pytorch openai transformer lm
1.0.0
Ini adalah implementasi Pytorch dari kode TensorFlow yang dilengkapi dengan makalah Openai "meningkatkan pemahaman bahasa dengan pra-pelatihan generatif" oleh Alec Radford, Karthik Narasimhan, Tim Salimans dan Ilya Sutskever.
Implementasi ini terdiri dari skrip untuk memuat dalam model pytorch bobot yang telah dilatih oleh penulis dengan implementasi TensorFlow.
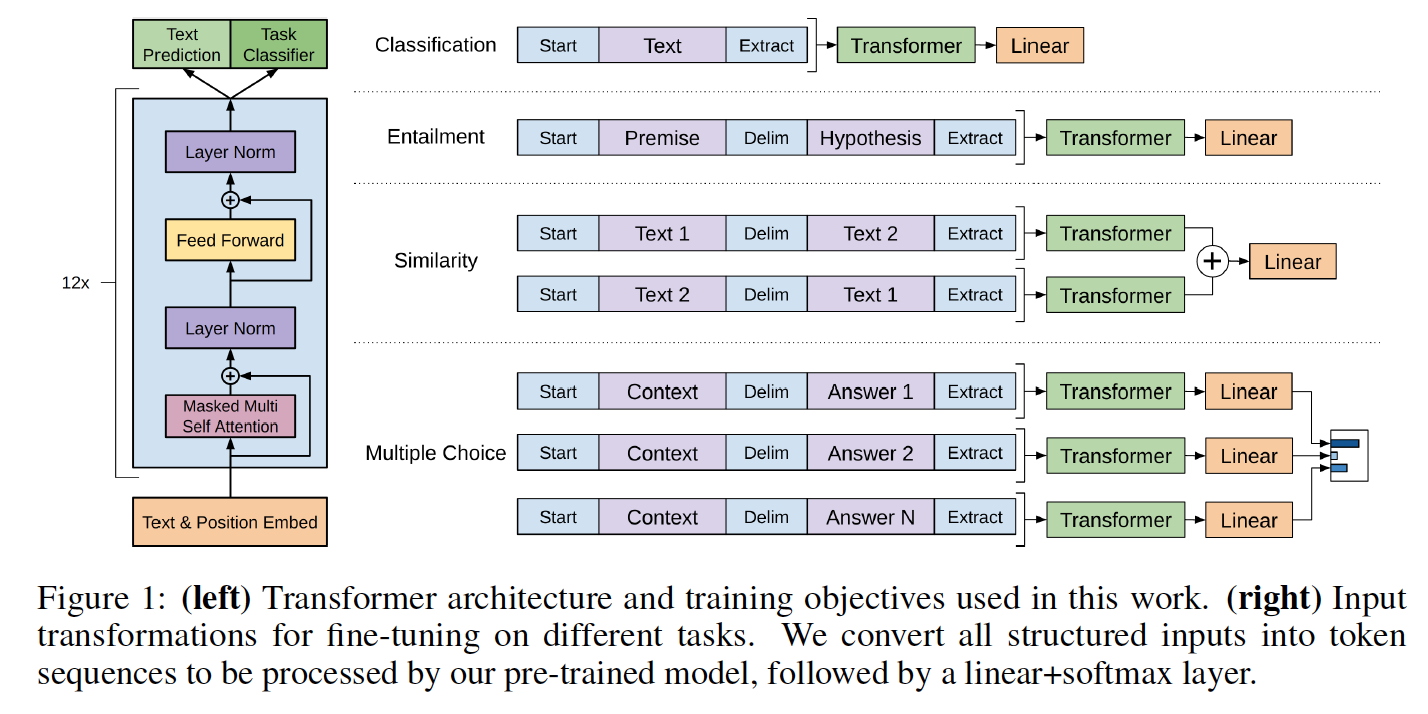
Kelas model dan skrip pemuatan terletak di model_pytorch.py.
Nama -nama modul dalam model Pytorch mengikuti nama -nama variabel dalam implementasi TensorFlow. Implementasi ini mencoba mengikuti kode asli sedekat mungkin untuk meminimalkan perbedaan.
Implementasi ini dengan demikian juga terdiri dari algoritma optimasi ADAM yang dimodifikasi seperti yang digunakan dalam makalah Openai dengan:
Untuk menggunakan model IT-self dengan mengimpor model_pytorch.py, Anda hanya perlu:
Untuk menjalankan skrip pelatihan classifier di train.py yang Anda perlukan selain:
Anda dapat mengunduh bobot versi pra-terlatih Openai dengan mengkloning repo Alec Radford dan menempatkan folder model yang berisi bobot terlatih dalam repo ini.
Model ini dapat digunakan sebagai model bahasa transformator dengan bobot pra-terlatih Openai sebagai berikut:
from model_pytorch import TransformerModel , load_openai_pretrained_model , DEFAULT_CONFIG
args = DEFAULT_CONFIG
model = TransformerModel ( args )
load_openai_pretrained_model ( model ) Model ini menghasilkan status tersembunyi Transformer. Anda dapat menggunakan kelas LMHead di model_pytorch.py untuk menambahkan decoder yang diikat dengan bobot encoder dan mendapatkan model bahasa lengkap. Anda juga dapat menggunakan kelas ClfHead di model_pytorch.py untuk menambahkan classifier di atas transformator dan mendapatkan classifier seperti yang dijelaskan dalam publikasi OpenAI. (Lihat contoh keduanya dalam fungsi __main__ dari train.py)
Untuk menggunakan encoder posisi transformator, Anda harus menyandikan dataset menggunakan fungsi encode_dataset() dari utils.py. Silakan merujuk ke awal fungsi __main__ di train.py untuk melihat bagaimana mendefinisikan dengan benar kosa kata dan menyandikan dataset Anda.
Model ini juga dapat diintegrasikan dalam classifier sebagaimana dirinci dalam makalah Openai. Contoh penyesuaian pada tugas rocstories cloze disertakan dengan kode pelatihan di train.py
Dataset Rocstories dapat diunduh dari situs web terkait.
Seperti halnya kode TensorFlow, kode ini mengimplementasikan hasil uji cloze rocstories yang dilaporkan dalam makalah yang dapat direproduksi dengan menjalankan:
python -m spacy download en
python train.py --dataset rocstories --desc rocstories --submit --analysis --data_dir [path to data here]Finetuning Model Pytorch untuk 3 zaman pada rocstories membutuhkan waktu 10 menit untuk dijalankan pada NVIDIA K-80 tunggal.
Akurasi pengujian lari tunggal dari versi Pytorch ini adalah 85,84%, sementara penulis melaporkan akurasi median dengan kode TensorFlow 85,8%dan kertas melaporkan akurasi lari tunggal terbaik sebesar 86,5%.
Implementasi penulis menggunakan 8 GPU dan dengan demikian dapat mengakomodasi batch 64 sampel sementara implementasi saat ini adalah GPU tunggal dan akibatnya terbatas pada 20 contoh pada K80 karena alasan memori. Dalam pengujian kami, meningkatkan ukuran batch dari 8 menjadi 20 sampel meningkatkan akurasi pengujian sebesar 2,5 poin. Akurasi yang lebih baik dapat diperoleh dengan menggunakan pengaturan multi-GPU (belum dicoba).
SOTA sebelumnya pada dataset Rocstories adalah 77,6% ("model koherensi tersembunyi" dari Chaturvedi et al. Diterbitkan dalam "Cerita Pemahaman untuk Memprediksi Apa yang terjadi selanjutnya" EMNLP 2017, yang merupakan makalah yang sangat bagus juga!)


