OneForAll
1.0.0
Kertas: https://arxiv.org/abs/2310.00149
Penulis: Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, Muan Zhang
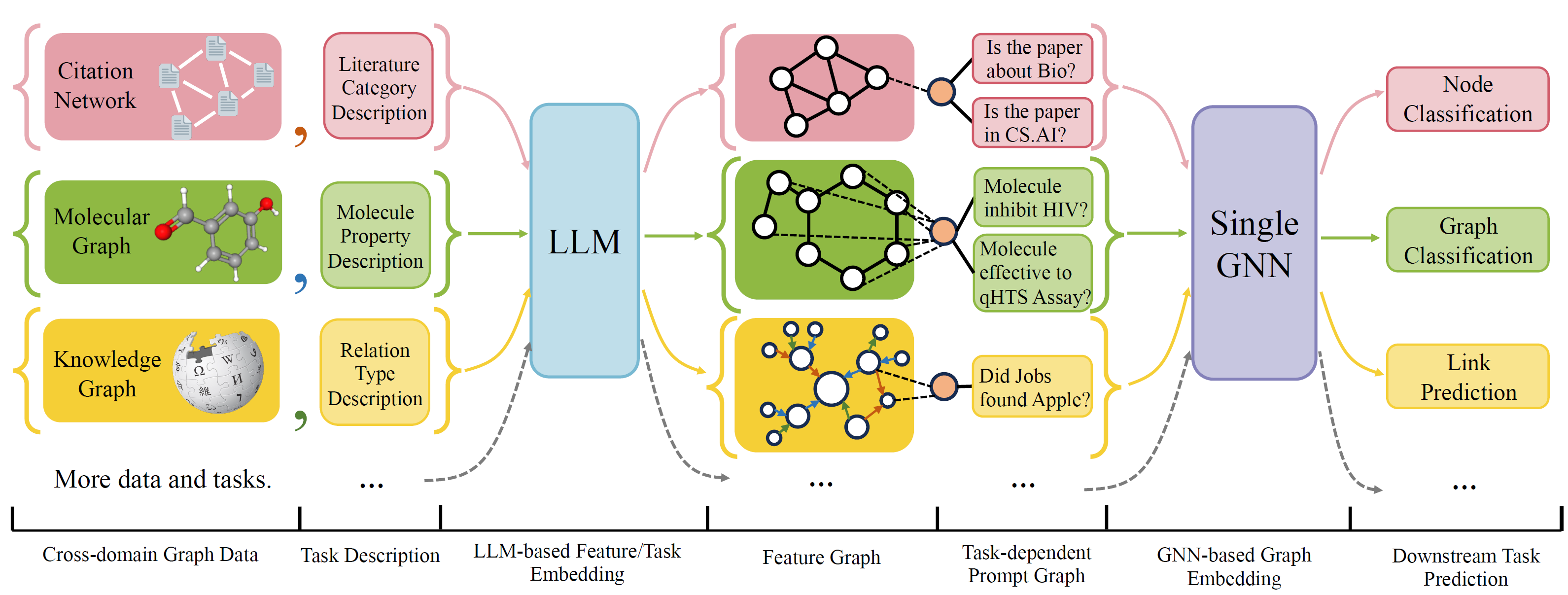
OFA adalah kerangka kerja klasifikasi grafik umum yang dapat memecahkan berbagai tugas klasifikasi grafik dengan model tunggal dan satu set parameter. Tugasnya adalah domain lintas (misalnya jaringan kutipan, grafik molekuler, ...) dan tugas silang (misalnya beberapa-shot, nol-shot, level grafik, level simpul, ...)
OFA menggunakan bahasa alami untuk menggambarkan semua grafik, dan menggunakan LLM untuk menanamkan semua deskripsi dalam ruang embedding yang sama, yang memungkinkan pelatihan lintas domain menggunakan model tunggal.
OFA mengusulkan paradiagma yang diminta bahwa semua informasi tugas dikonversi ke grafik yang cepat. Jadi model selanjutnya dapat membaca informasi tugas dan memprediksi target relavent sesuai, tanpa harus menyesuaikan parameter dan arsitektur model. Oleh karena itu, satu model dapat berupa silang.
OFA mengkuratori daftar dataset grafik dari sumber dan domain yang berbeda dan menggambarkan node/tepi dalam grafik dengan protokol dekriptan sistematis. Kami berterima kasih kepada karya -karya sebelumnya termasuk, OGB, Gimlet, Moleculenet, GraphllM, dan Villmow karena menyediakan data grafik/teks mentah yang indah yang memungkinkan pekerjaan kami.
OneForall menjalani revisi besar, di mana kami membersihkan kode dan memperbaiki beberapa bug yang dilaporkan. Pembaruan utamanya adalah:
Jika Anda sebelumnya menggunakan repositori kami, silakan tarik dan hapus file fitur/teks yang dihasilkan lama dan regenerate. Maaf atas ketidaknyamanannya.
Untuk menginstal persyaratan untuk proyek menggunakan conda:
conda env create -f environment.yml
Untuk percobaan end-to-end bersama pada semua dataset yang dikumpulkan, jalankan
python run_cdm.py --override e2e_all_config.yaml
Semua argumen dapat diubah dengan nilai yang terpisah ruang seperti
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
Pengguna dapat memodifikasi variabel task_names di ./e2e_all_config.yaml untuk mengontrol kumpulan data mana yang disertakan selama pelatihan. Panjang task_names , d_multiple , dan d_min_ratio harus sama. Mereka juga dapat ditentukan dalam argumen baris perintah dengan nilai yang dipisahkan koma.
misalnya
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
OFA-IND dapat ditentukan oleh
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
Untuk menjalankan percobaan beberapa shot dan nol-shot
python run_cdm.py --override lr_all_config.yaml
Kami mendefinisikan konfigurasi untuk setiap tugas, setiap konfigurasi tugas berisi beberapa konfigurasi dataset.
Konfigurasi tugas disimpan di ./configs/task_config.yaml . Tugas biasanya terdiri dari beberapa pemisahan set data (tidak harus set data yang sama). Misalnya, tugas klasifikasi node cora end-to-end reguler akan memiliki perpecahan kereta dari dataset CORA sebagai dataset kereta api, perpecahan yang valid dari dataset CORA sebagai salah satu dataset yang valid, dan juga untuk pemisahan tes. Anda juga dapat memiliki lebih banyak validasi/tes dengan menentukan perpecahan kereta CORA sebagai salah satu dataset validasi/pengujian. Secara khusus, konfigurasi tugas terlihat seperti
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split Konfigurasi dataset disimpan di ./configs/task_config.yaml . Konfigurasi dataset mendefinisikan bagaimana dataset dibangun. Secara khusus,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 Jika Anda menerapkan dataset seperti Cora/PubMed/Arxiv, kami sarankan menambahkan direktori data Anda $ customized_data $ di bawah data/single_graph/$ customized_data $ dan mengimplementasikan gen_data.py di bawah direktori, Anda dapat menggunakan data/cora/gen_data. PY sebagai contoh.
Setelah data dibangun, Anda perlu mendaftarkan nama dataset Anda di sini, dan mengimplementasikan splitter seperti di sini. Jika Anda melakukan tugas zero-shot/beberapa-shot, Anda juga dapat membuat split zero-shot/beberapa-shot di sini juga.
Terakhir, daftarkan entri konfigurasi di konfigurasi/data_config.yaml. Misalnya, untuk klasifikasi simpul ujung ke ujung
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$Proses_label_func mengonversi label target menjadi label biner, dan mengubah embedding kelas jika tugasnya adalah nol-shot/beberapa-shot, di mana jumlah simpul kelas tidak diperbaiki. Daftar Process_Label_Func AvALAILABLY ada di sini. Dibutuhkan di semua kelas yang menanamkan dan label yang benar. Outputnya adalah tuple: (label, class_node_embedding, label biner/satu-panas).
Jika Anda ingin lebih banyak fleksibilitas, maka menambahkan kumpulan data yang disesuaikan memerlukan implementasi subkelas yang disesuaikan dari OfapyGDataSet. Template ada di sini:
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

