaraskan model bahasa besar
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex D'Amour, Sanmi Koyejo, Victor Veitch
Kata kunci: rlhf, sejajar, llm
Parameter Efisien Penguatan Pembelajaran dari Umpan Balik Manusia
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Ganesh, Bill Byrne, Jessica Hoffmann, Hassan Mansoor, Wei Li , Abhinav Rastogi, Lucas Dixon
Kata kunci: RLHF, Metode Efisien Parameter, Biaya Komputasi Rendah, LLM, VLM
Meningkatkan pembelajaran penguatan dari umpan balik manusia dengan ansambel model hadiah yang efisien
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Kata kunci: rlhf, imbalan ansambel, metode ensemble yang efisien
Paradigma teoretis umum untuk memahami pembelajaran dari preferensi manusia
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Kata kunci: rlhf, preferensi berpasangan
Umpan balik manusia berbutir halus memberikan hadiah yang lebih baik untuk pelatihan model bahasa
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouh Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hananeh Hajishirzi
Kata kunci: rlhf, imbalan tingkat kalimat, llm
Kode: Resmi
Bimbingan tingkat token yang ditumbuhkan preferensi untuk fine-tuning model bahasa
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Kata kunci: RLHF, panduan pelatihan tingkat token, kerangka kerja pelatihan alternatif/online, tujuan pelatihan minimalis
Kode: Resmi
Imbalan yang fantastis dan cara menjinakkannya: Studi kasus tentang pembelajaran hadiah untuk sistem dialog berorientasi tugas
Yihao Feng*, Shentao Yang*, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Kata kunci: rlhf, pembelajaran fungsi hadiah yang di-generasi, pemanfaatan fungsi hadiah, sistem dialog berorientasi tugas, belajar-ke-peringkat
Kode: Resmi
Pembelajaran Preferensi Terbalik: RL berbasis preferensi tanpa fungsi hadiah
Joey Hejna, Dorsa Sadigh
Kata kunci: Pembelajaran preferensi terbalik, tanpa model hadiah
Kode: Resmi
Alpacafarm: Kerangka kerja simulasi untuk metode yang belajar dari umpan balik manusia
Yann Dubois, Chen Xuechen LI, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Kata kunci: rlhf, kerangka simulasi
Kode: Resmi
Optimasi peringkat preferensi untuk penyelarasan manusia
Lagu Feifan, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin LI, Houfeng Wang
Kata kunci: optimasi peringkat preferensi
Kode: Resmi
Optimasi preferensi permusuhan
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan Du
Kata kunci: RLHF, GAN, permainan permusuhan
Kode: Resmi
Pembelajaran Preferensi Iteratif dari Umpan Balik Manusia: Menjembatani Teori dan Praktek untuk RLHF di bawah KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Kata kunci: RLHF, DPO iteratif, Yayasan Matematika
Contoh pembelajaran penguatan yang efisien dari umpan balik manusia melalui eksplorasi aktif
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
Kata kunci: RLHF, kemanjuran sampel, eksplorasi
Pembelajaran Penguatan dari Umpan Balik Statistik: Perjalanan dari Pengujian AB ke Pengujian Semut
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Kata kunci: RLHF, AB Testing, RLSF
Analisis dasar kemampuan model hadiah untuk secara akurat menganalisis model dasar di bawah shift distribusi
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
Kata kunci: rlhf, ood, shift distribusi
Penyelarasan data-efisien dari model bahasa besar dengan umpan balik manusia melalui bahasa alami
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Kata kunci: RLHF, efisien data, penyelarasan
Mari kita perkuat langkah demi langkah
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Kata kunci: rlhf, penalaran
Optimasi kebijakan berbasis preferensi langsung tanpa pemodelan hadiah
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, Hyun Oh Song
Kata kunci: RLHF tanpa pemodelan hadiah, pembelajaran kontras, pembelajaran refinforsi offline
Aligndiff: Menyelaraskan beragam preferensi manusia melalui model difusi perilaku yang dapat disesuaikan
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao Mu, Yan Zheng, Yujing Hu, Tangjie LV, Fan Changjie, Zhipeng Hu
Kata kunci: rlhf, penyelarasan, model difusi
Eureka: Desain Hadiah Tingkat Manusia Melalui Pengodean Model Bahasa Besar
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-an Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, penggemar Linxi, Anima Anandkumar
Kata kunci: berbasis LLM, desain fungsi hadiah
Safe RLHF: Pembelajaran Penguatan yang Aman dari Umpan Balik Manusia
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Kata kunci: Sale RL, llm fine-Ture
Keragaman kualitas melalui umpan balik manusia
Li Ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Kata kunci: keragaman kualitas, model difusi
REMAX: Metode pembelajaran penguatan yang sederhana, efektif, dan efisien untuk menyelaraskan model bahasa besar
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Kata kunci: efisiensi komputasi, teknik reduksi varians
Menyetel model visi komputer dengan hadiah tugas
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Kata Kunci: Tuning Hadiah dalam Visi Komputer
Kebijaksanaan Hindsight Membuat Model Bahasa Pengikut Instruksi yang Lebih Baik
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
Kata Kunci: Instruksi Hindsight HELAGELING, SISTEM RLHF, Tidak Diperlukan Jaringan Nilai
Kode: Resmi
Bahasa menginstruksikan pembelajaran penguatan untuk koordinasi manusia-AI
Hengyuan Hu, Dorsa Sadigh
Kata kunci: Koordinasi manusia-AI, penyelarasan preferensi manusia, instruksi terkondisi RL
Menyelaraskan model bahasa dengan pembelajaran penguatan offline dari umpan balik manusia
Jian Hu, Li Tao, June Yang, Chandler Zhou
Kata kunci: Penyelarasan Berbasis Transformator Keputusan, Pembelajaran Penguatan Offline, Sistem RLHF
Optimasi peringkat preferensi untuk penyelarasan manusia
Lagu Feifan, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li dan Houfeng Wang
Kata kunci: penyelarasan preferensi manusia yang diawasi, ekstensi peringkat preferensi
Kode: Resmi
Bridging the Gap: Survei tentang Mengintegrasikan Umpan Balik (Manusia) untuk Generasi Bahasa Alami
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André Ft Martins, Tongshuang Wu, Graham Neubig, André Ft Martins, Tongshuang Wu, Graham Neubig, André Ft Martins, Tongshuang Wu, Graham Neubig, André Ft Martins, Tongshuang Wu, Graham Neubig, André Ft Martins,
Kata kunci: generasi bahasa alami, integrasi umpan balik manusia, formalisasi umpan balik dan taksonomi, penilaian umpan balik AI dan prinsip-prinsip
Laporan Teknis GPT-4
Openai
Kata kunci: model skala besar, multimodal, model transformerbasi, rlhf yang digunakan disempurnakan
Kode: Resmi
Dataset: Drop, Winogrande, Hellaswag, Arc, Humaneval, GSM8K, MMLU, Sejujurnya
RAFT: Hadiah Peringkat Finetuning untuk Alignment Model Yayasan Generatif
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
Kata kunci: penolakan pengambilan sampel finetuning, alternatif untuk PPO, model difusi
Kode: Resmi
RRHF: Peringkat Responses to Align Bahasa Model dengan Umpan Balik Manusia Tanpa Air Mata
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Kata kunci: Paradigma baru untuk RLHF
Kode: Resmi
Pembelajaran preferensi beberapa-shot untuk RL manusia-in-loop
Joey Hejna, Dorsa Sadigh
Kata kunci: Pembelajaran preferensi, pembelajaran interaktif, pembelajaran multi-tugas, memperluas kumpulan data yang tersedia dengan melihat RL manusia-in-the-loop
Kode: Resmi
Lebih baik menyelaraskan model teks-ke-gambar dengan preferensi manusia
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng LI
Kata kunci: model difusi, teks-ke-gambar, estetika
Kode: Resmi
Imagereward: Belajar dan mengevaluasi preferensi manusia untuk generasi teks-ke-gambar
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai LI, Ming Ding, Jie Tang, Yuxiao Dong
Kata kunci: RM Preferensi Manusia Teks-ke-Teks Umum, Mengevaluasi Model Generatif Teks-ke-Teks
Kode: Resmi
Dataset: Coco, DifusionDB
Menyelaraskan model teks-ke-gambar menggunakan umpan balik manusia
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
Kata kunci: Teks-ke-gambar, model difusi yang stabil, fungsi hadiah yang memprediksi umpan balik manusia
Visual Chatgpt: Berbicara, Menggambar dan Mengedit dengan Model Foundation Visual
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Kata kunci: model yayasan visual, chatgpt visual
Kode: Resmi
Model bahasa pretraining dengan preferensi manusia (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Kata kunci: pretraining, offline rl, transformator keputusan
Kode: Resmi
Menyelaraskan model bahasa dengan preferensi melalui finimalisasi f-divergensi (F-DPG)
Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Kata kunci: f-divergence, RL dengan penalti KL
Pembelajaran Penguatan Prinsip dengan Umpan Balik Manusia dari Perbandingan Pairwise atau K-Wise
Banghua Zhu, Jiantao Jiao, Michael I. Jordan
Kata kunci: Pesimistic MLE, Max-entropy IRL
Kapasitas untuk koreksi diri moral dalam model bahasa besar
Antropik
Kata kunci: Meningkatkan kemampuan koreksi diri moral dengan meningkatkan pelatihan RLHF
Dataset; BBQ
Apakah Penguatan Pembelajaran (Tidak) untuk Pemrosesan Bahasa Alami?: Tolok Ukur, Baseline, dan Blok Bangunan untuk Optimalisasi Kebijakan Bahasa Alami (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hananeh Hajishirzi, Yejin Choi
Kata kunci: Mengoptimalkan generator bahasa dengan RL, benchmark, algoritma RL performant
Kode: Resmi
Dataset: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQA, DailyDialog
Penskalaan Hukum untuk Opoptimisasi Model Hadiah
Leo Gao, John Schulman, Jacob Hilton
Kata kunci: model imbalan imbalan emas model proxy proxy, ukuran dataset, ukuran parameter kebijakan, bon, ppo
Meningkatkan penyelarasan agen dialog melalui penilaian manusia yang ditargetkan (Sparrow)
Amelia Glaese, Nat McAleese, Maja Trębacz, dkk.
Kata kunci: agen dialog pencarian informasi, memecah dialog yang baik menjadi aturan bahasa alami, DPC, berinteraksi dengan model untuk memperoleh pelanggaran aturan tertentu (penyelidikan permusuhan)
Dataset: Pertanyaan Alami, ELI5, Kualitas, Triviaqa, Winobia, BBQ
Model bahasa tim merah untuk mengurangi bahaya: metode, perilaku penskalaan, dan pelajaran yang dipetik
Deep Ganguli, Liane Lovitt, Jackson Kernion, dkk.
Kata kunci: Model Bahasa Tim Merah, Selidiki Perilaku Penskalaan, Baca Dataset Tim
Kode: Resmi
Perencanaan Dinamis dalam Dialog Terbuka Menggunakan Pembelajaran Penguatan
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpekektor, Craig Boutilier, Gal Elidan
Kata kunci: sistem dialog real-time, terbuka, memasangkan embedding ringkas dari keadaan percakapan berdasarkan model bahasa, CaQL, CQL, Bert
Quark: Pembuatan teks yang dapat dikendalikan dengan unturing yang diperkuat
Ximing Lu, Sean Welleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Kata kunci: Menyempurnakan model bahasa tentang sinyal tentang apa yang tidak boleh dilakukan, Transformer Keputusan, tuning LLM dengan PPO
Kode: Resmi
Dataset: WritingPrompts, SST-2, Wikuxt-103
Melatih asisten yang membantu dan tidak berbahaya dengan pembelajaran penguatan dari umpan balik manusia
Yuntao Bai, Andy Jones, Kamal Ndousse, dkk.
Kata kunci: Asisten yang tidak berbahaya, mode online, ketahanan pelatihan RLHF, deteksi OOD.
Kode: Resmi
Dataset: Triviaqa, Hellaswag, ARC, OpenBookQA, Lambada, Humaneval, MMLU, Truthfulqa
Model Bahasa Mengajar untuk Mendukung Jawaban Dengan Kutipan Terverifikasi (Gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat McAleese
Kata kunci: menghasilkan jawaban yang mengutip bukti spesifik, abstain untuk menjawab saat tidak yakin
Dataset: Pertanyaan Alami, ELI5, Kualitas, Sejujurnya
Model Bahasa Pelatihan untuk mengikuti instruksi dengan umpan balik manusia (Instruktur)
Long Ouyang, Jeff Wu, Xu Jiang, dkk.
Kata kunci: Model bahasa besar, align model bahasa dengan niat manusia
Kode: Resmi
Dataset: Sejujurnya, realtoxicitypromppts
AI Konstitusi: tidak berbahaya dari umpan balik AI
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, dkk.
Kata kunci: RL dari umpan balik AI (RLAIF), melatih asisten AI yang tidak berbahaya melalui pengungkapan diri, gaya rantai-dipikirkan, kontrol perilaku AI dengan lebih tepat
Kode: Resmi
Menemukan Perilaku Model Bahasa dengan Evaluasi Model yang ditulis
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, dkk.
Kata kunci: Secara otomatis menghasilkan evaluasi dengan LMS, lebih banyak RLHF membuat LM lebih buruk, evaluasi LM yang ditulis adalah kualitas tinggi
Kode: Resmi
Dataset: BBQ, Skema Winogender
Pemodelan hadiah non-markovian dari label lintasan melalui pembelajaran beberapa instance yang dapat ditafsirkan
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Kata kunci: pemodelan hadiah (RLHF), non-markovian, pembelajaran instance ganda, interpretabilitas
Kode: Resmi
WebGPT: Permintaan pertanyaan yang dibantu oleh browser dengan umpan balik manusia (WebGPT)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, dkk.
Kata kunci: Model Cari Web dan berikan referensi , Pembelajaran Imitasi, BC, Pertanyaan Bentuk Panjang
Dataset: ELI5, Triviaqa, Futlefulqa
Meringkas buku dengan umpan balik manusia
Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
Kata kunci: Model yang dilatih pada tugas kecil untuk membantu manusia mengevaluasi tugas yang lebih luas, BC
Dataset: Booksum, NarrativeQA
Meninjau kembali kelemahan pembelajaran penguatan untuk terjemahan mesin saraf
Samuel Kiegeland, Julia Kreutzer
Kata kunci: Keberhasilan gradien kebijakan adalah karena hadiah daripada bentuk distribusi output, terjemahan mesin, NMT, adaptasi domain
Kode: Resmi
Dataset: WMT15, IWSLT14
Belajar meringkas dari umpan balik manusia
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Kata kunci: Peduli tentang kualitas ringkasan, kehilangan pelatihan mempengaruhi perilaku model, model hadiah digeneralisasi ke set data baru
Kode: Resmi
Dataset: tl; dr, cnn/dm
Model bahasa yang menyempurnakan dari preferensi manusia
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Kata kunci: Hadiah pembelajaran untuk bahasa, teks berkelanjutan dengan sentimen positif, tugas ringkasan, deskriptif fisik
Kode: Resmi
Dataset: tl; dr, cnn/dm
Penyelarasan agen yang dapat diskalakan melalui pemodelan hadiah: arah penelitian
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Kata kunci: Masalah Penyelarasan Agen, Pelajari Hadiah dari Interaksi, Mengoptimalkan Hadiah Dengan RL, Pemodelan Hadiah Rekursif
Kode: Resmi
Env: Atari
Hadiah pembelajaran dari preferensi dan demonstrasi manusia di atari
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
Kata kunci: preferensi lintasan demonstrasi ahli masalah peretasan, kebisingan di label manusia
Kode: Resmi
Env: Atari
Deep Tamer: Agen Interaktif Membentuk di Ruang Negara Dimensi Tinggi
Garrett Warnell, Nicholas Waytowich, Vernon Lawern, Peter Stone
Kata kunci: keadaan dimensi tinggi, memanfaatkan input pelatih manusia
Kode: pihak ketiga
Env: Atari
Pembelajaran penguatan yang mendalam dari preferensi manusia
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
Kata kunci: Jelajahi tujuan yang didefinisikan dalam preferensi manusia antara pasangan segmentasi lintasan, pelajari hal yang lebih kompleks daripada umpan balik manusia
Kode: Resmi
Env: Atari, Mujoco
Pembelajaran interaktif dari umpan balik manusia yang bergantung pada kebijakan
James MacGlashan, Mark K Ho, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
Kata kunci: Keputusan dipengaruhi oleh kebijakan saat ini daripada umpan balik manusia, belajar dari umpan balik yang bergantung pada kebijakan yang konvergen ke optimal lokal
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: Pembelajaran Penguatan Mesin Gunung Berapi untuk LLM
Bytedance Seed Mlsys Team & Hku: Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Kata kunci: kerangka kerja RLHF yang fleksibel, efisien
Tugas: RLHF, tugas penalaran termasuk matematika dan kode.
OpenRlhf
OpenRlhf
Kata kunci: 70b, rlhf, deepspeed, ray, vllm
Tugas: Kerangka kerja RLHF yang mudah digunakan, dapat diskalakan, dan berkinerja tinggi (dukungan 70b+ tuning penuh & lora & mixtral & kto).
Palm + Rlhf - Pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociear Ashimine, Eric Alcaide
Kata kunci: transformer, arsitektur palem
Dataset: Enwik8
LM-Human-Preferensi
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
Kata kunci: Hadiah pembelajaran untuk bahasa, teks berkelanjutan dengan sentimen positif, tugas ringkasan, deskriptif fisik
Dataset: tl; dr, cnn/dm
mengikuti-instruksi-manusia-feedback
Long Ouyang, Jeff Wu, Xu Jiang, dkk.
Kata kunci: Model bahasa besar, align model bahasa dengan niat manusia
Dataset: RealtoxicityPrompts yang jujur
Transformer Reinforcement Learning (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, dkk.
Kata kunci: Latih LLM dengan RL, PPO, transformator
Tugas: Sentimen IMDB
Transformer Reinforcement Learning X (TRLX)
Jonathan Tow, Leandro von Werra, dkk.
Kata kunci: Kerangka kerja pelatihan terdistribusi, model bahasa berbasis T5, kereta LLM dengan RL, PPO, ILQL
Tugas: fine tuning llm dengan rl menggunakan fungsi hadiah yang disediakan atau dataset berlabel hadiah
RL4LMS (pustaka RL modular untuk menyempurnakan model bahasa untuk preferensi manusia)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hananeh Hajishirzi, Yejin Choi
Kata kunci: Mengoptimalkan generator bahasa dengan RL, benchmark, algoritma RL performant
Dataset: IMDB, Commongen, CNN Daily Mail, Totto, WMT-16 (en-de), NarrativeQA, DailyDialog
LAMDA-RLHF-PYTORCH
Phil Wang
Kata kunci: lamda, mekanisme perhatian
Tugas: Implementasi pra-pelatihan open-source dari makalah penelitian LAMDA Google di Pytorch
Textrl
Eric Lam
Kata kunci: Transformator Huggingface
Tugas: Pembuatan teks
Env: pfrl, gym
Minrlhf
Thomfoster
Kata kunci: PPO, perpustakaan minimal
Tugas: Tujuan Pendidikan
DEEK-CHAT DEEP
Microsoft
Kata kunci: Pelatihan RLHF yang terjangkau
Dromedaris
IBM
Kata kunci: Pengawasan manusia minimal, self-aligned
Tugas: Model bahasa yang selaras yang dilatih dengan pengawasan manusia minimal
FG-RLHF
Zeqiu Wu, Yushi Hu, Weijia Shi, dkk.
Kata kunci: RLHF berbutir halus, memberikan hadiah setelah setiap segmen, menggabungkan beberapa RM yang terkait dengan berbagai jenis umpan balik
Tugas: Kerangka kerja yang memungkinkan pelatihan dan pembelajaran dari fungsi penghargaan yang berbutir halus dalam kepadatan dan beberapa RMS-Safe-RLHF
Xuehai Pan, Ruiyang Sun, Jiaming Ji, dkk.
Kata kunci: Mendukung model pra-terlatih yang populer, dataset berlabel manusia besar, metrik multi-skala untuk verifikasi kendala keselamatan, parameter yang disesuaikan
Tugas: LLM yang selaras dengan nilai terbatas melalui RLHF yang aman
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, ganguli yang dalam
Kata kunci: Dataset preferensi manusia, data tim merah, ditulis mesin
Tugas: Dataset Sumber Terbuka untuk Data Preferensi Manusia Tentang Bantuan dan Tidak Berbahaya
Stanford Human Preferensi Dataset (SHP)
Ethayarajh, Kawin dan Zhang, Heidi dan Wang, Yizhong dan Jurafsky, Dan
Kata kunci: Dataset yang terjadi secara alami dan ditulis manusia, 18 bidang subjek yang berbeda
Tugas: dimaksudkan untuk digunakan untuk melatih model hadiah RLHF
Sumber prompt
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Kata kunci: Dataset Bahasa Inggris yang Didorong, Memetakan Contoh Data ke dalam Bahasa Alami
Tugas: toolkit untuk membuat, berbagi, dan menggunakan permintaan bahasa alami
Koleksi Sumber Daya Landasan Pengetahuan Struktur (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Kata kunci: landasan pengetahuan terstruktur
Tugas: Kumpulan dataset terkait dengan landasan pengetahuan terstruktur
Koleksi Flan
Longpre Shayne, Hou Le, Vu Tu et al.
Tugas: Koleksi mengkompilasi set data dari Flan 2021, P3, instruksi super-natural
Dataset RLHF-Reward
Yiting Xie
Kata kunci: Dataset yang ditulis mesin
WebGPT_Competaons
Openai
Kata kunci: Dataset yang ditulis manusia, menjawab pertanyaan bentuk panjang
Tugas: Latih model penjawaban pertanyaan yang panjang untuk selaras dengan preferensi manusia
ringkasan_from_feedback
Openai
Kata kunci: dataset yang ditulis manusia, ringkasan
Tugas: Latih model peringkasan agar selaras dengan preferensi manusia
Dahoas/sintetis-instruktur-GPTJ-pairwise
Dahoas
Kata kunci: dataset yang ditulis manusia, dataset sintetis
Penyelarasan Stabil - Pembelajaran Penyelarasan dalam Permainan Sosial
Ruibo Liu, Ruixin (Ray) Yang, Qiang Peng
Kata kunci: Data interaksi yang digunakan untuk pelatihan penyelarasan, dijalankan di Sandbox
Tugas: Latih pada data interaksi yang direkam dalam game sosial yang disimulasikan
Lima
Meta AI
Kata kunci: Tanpa RLHF, sedikit petunjuk dan tanggapan yang dikuratori dengan hati -hati
Tugas: Dataset Digunakan untuk Melatih Model Lima
[Openai] Chatgpt: Mengoptimalkan model bahasa untuk dialog
[Memeluk wajah] menggambarkan pembelajaran penguatan dari umpan balik manusia (RLHF)
[Zhihu] 通向 AGI 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : 现象与解释
[Zhihu] 中文 HH-rlhf 数据集上的 ppo 实践
[W&B terhubung sepenuhnya] Memahami Pembelajaran Penguatan dari Umpan Balik Manusia (RLHF)
[Deepmind] Belajar melalui umpan balik manusia
[Gagasan] 深入理解语言模型的突现能力
[NOTION] 拆解追溯 GPT-3.5 各项能力的起源
[GIST] Penguatan Model Bahasa
[YouTube] John Schulman - Penguatan Pembelajaran dari Umpan Balik Manusia: Kemajuan dan Tantangan
[OpenAI / ARIZE] Openai tentang Pembelajaran Penguatan dengan Umpan Balik Manusia
[Encord] Panduan untuk Penguatan Pembelajaran dari Umpan Balik Manusia (RLHF) untuk Visi Komputer
[Weixun Wang] Gambaran Umum RL (HF)+LLM
Turki
Tujuan kami adalah membuat repo ini lebih baik. Jika Anda tertarik untuk berkontribusi, silakan merujuk di sini untuk instruksi dalam kontribusi.
RLHF yang luar biasa dirilis di bawah lisensi Apache 2.0.


