scratchplot story generation
1.0.0
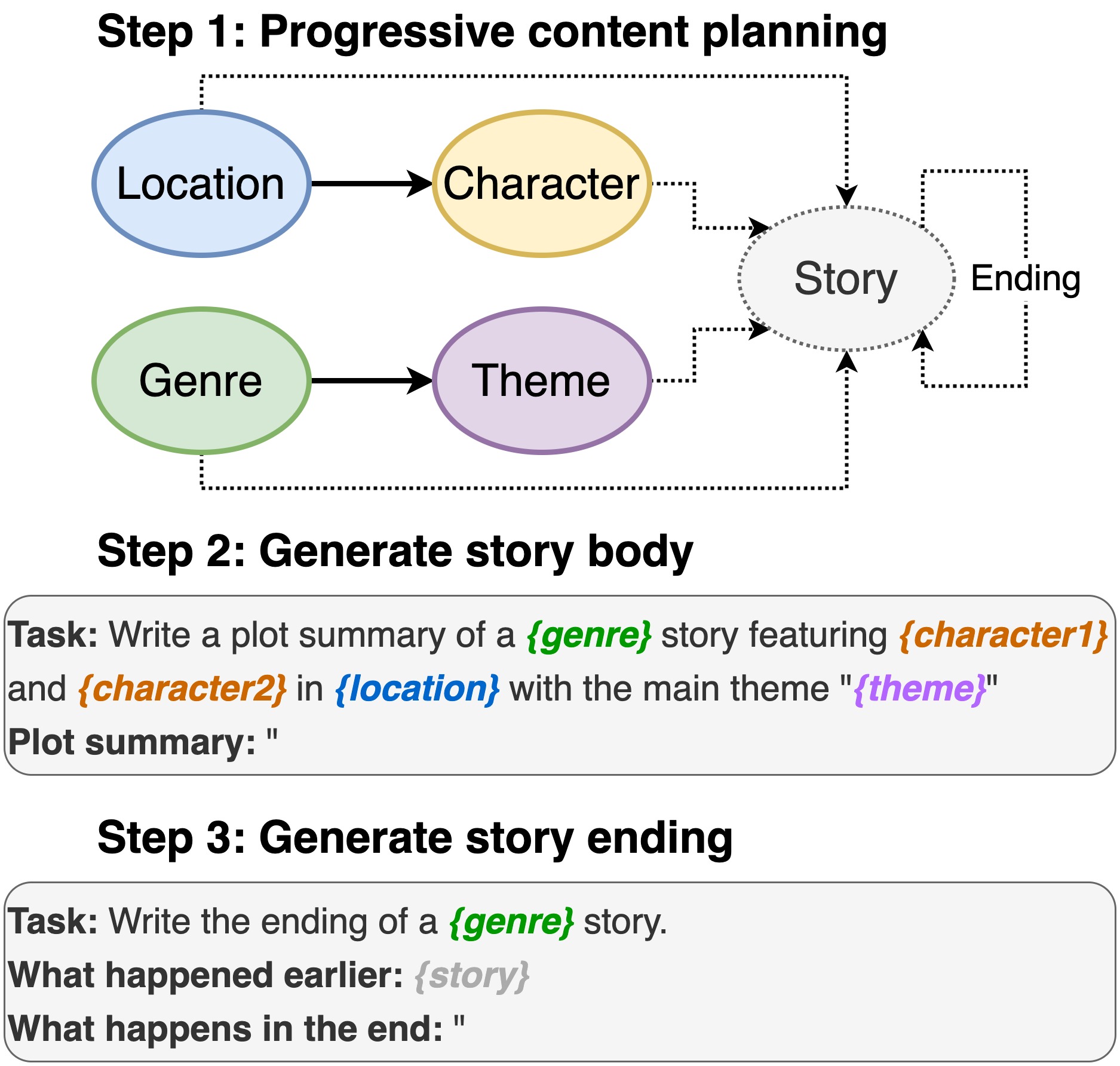
Repositori ini berisi kode untuk penulisan plot dari model bahasa pra-terlatih , untuk muncul di INLG 2022. Makalah ini memperkenalkan metode untuk pertama-tama meminta PLM untuk menyusun rencana konten. Kemudian, kami menghasilkan tubuh cerita dan berakhir dikondisikan pada rencana konten. Selain itu, kami mengambil pendekatan menghasilkan-dan-peringkat dengan menggunakan PLM tambahan untuk memberi peringkat pasangan (cerita, akhir) yang dihasilkan.
Repo ini sangat bergantung pada dino. Karena kami membuat beberapa perubahan kecil, kami menyertakan kode lengkap untuk kemudahan penggunaan.
Termasuk lokasi, gips, genre, dan tema.
sh run_plot_static_gpu.shElemen rencana konten dihasilkan sekali dan disimpan. Saat menghasilkan cerita, sistem sampel dari elemen plot yang dihasilkan offline.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda ke semua perintah yang memanggil dino.pyMembutuhkan python3. Diuji pada Python 3.6 dan 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Jika Anda menggunakan kode di repositori ini, silakan kutip makalah berikut:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Jika Anda menggunakan Dino untuk tugas -tugas lain, silakan juga mengutip kertas berikut:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


