text embeddings inference
v1.5.1
Solusi inferensi cepat menyala untuk model embeddings teks.
Benchmark untuk baai/bge-base-en-v1.5 pada nvidia A10 dengan panjang urutan 512 token:
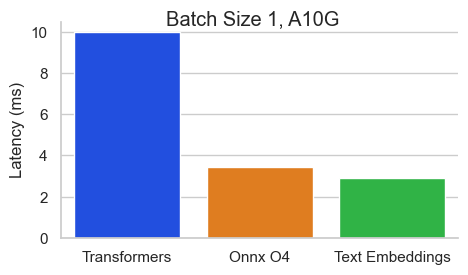
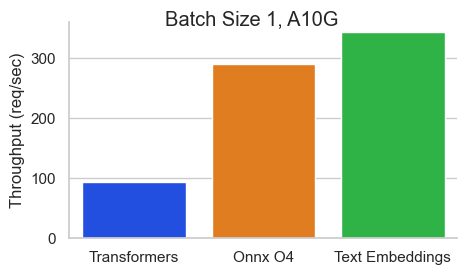
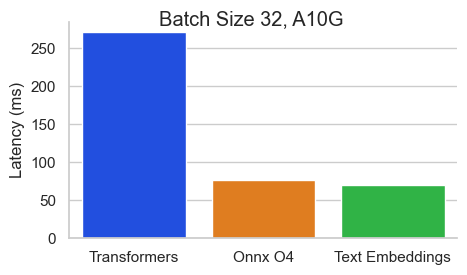
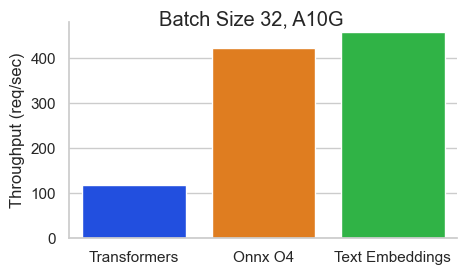
Text Embeddings Inference (TEI) adalah toolkit untuk menggunakan dan melayani embeddings teks open source dan model klasifikasi urutan. TEI memungkinkan ekstraksi kinerja tinggi untuk model yang paling populer, termasuk Flagembedding, Ember, GTE dan E5. TEI mengimplementasikan banyak fitur seperti:
Inferensi Teks Embeddings saat ini mendukung model Nomic, Bert, Camembert, XLM-Roberta dengan posisi absolut, model Jinabert dengan posisi alibi dan model Mistral, Alibaba GTE dan QWEN2 dengan posisi tali.
Di bawah ini adalah beberapa contoh model yang saat ini didukung:
| Peringkat mteb | Ukuran model | Tipe model | ID Model |
|---|---|---|---|
| 1 | 7b (sangat mahal) | Mistral | Salesforce/SFR-Embedding-2_r |
| 2 | 7b (sangat mahal) | Qwen2 | Alibaba-nlp/gte-qwen2-7b-instruct |
| 9 | 1.5b (mahal) | Qwen2 | Alibaba-nlp/gte-qwen2-1.5b-instruct |
| 15 | 0.4b | Alibaba GTE | Alibaba-nlp/gte-large-en-v1.5 |
| 20 | 0.3b | Bert | Whereisai/uae-large-v1 |
| 24 | 0,5b | XLM-Roberta | Intfloat/Multilingual-E5-Large-Instruct |
| N/a | 0.1b | Nomicbert | nomic-ai/nomic-embed-text-v1 |
| N/a | 0.1b | Nomicbert | nomic-ai/nomic-embed-text-v1.5 |
| N/a | 0.1b | Jinabert | jinaai/jina-embeddings-v2-base-en |
| N/a | 0.1b | Jinabert | jinaai/jina-embeddings-v2-base-code |
Untuk menjelajahi daftar model embeddings teks berkinerja terbaik, kunjungi papan peringkat masif teks menonjol (MTEB).
Inferensi Teks Embeddings saat ini mendukung model klasifikasi urutan XLM-Roberta dengan posisi absolut.
Di bawah ini adalah beberapa contoh model yang saat ini didukung:
| Tugas | Tipe model | ID Model |
|---|---|---|
| Peringkat ulang | XLM-Roberta | BAAI/BGE-RERANKER-Large |
| Peringkat ulang | XLM-Roberta | BAAI/BGE-BASE-BASE |
| Peringkat ulang | Gte | Alibaba-nlp/gte-multipiling-reranker-base |
| Analisis sentimen | Roberta | Samlowe/Roberta-Base-go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelDan kemudian Anda dapat membuat permintaan seperti
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'Catatan: Untuk menggunakan GPU, Anda perlu menginstal NVIDIA Container Toolkit. Driver NVIDIA pada mesin Anda harus kompatibel dengan CUDA versi 12.2 atau lebih tinggi.
Untuk melihat semua opsi untuk melayani model Anda:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
Teks Embeddings Inference dikirimkan dengan beberapa gambar Docker yang dapat Anda gunakan untuk menargetkan backend tertentu:
| Arsitektur | Gambar |
|---|---|
| CPU | ghcr.io/huggingface/text-embeddings-inference:cpu-1.5 |
| Volta | Tidak didukung |
| Turing (T4, Seri RTX 2000, ...) | ghcr.io/huggingface/text-embeddings-inference:turing-1.5 (eksperimental) |
| Ampere 80 (A100, A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| Ampere 86 (A10, A40, ...) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace (seri RTX 4000, ...) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| Hopper (H100) | ghcr.io/huggingface/text-embeddings-inference:hopper-1.5 (eksperimental) |
Peringatan : Perhatian flash dimatikan secara default untuk gambar Turing karena menderita masalah presisi. Anda dapat menyalakan perhatian Flash V1 dengan menggunakan variabel lingkungan USE_FLASH_ATTENTION=True Environment.
Anda dapat berkonsultasi dengan dokumentasi OpenAPI dari text-embeddings-inference REST API menggunakan rute /docs . UI Swagger juga tersedia di: https://huggingface.github.io/text-embeddings-inference.
Anda memiliki opsi untuk memanfaatkan variabel lingkungan HF_API_TOKEN untuk mengonfigurasi token yang digunakan oleh text-embeddings-inference . Ini memungkinkan Anda untuk mendapatkan akses ke sumber daya yang dilindungi.
Misalnya:
HF_API_TOKEN=<your cli READ token>Atau dengan Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelUntuk menggunakan Inferensi Embeddings Teks di Lingkungan Berkerut Udara, pertama-tama unduh bobot dan kemudian pasang di dalam wadah menggunakan volume.
Misalnya:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 Dukungan tambahan untuk model Camembert, Roberta, XLM-Roberta, dan GTE urutan Klasifikasi. Model peringkat ulang adalah model cross-encoders klasifikasi urutan dengan kelas tunggal yang mencetak kesamaan antara kueri dan teks.
Lihat blogpost ini oleh tim llamaindex untuk memahami bagaimana Anda dapat menggunakan model peringkat ulang dalam pipa kain Anda untuk meningkatkan kinerja hilir.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelDan kemudian Anda dapat memberi peringkat kesamaan antara kueri dan daftar teks dengan:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' Anda juga dapat menggunakan model klasifikasi urutan klasik seperti SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model Setelah Anda menggunakan model, Anda dapat menggunakan titik akhir predict untuk mendapatkan emosi yang paling terkait dengan input:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Anda dapat memilih untuk mengaktifkan Pooling Splade untuk Arsitektur Bert dan Distilbert Maskedlm:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade Setelah Anda menggunakan model, Anda dapat menggunakan titik akhir /embed_sparse untuk mendapatkan embedding yang jarang:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference diinstrumentasi dengan penelusuran terdistribusi menggunakan opentelemetry. Anda dapat menggunakan fitur ini dengan mengatur alamat ke kolektor OTLP dengan argumen --otlp-endpoint .
text-embeddings-inference menawarkan API GRPC sebagai alternatif dari HTTP API default untuk penyebaran kinerja tinggi. Definisi protobuf API dapat ditemukan di sini.
Anda dapat menggunakan API GRPC dengan menambahkan tag -grpc ke gambar TEI Docker apa pun. Misalnya:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed Anda juga dapat memilih untuk menginstal text-embeddings-inference secara lokal.
Pertama pasang karat:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shKemudian jalankan:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalAnda sekarang dapat meluncurkan Inferensi Embeddings Teks di CPU dengan:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Catatan: Pada beberapa mesin, Anda mungkin juga memerlukan perpustakaan OpenSSL dan GCC. Di mesin Linux, jalankan:
sudo apt-get install libssl-dev gcc -yGPU dengan kemampuan komputasi CUDA <7,5 tidak didukung (V100, Titan V, GTX 1000 Series, ...).
Pastikan Anda memasang CUDA dan NVIDIA Drivers. Driver NVIDIA di perangkat Anda harus kompatibel dengan CUDA versi 12.2 atau lebih tinggi. Anda juga perlu menambahkan binari nvidia ke jalan Anda:
export PATH= $PATH :/usr/local/cuda/binKemudian jalankan:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresAnda sekarang dapat meluncurkan Inferensi Embeddings Teks di GPU dengan:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Anda dapat membangun wadah CPU dengan:
docker build .Untuk membangun wadah CUDA, Anda perlu mengetahui tutup komputasi GPU yang akan Anda gunakan saat runtime.
Kemudian Anda dapat membangun wadah dengan:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capSeperti yang dijelaskan di sini-siap, gambar Docker ARM64, Metal / MPS tidak didukung melalui Docker. Karena kesimpulan seperti itu akan terikat CPU dan kemungkinan besar cukup lambat saat menggunakan gambar Docker ini pada CPU lengan M1/M2.
docker build . -f Dockerfile --platform=linux/arm64


