rag experiment accelerator
1.0.0
Akselerator Eksperimen Rag adalah alat serbaguna yang membantu Anda melakukan eksperimen dan evaluasi menggunakan pencarian AIure AI dan pola kain. Dokumen ini memberikan panduan komprehensif yang mencakup semua yang perlu Anda ketahui tentang alat ini, seperti tujuan, fitur, instalasi, penggunaan, dan banyak lagi.
Tujuan utama dari akselerator eksperimen kain adalah untuk membuatnya lebih mudah dan lebih cepat untuk menjalankan eksperimen dan evaluasi kueri pencarian dan kualitas respons dari Openai. Alat ini berguna bagi para peneliti, ilmuwan data, dan pengembang yang ingin:
18 Maret 2024: Pengambilan sampel konten telah ditambahkan. Fungsionalitas ini akan memungkinkan dataset untuk disampel dengan persentase yang ditentukan. Data dikelompokkan oleh konten dan kemudian persentase sampel diambil di setiap cluster untuk mencoba bahkan distribusi data sampel.
Ini dilakukan untuk memastikan hasil yang representatif dalam sampel yang akan terjadi di seluruh dataset.
Catatan : Disarankan untuk membangun kembali lingkungan Anda jika Anda telah menggunakan alat ini sebelumnya karena dependensi baru.
Akselerator Eksperimen Rag digerakkan oleh Config dan menawarkan serangkaian fitur yang kaya untuk mendukung tujuannya:
Pengaturan Eksperimen : Anda dapat mendefinisikan dan mengonfigurasi percobaan dengan menentukan berbagai parameter mesin pencari, jenis pencarian, set kueri, dan metrik evaluasi.
Integrasi : Ini terintegrasi dengan mulus dengan pencarian AIure AI, Azure Machine Learning, MLFLOW dan Azure Openai.
Indeks Pencarian Rich : Ini membuat beberapa indeks pencarian berdasarkan konfigurasi hiperparameter yang tersedia di file config.
Multiple Document Loader : Alat ini mendukung beberapa loader dokumen, termasuk pemuatan melalui Azure Document Intelligence dan Langchain Loader dasar. Ini memberi Anda fleksibilitas untuk bereksperimen dengan metode ekstraksi yang berbeda dan mengevaluasi keefektifannya.
Kustom Document Intelligence Loader : Saat memilih model API 'prebuilt-layout' untuk intelijen dokumen, alat ini menggunakan loader intelijen dokumen khusus untuk memuat data. Loader kustom ini mendukung pemformatan tabel dengan header kolom menjadi pasangan nilai kunci (untuk meningkatkan keterbacaan untuk LLM), tidak termasuk bagian-bagian yang tidak relevan dari file untuk LLM (seperti nomor halaman dan footer), menghilangkan pola berulang dalam file menggunakan Regex, dan banyak lagi. Karena setiap baris tabel diubah menjadi garis teks, untuk menghindari memecahkan barisan di tengah, chunking dilakukan secara rekursif berdasarkan paragraf dan garis. Model API 'prebuilt-layout' yang lebih sederhana ke fallback ketika 'prebuilt-layout' gagal. Model API lainnya akan memanfaatkan implementasi Langchain, yang mengembalikan respons mentah dari API Intelijen Dokumen.
Generasi Kueri : Alat ini dapat menghasilkan berbagai set kueri yang beragam dan dapat disesuaikan, yang dapat disesuaikan untuk kebutuhan eksperimen tertentu.
Beberapa jenis pencarian : Ini mendukung beberapa jenis pencarian, termasuk teks murni, vektor murni, vektor lintas-vektor, multi-vektor, hibrida, dan banyak lagi. Ini memberi Anda kemampuan untuk melakukan analisis komprehensif tentang kemampuan dan hasil pencarian.
Sub-Querying : Pola mengevaluasi kueri pengguna dan jika merasa cukup kompleks, ia memecahnya menjadi sub-kueri yang lebih kecil untuk menghasilkan konteks yang relevan.
Peringkat ulang : Respons kueri dari pencarian AZure AI dievaluasi kembali menggunakan LLM dan peringkat sesuai dengan relevansi antara kueri dan konteksnya.
Metrik dan Evaluasi : Ini mendukung metrik end-to-end yang membandingkan jawaban yang dihasilkan (aktual) dengan jawaban kebenaran tanah (diharapkan), termasuk metrik kesamaan berbasis jarak, cosinus dan semantik. Ini juga termasuk metrik berbasis komponen untuk menilai kinerja pengambilan dan generasi menggunakan LLMS sebagai juri, seperti penarikan kembali konteks atau relevansi jawaban, serta metrik pengambilan untuk menilai hasil pencarian (misalnya peta@k).
Generasi Laporan : Akselerator Eksperimen Rag mengotomatiskan proses pembuatan laporan, lengkap dengan visualisasi yang memudahkan untuk menganalisis dan berbagi temuan eksperimen.
Multi-bahasa : Alat ini mendukung penganalisa bahasa untuk dukungan linguistik pada bahasa individu dan analisis khusus (agnostik-bahasa) untuk pola yang ditentukan pengguna pada indeks pencarian. Untuk informasi lebih lanjut, lihat jenis analisis.
Sampling : Jika Anda memiliki dataset besar dan/atau ingin mempercepat eksperimen, proses pengambilan sampel tersedia untuk membuat sampel data yang kecil namun representatif untuk persentase yang ditentukan. Data akan dikelompokkan oleh konten dan persentase dari masing -masing cluster akan dipilih sebagai bagian dari sampel. Hasil yang diperoleh harus secara kasar menunjukkan dataset penuh dalam margin ~ 10%. Setelah pendekatan telah diidentifikasi, berjalan pada dataset lengkap direkomendasikan untuk hasil yang akurat.
Saat ini, akselerator eksperimen kain dapat dijalankan secara lokal memanfaatkan salah satu dari yang berikut:
Menggunakan wadah pengembangan akan berarti bahwa semua perangkat lunak yang diperlukan diinstal untuk Anda. Ini akan membutuhkan WSL. Untuk informasi lebih lanjut tentang wadah pengembangan, kunjungi wadah.dev
Instal perangkat lunak berikut pada mesin host Anda akan melakukan penyebaran dari:
- Untuk Windows - Windows Store Ubuntu 22.04.3 LTS
- Desktop Docker
- Kode Studio Visual
- Ekstensi Kode VS: Remote-Containers
Bimbingan lebih lanjut tentang pengaturan WSL dapat ditemukan di sini. Sekarang Anda memiliki prasyarat, Anda bisa:
git clone https://github.com/microsoft/rag-experiment-accelerator.git
code .Setelah proyek dibuka di vScode, itu harus menanyakan apakah Anda ingin "membuka kembali ini dalam wadah pengembangan". Katakan ya.
Anda tentu saja dapat menjalankan akselerator eksperimen kain pada mesin Windows/Mac jika Anda suka; Anda bertanggung jawab untuk menginstal alat yang benar. Ikuti langkah -langkah instalasi ini:
git clone https://github.com/microsoft/rag-experiment-accelerator.gitconda create -n rag-experiment python=3.11
conda init bashTutup terminal Anda, buka yang baru, dan jalankan:
conda activate rag-experiment
pip install .az login
az account set --subscription= " <your_subscription_guid> "
az account showAda 3 opsi untuk menginstal semua layanan Azure yang diperlukan:
Proyek ini mendukung pengembang Azure CLI.
azd provisionazd up jika Anda lebih suka karena ini memanggil azd provision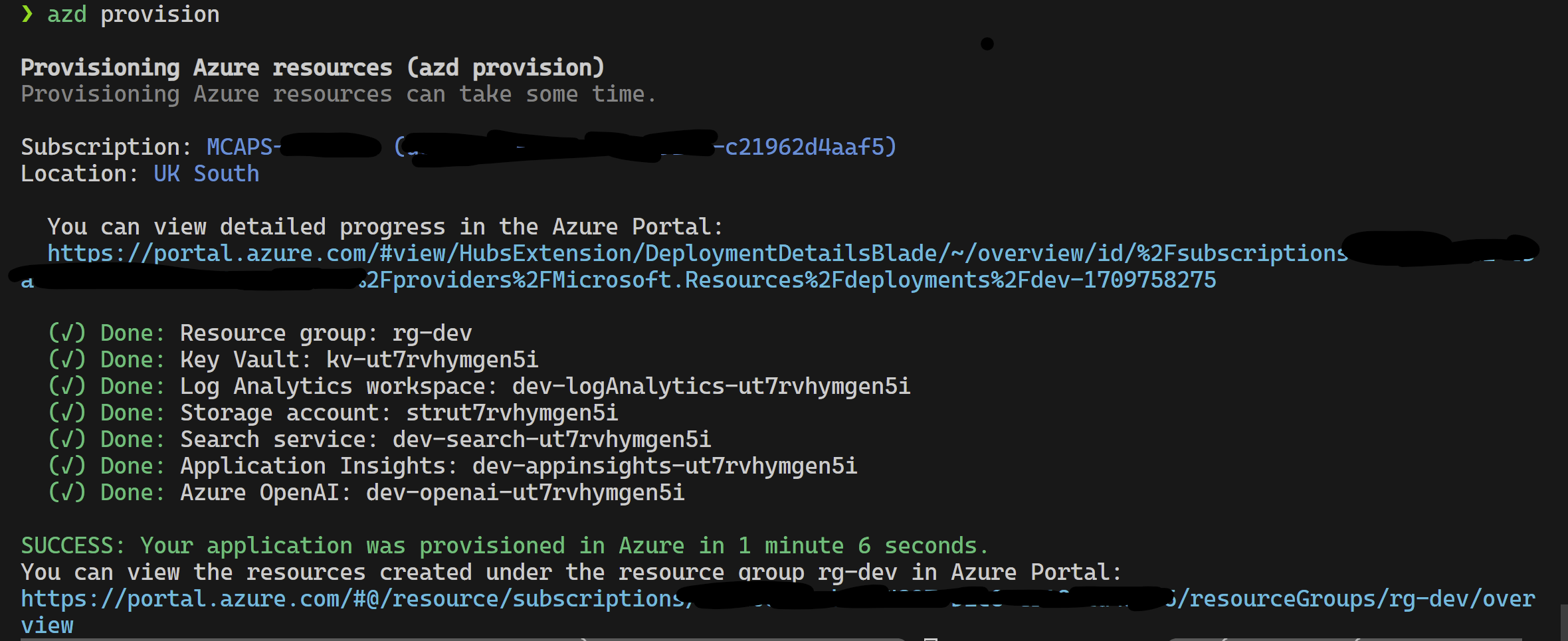
Setelah ini selesai, Anda dapat menggunakan konfigurasi peluncuran untuk dijalankan, atau men -debug 4 langkah dan lingkungan saat ini yang disediakan oleh azd akan dimuat dengan nilai yang benar.
Jika Anda ingin menggunakan infrastruktur sendiri dari template, Anda juga dapat mengklik di sini:
Jika Anda tidak ingin menggunakan azd Anda juga dapat menggunakan az CLI normal.
Gunakan perintah berikut untuk digunakan.
az login
az deployment sub create --subscription < subscription-id > --location < location > --template-file infra/main.bicepAtau
Untuk menggunakan perintah yang terisolasi menggunakan perintah berikut. Ganti nilai parameter dengan spesifik jaringan terisolasi Anda. Anda harus menyediakan ketiga parameter (yaitu vnetAddressSpace , proxySubnetAddressSpace dan subnetAddressSpace ) jika Anda ingin menggunakan jaringan yang terisolasi.
az login
az deployment sub create --location < location > --template-file infra/main.bicep
--parameters vnetAddressSpace= < vnet-address-space >
--parameters proxySubnetAddressSpace= < proxy-subnet-address-space >
--parameters subnetAddressSpace= < azure-subnet-address-space >Berikut adalah contoh dengan nilai parameter:
az deployment sub create --location uksouth --template-file infra/main.bicep
--parameters vnetAddressSpace= ' 10.0.0.0/16 '
--parameters proxySubnetAddressSpace= ' 10.0.1.0/24 '
--parameters subnetAddressSpace= ' 10.0.2.0/24 ' Untuk menggunakan akselerator eksperimen kain secara lokal, ikuti langkah -langkah ini:
Salin file .env.template yang disediakan ke file bernama .env dan perbarui semua nilai yang diperlukan. Banyak nilai yang diperlukan untuk file .env akan berasal dari sumber daya yang sebelumnya telah dikonfigurasi dan/atau dapat dikumpulkan dari sumber daya yang disediakan di bagian Infrastruktur Provision. Juga perhatikan, secara default, LOGGING_LEVEL diatur ke INFO tetapi dapat diubah ke salah satu level berikut: NOTSET , DEBUG , INFO , WARN , ERROR , CRITICAL .
cp .env.template .env
# change parameters manually Salin file config.sample.json yang disediakan ke file bernama config.json dan ubah hyperparameters apa pun untuk disesuaikan dengan percobaan Anda.
cp config.sample.json config.json
# change parameters manually Salin file apa pun untuk konsumsi (pdf, html, markdown, teks, format JSON atau DOCX) ke dalam folder data .
Jalankan 01_index.py (python 01_index.py) untuk membuat indeks pencarian AIure AI dan memuat data ke dalamnya.
python 01_index.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Jalankan 02_qa_generation.py (Python 02_QA_Generation.py) untuk menghasilkan pasangan tanya jawab menggunakan azure openai.
python 02_qa_generation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-dd " The directory holding the data. Defaults to data "
-cf " JSON config filename. Defaults to config.json " Jalankan 03_querying.py (Python 03_Querying.py) untuk menanyakan pencarian Azure AI untuk menghasilkan konteks, memunculkan kembali item dalam konteks, dan mendapatkan respons dari Azure Openai menggunakan konteks baru.
python 03_querying.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Jalankan 04_evaluation.py (Python 04_evaluation.py) untuk menghitung metrik menggunakan berbagai metode dan menghasilkan grafik dan laporan dalam pembelajaran mesin Azure menggunakan integrasi MLFLOW.
python 04_evaluation.py
-d " The directory holding the configuration files and data. Defaults to current working directory "
-cf " JSON config filename. Defaults to config.json " Atau, Anda dapat menjalankan langkah -langkah di atas (terlepas dari 02_qa_generation.py ) menggunakan pipa Azure ML. Untuk melakukannya, ikuti panduan di sini.
Pengambilan sampel akan dijalankan secara lokal untuk membuat potongan data yang kecil namun representatif. Ini membantu dengan eksperimen yang cepat dan menekan biaya. Hasil yang diperoleh harus secara kasar menunjukkan dataset penuh dalam margin ~ 10%. Setelah pendekatan telah diidentifikasi, berjalan pada dataset lengkap direkomendasikan untuk hasil yang akurat.
Catatan : Pengambilan sampel hanya dapat dijalankan secara lokal, pada tahap ini tidak didukung pada cluster komputasi AML terdistribusi. Jadi prosesnya adalah menjalankan pengambilan sampel secara lokal dan kemudian menggunakan dataset sampel yang dihasilkan untuk dijalankan pada AML.
Jika Anda memiliki dataset yang sangat besar dan ingin menjalankan pendekatan yang serupa untuk mencicipi data, Anda dapat menggunakan implementasi terdistribusi dalam memori Pyspark dalam perangkat penemuan data untuk Microsoft Fabric atau Azure Synapse Analytics.
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"only_run_sampling" : " If set to true, this will only run the sampling step and will not create an index or any subsequent steps, use this if you want to build a small sampled dataset to run in AML " ,
"sample_percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 " ,
},Proses pengambilan sampel akan menghasilkan artefak berikut di direktori pengambilan sampel:
job_name yang berisi subset file yang diambil sampelnya, ini dapat ditentukan sebagai --data_dir argumen saat menjalankan seluruh proses pada AML.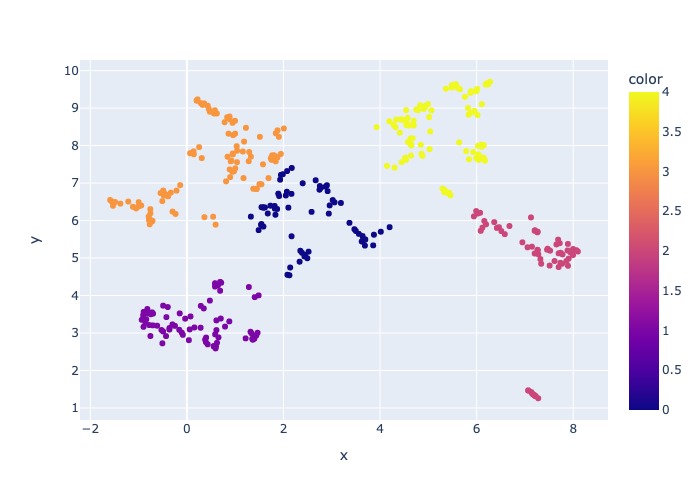
"optimum_k": auto diatur ke Auto, proses pengambilan sampel akan mencoba untuk mengatur jumlah cluster yang optimal secara otomatis. Ini dapat ditimpa jika Anda tahu kira -kira berapa banyak ember konten yang luas dalam data Anda. Grafik siku akan dihasilkan di folder pengambilan sampel. 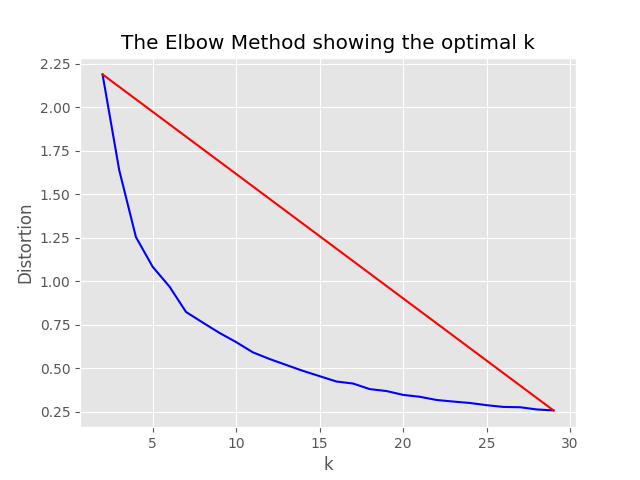
Ada dua opsi untuk menjalankan pengambilan sampel, yaitu:
Tetapkan nilai -nilai berikut untuk menjalankan proses pengindeksan secara lokal:
"sampling" : {
"sample_data" : true ,
"only_run_sampling" : false ,
"sample_percentage" : 10 ,
"optimum_k" : auto,
"min_cluster" : 2 ,
"max_cluster" : 30
}, Jika only_run_sampling nilai konfigurasi diatur ke true, ini hanya akan menjalankan langkah pengambilan sampel, tidak ada indeks yang akan dibuat dan langkah -langkah lain lainnya tidak akan dieksekusi. Atur argumen --data_dir ke direktori yang dibuat oleh proses pengambilan sampel yang akan menjadi:
artifacts/sampling/config.[job_name] dan jalankan langkah pipa AML.
Semua nilai dapat berupa daftar elemen. Termasuk konfigurasi bersarang. Setiap array akan menghasilkan kombinasi konfigurasi datar ketika metode flatten() dipanggil pada node tertentu, untuk memilih 1 kombinasi acak - panggil metode sample() .
{
"experiment_name" : " If provided, this will be the experiment name in Azure ML and it will group all job run under the same experiment, otherwise (if left empty) index_name_prefix will be used and there may be more than one experiment " ,
"job_name" : " If provided, all jobs runs in Azure ML will be named with this property value plus timestamp, otherwise (if left empty) each job with be named only with timestamp " ,
"job_description" : " You may provide a description for the current job run which describes in words what you are about to experiment with " ,
"data_formats" : " Specifies the supported data formats for the application. You can choose from a variety of formats such as JSON, CSV, PDF, and more. [*] - means all formats included " ,
"main_instruction" : " Defines the main instruction prompt coming with queries to LLM " ,
"use_checkpoints" : " A boolean. If true, enables use of checkpoints to load data and skip processing that was already done in previous executions. " ,
"index" : {
"index_name_prefix" : " Search index name prefix " ,
"ef_construction" : " ef_construction value determines the value of Azure AI Search vector configuration. " ,
"ef_search" : " ef_search value determines the value of Azure AI Search vector configuration. " ,
"chunking" : {
"preprocess" : " A boolean. If true, preprocess documents, split into smaller chunks, embed and enrich them, and finally upload documents chunks for retrieval into Azure Search Index. " ,
"chunk_size" : " Size of each chunk e.g. [500, 1000, 2000] " ,
"overlap_size" : " Overlap Size for each chunk e.g. [100, 200, 300] " ,
"generate_title" : " A boolean. If true, a title is generated for the chunk of content and an embedding is created for it " ,
"generate_summary" : " A boolean. If true, a summary is generated for the chunk of content and an embedding is created for it " ,
"override_content_with_summary" : " A boolean. If true, The chunk content is replaced with its summary " ,
"chunking_strategy" : " determines the chunking strategy. Valid values are 'azure-document-intelligence' or 'basic' " ,
"azure_document_intelligence_model" : " represents the Azure Document Intelligence Model. Used when chunking strategy is 'azure-document-intelligence'. When set to 'prebuilt-layout', provides additional features (see above) "
},
"embedding_model" : " see 'Description of embedding models config' below " ,
"sampling" : {
"sample_data" : " Set to true to enable sampling " ,
"percentage" : " Percentage of the document corpus to sample " ,
"optimum_k" : " Set to 'auto' to automatically determine the optimum cluster number or set to a specific value e.g. 15 " ,
"min_cluster" : " Used by the automated optimum cluster process, this is the minimum number of clusters e.g. 2 " ,
"max_cluster" : " Used by the automated optimum cluster process, this is the maximum number of clusters e.g. 30 "
}
},
"language" : {
"analyzer" : {
"analyzer_name" : " name of the analyzer to use for the field. This option can be used only with searchable fields and it can't be set together with either searchAnalyzer or indexAnalyzer. " ,
"index_analyzer_name" : " name of the analyzer used at indexing time for the field. This option can be used only with searchable fields. It must be set together with searchAnalyzer and it cannot be set together with the analyzer option. " ,
"search_analyzer_name" : " name of the analyzer used at search time for the field. This option can be used only with searchable fields. It must be set together with indexAnalyzer and it cannot be set together with the analyzer option. This property cannot be set to the name of a language analyzer; use the analyzer property instead if you need a language analyzer. " ,
"char_filters" : " The character filters for the index " ,
"tokenizers" : " The tokenizers for the index " ,
"token_filters" : " The token filters for the index "
},
"query_language" : " The language of the query. Possible values: en-us, en-gb, fr-fr etc. "
},
"rerank" : {
"enabled" : " determines if search results should be re-ranked. Value values are TRUE or FALSE " ,
"type" : " determines the type of re-ranking. Value values are llm or cross_encoder " ,
"llm_rerank_threshold" : " determines the threshold when using llm re-ranking. Chunks with rank above this number are selected in range from 1 - 10. " ,
"cross_encoder_at_k" : " determines the threshold when using cross-encoding re-ranking. Chunks with given rank value are selected. " ,
"cross_encoder_model" : " determines the model used for cross-encoding re-ranking step. Valid value is cross-encoder/stsb-roberta-base "
},
"search" : {
"retrieve_num_of_documents" : " determines the number of chunks to retrieve from the search index " ,
"search_type" : " determines the search types used for experimentation. Valid value are search_for_match_semantic, search_for_match_Hybrid_multi, search_for_match_Hybrid_cross, search_for_match_text, search_for_match_pure_vector, search_for_match_pure_vector_multi, search_for_match_pure_vector_cross, search_for_manual_hybrid. e.g. ['search_for_manual_hybrid', 'search_for_match_Hybrid_multi','search_for_match_semantic'] " ,
"search_relevancy_threshold" : " the similarity threshold to determine if a doc is relevant. Valid ranges are from 0.0 to 1.0 "
},
"query_expansion" : {
"expand_to_multiple_questions" : " whether the system should expand a single question into multiple related questions. By enabling this feature, you can generate a set of alternative related questions that may improve the retrieval process and provide more accurate results " .,
"query_expansion" : " determines if query expansion feature is on. Value values are TRUE or FALSE " ,
"hyde" : " this feature allows you to experiment with various query expansion approaches which may improve the retrieval metrics. The possible values are 'disabled' (default), 'generated_hypothetical_answer', 'generated_hypothetical_document_to_answer' reference article - Precise Zero-Shot Dense Retrieval without Relevance Labels (HyDE - Hypothetical Document Embeddings) - https://arxiv.org/abs/2212.10496 " ,
"min_query_expansion_related_question_similarity_score" : " minimum similarity score in percentage between LLM generated related queries to the original query using cosine similarly score. default 90% "
},
"openai" : {
"azure_oai_chat_deployment_name" : " determines the Azure OpenAI deployment name " ,
"azure_oai_eval_deployment_name" : " determines the Azure OpenAI deployment name used for evaluation " ,
"temperature" : " determines the OpenAI temperature. Valid value ranges from 0 to 1. "
},
"eval" : {
"metric_types" : " determines the metrics used for evaluation (end-to-end or component-wise metrics using LLMs). Valid values for end-to-end metrics are lcsstr, lcsseq, cosine, jaro_winkler, hamming, jaccard, levenshtein, fuzzy_score, cosine_ochiai, bert_all_MiniLM_L6_v2, bert_base_nli_mean_tokens, bert_large_nli_mean_tokens, bert_large_nli_stsb_mean_tokens, bert_distilbert_base_nli_stsb_mean_tokens, bert_paraphrase_multilingual_MiniLM_L12_v2. Valid values for component-wise LLM-based metrics are llm_answer_relevance, llm_context_precision and llm_context_recall. e.g ['fuzzy_score','bert_all_MiniLM_L6_v2','cosine_ochiai','bert_distilbert_base_nli_stsb_mean_tokens', 'llm_answer_relevance'] " ,
}
}Catatan: Saat mengubah konfigurasi, ingatlah untuk mengubah:
config.sample.json (Contoh konfigurasi yang akan disalin oleh orang lain) embedding_model adalah array yang berisi konfigurasi untuk model embedding untuk digunakan. type model yang menanamkan harus azure untuk model Azure Openai dan sentence-transformer untuk model transformator kalimat pelukan.
{
"type" : " azure " ,
"model_name" : " the name of the Azure OpenAI model " ,
"dimension" : " the dimension of the embedding model. For example, 1536 which is the dimension of text-embedding-ada-002 "
} Jika Anda menggunakan model selain text-embedding-ada-002 , Anda harus menentukan dimensi yang sesuai untuk model di bidang dimension ; Misalnya:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 3072
}Dimensi untuk berbagai model embeddings Azure OpenAI dapat ditemukan dalam dokumentasi model layanan OpenAi Azure.
Saat menggunakan model embeddings yang lebih baru (V3), Anda juga dapat memanfaatkan dukungan mereka untuk memperpendek embeddings. Dalam hal ini, tentukan jumlah dimensi yang Anda butuhkan, dan tambahkan flag shorten_dimensions untuk menunjukkan bahwa Anda ingin mempersingkat embeddings. Misalnya:
{
"type" : " azure " ,
"model_name" : " text-embedding-3-large " ,
"dimension" : 256 ,
"shorten_dimensions" : true
}{
"type" : " sentence-transformer " ,
"model_name" : " the name of the sentence transformer model " ,
"dimension" : " the dimension of the model. This field is not required if model name is one of ['all-MiniLM-L6-v2', 'all-mpnet-base-v2', 'bert-large-nli-mean-tokens] "
}Memberikan contoh jawaban hipotetis untuk pertanyaan dalam kueri, sebuah bagian hipotetis yang memiliki jawaban atas kueri, atau menghasilkan beberapa pertanyaan terkait alternatif dapat meningkatkan pengambilan dan dengan demikian mendapatkan potongan dokumen yang lebih akurat untuk masuk ke dalam konteks LLM. Berdasarkan artikel referensi - pengambilan padat nol -shot yang tepat tanpa label relevansi (Hyde - Embeddings dokumen hipotetis).
Opsi konfigurasi berikut menyalakan pendekatan eksperimen ini:
{
"hyde" : " generated_hypothetical_answer "
}{
"hyde" : " generated_hypothetical_document_to_answer "
} Fitur ini akan menghasilkan pertanyaan terkait yang bagus, memfilter yang kurang dari min_query_expansion_related_question_similarity_score persen dari kueri asli (menggunakan skor kesamaan cosinus), dan mencari dokumen untuk masing -masing dari mereka bersama dengan kueri asli, hasil deduplikat dan mengembalikannya ke langkah -langkah Reranker dan Top K Top.
Nilai default untuk min_query_expansion_related_question_similarity_score diatur ke 90%, Anda dapat mengubahnya di config.json
{
"query_expansion" : true ,
"min_query_expansion_related_question_similarity_score" : 90
}Solusi ini terintegrasi dengan Azure Machine Learning dan menggunakan MLFLOW untuk mengelola eksperimen, pekerjaan, dan artefak. Anda dapat melihat laporan berikut sebagai bagian dari proses evaluasi:
all_metrics_current_run.html menunjukkan skor rata -rata di seluruh pertanyaan dan jenis pencarian untuk setiap metrik yang dipilih:
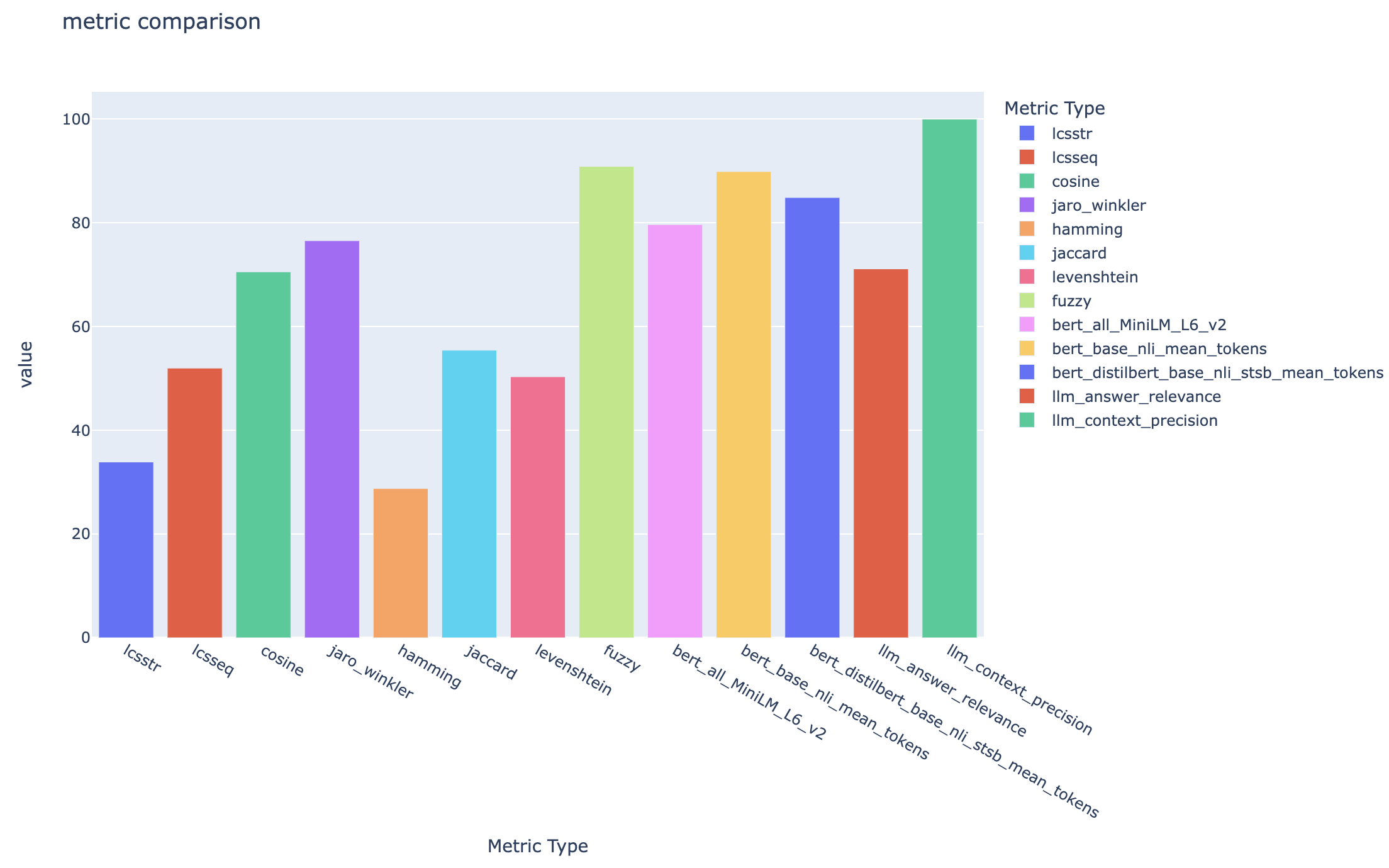
Perhitungan setiap metrik dan bidang yang digunakan untuk evaluasi dilacak untuk setiap pertanyaan dan jenis pencarian dalam file CSV output:
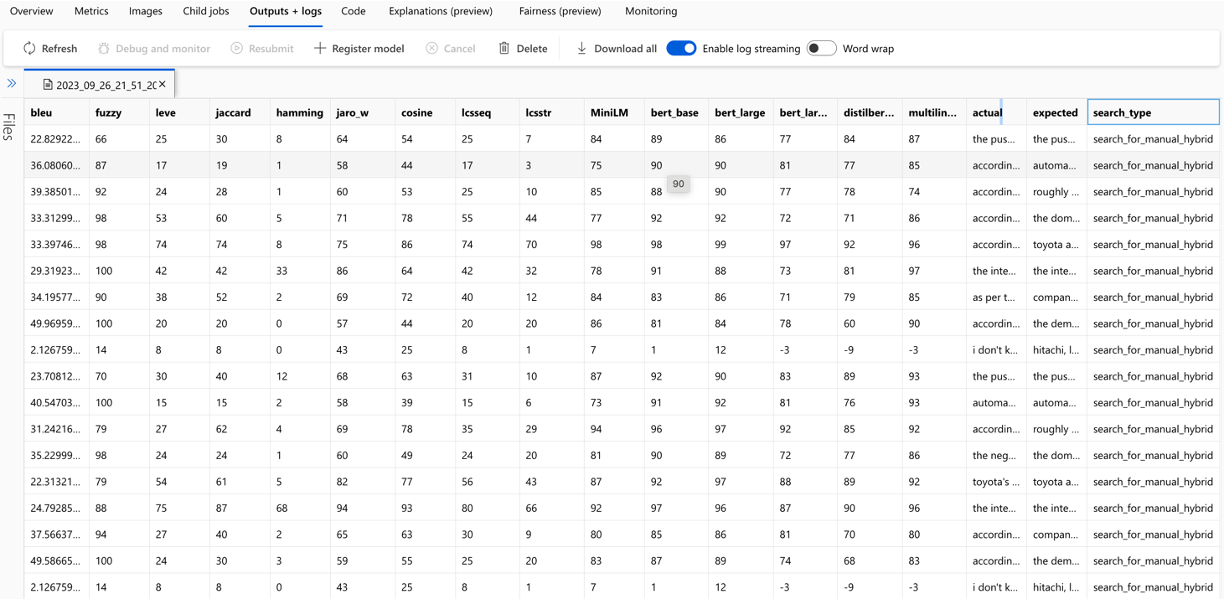
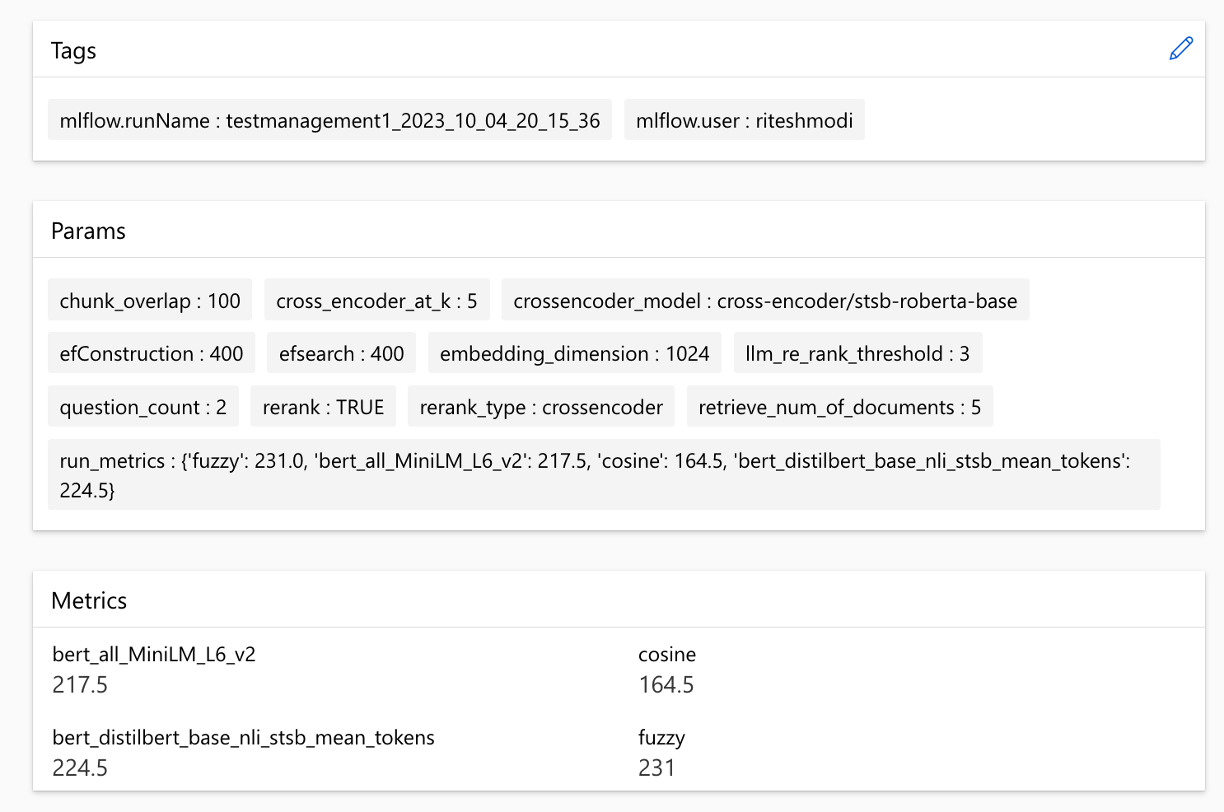
Metrik dapat dibandingkan lintas berjalan:
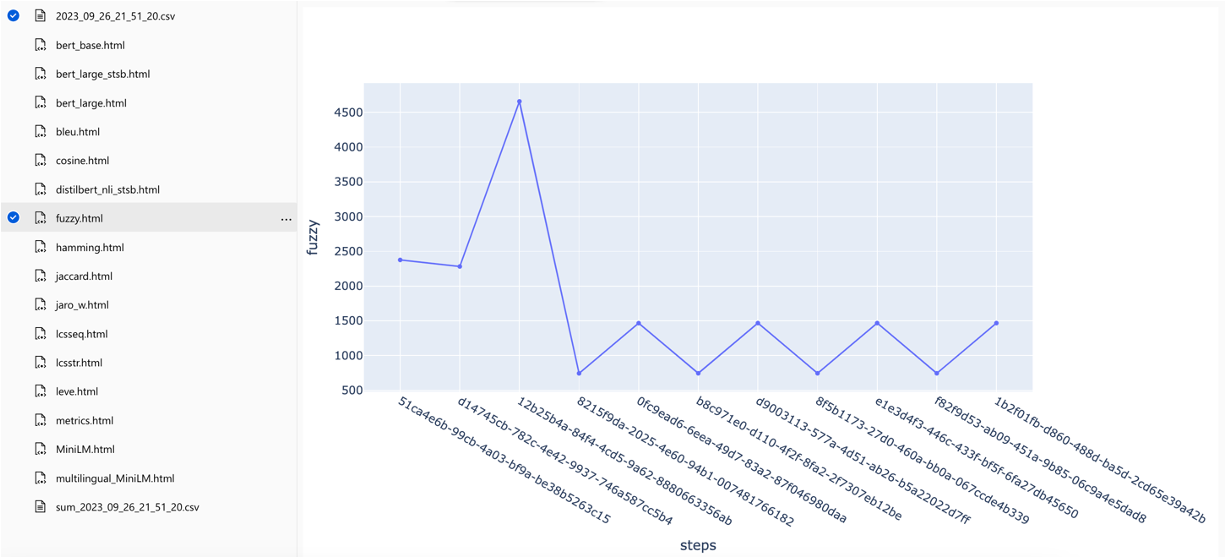
Metrik dapat dibandingkan di berbagai strategi pencarian:
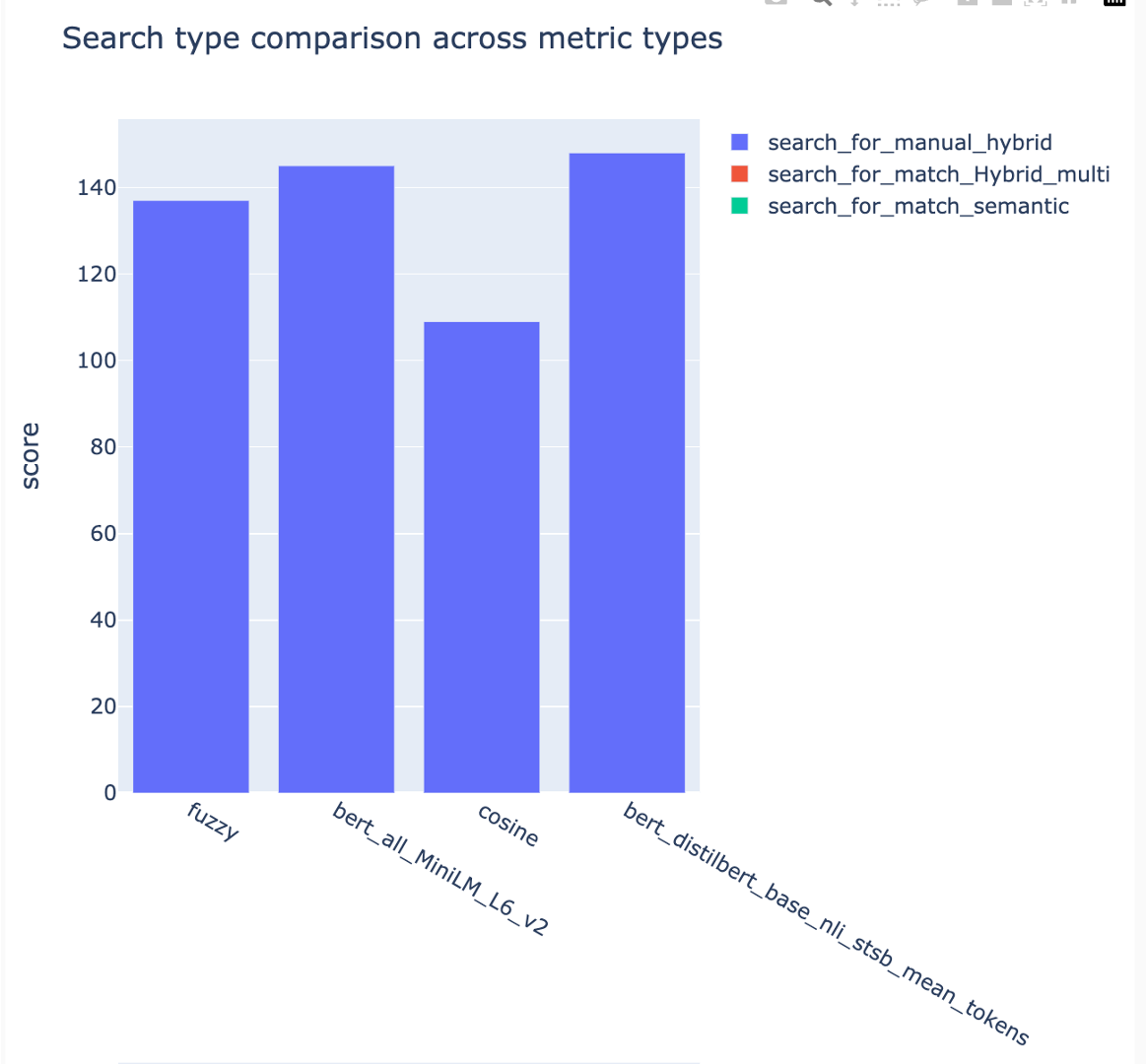
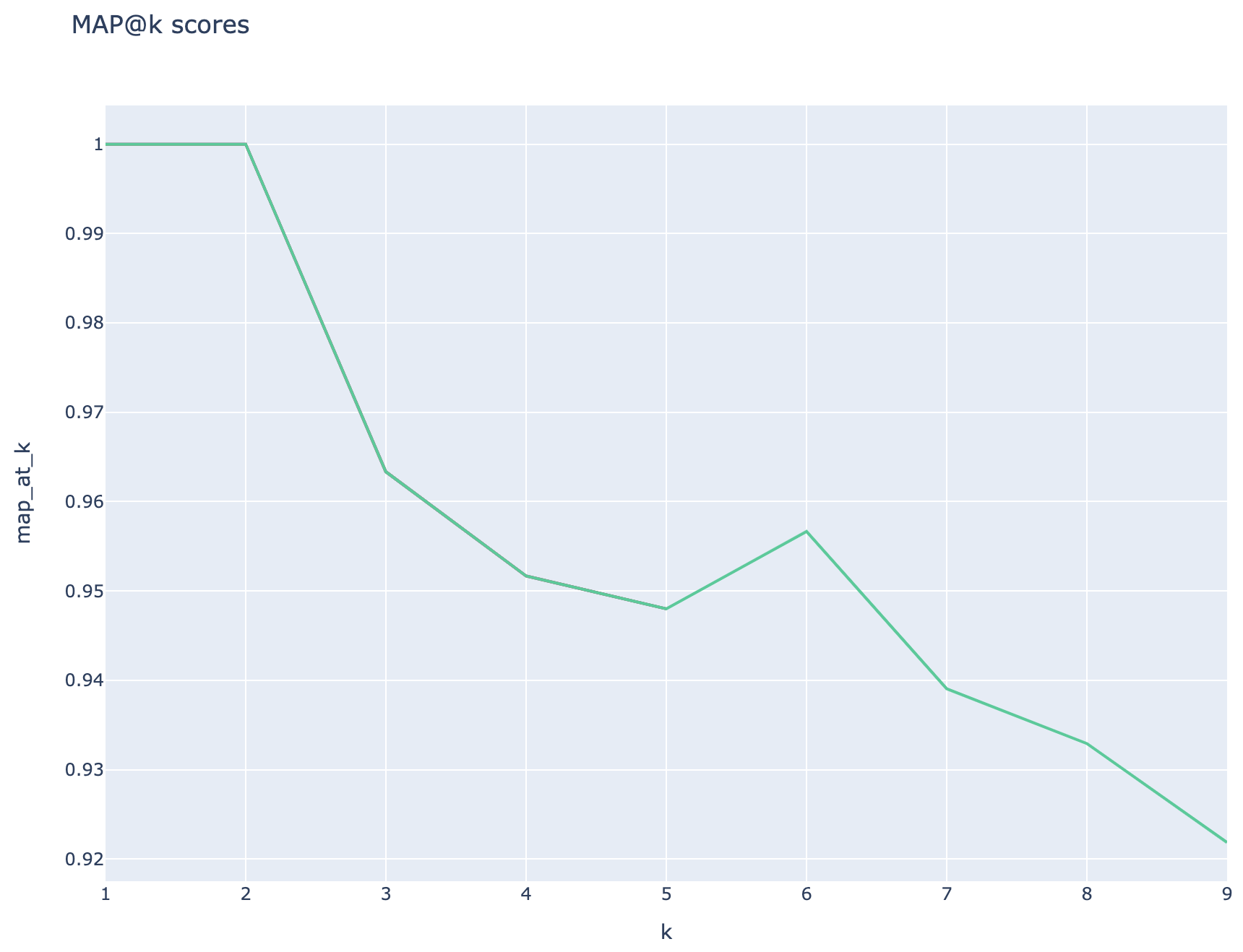
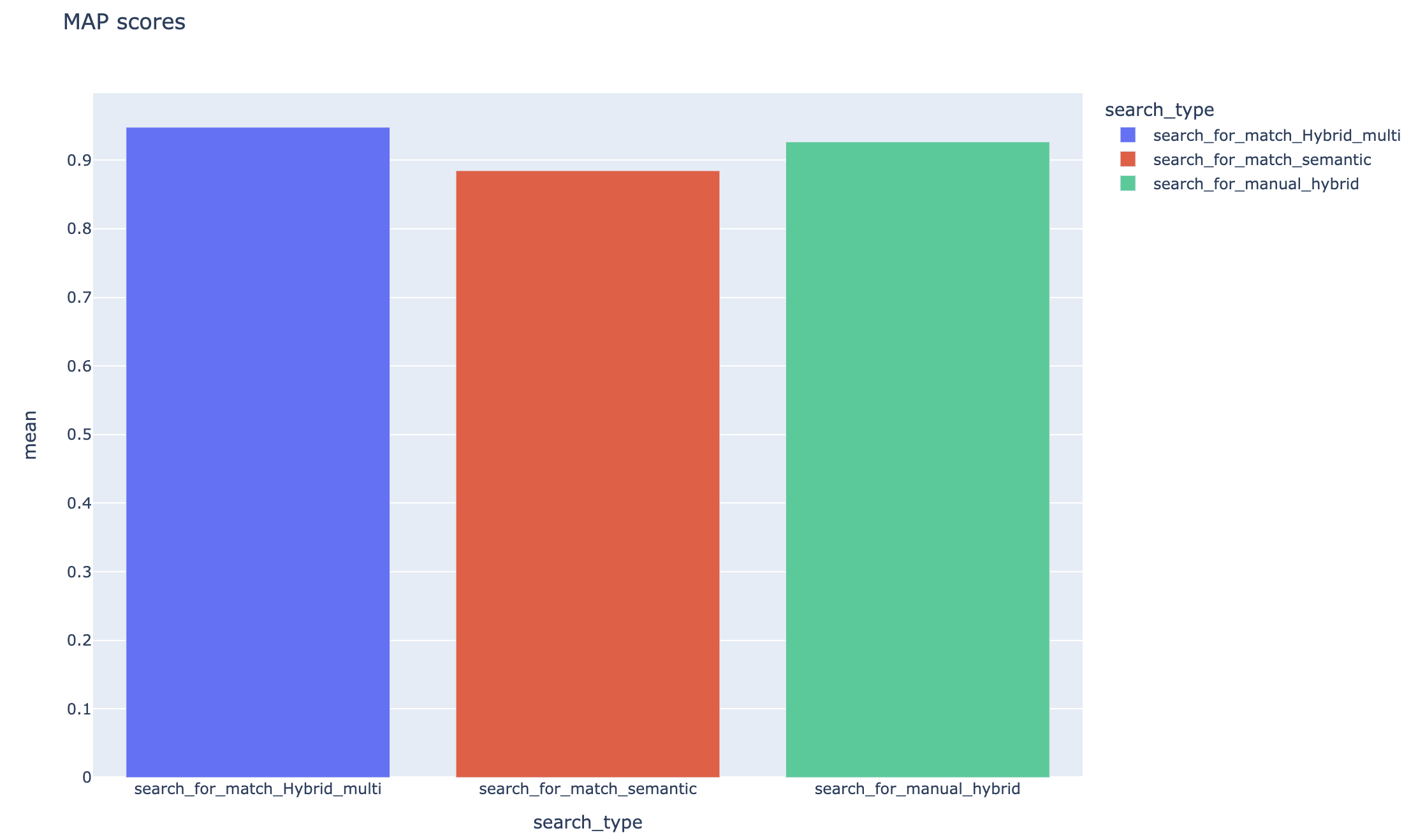
Rata -rata skor presisi rata -rata dilacak dan skor peta rata -rata dapat dibandingkan di seluruh jenis pencarian:
Bagian ini menguraikan gotcha atau jebakan umum yang mungkin ditemui oleh para insinyur/pengembang/data ilmuwan saat bekerja dengan akselerator eksperimen Rag.
Agar berhasil memanfaatkan solusi ini, Anda harus mengotentikasi diri Anda terlebih dahulu dengan masuk ke akun Azure Anda. Langkah penting ini memastikan Anda memiliki izin yang diperlukan untuk mengakses dan mengelola sumber daya Azure yang digunakan olehnya. Anda mungkin kesalahan yang terkait dengan menyimpan data QNA ke dalam aset data pembelajaran mesin Azure, melaksanakan langkah kueri dan evaluasi sebagai hasil dari otorisasi dan otentikasi yang tidak pantas ke Azure. Lihat titik 4 dalam dokumen ini untuk otentikasi dan otorisasi.
Mungkin ada situasi di mana solusi masih akan menghasilkan kesalahan meskipun otentikasi dan otorisasi yang valid. Dalam kasus seperti itu, mulailah sesi baru dengan instance terminal baru, login ke Azure menggunakan langkah -langkah yang disebutkan pada langkah 4 dan juga periksa apakah pengguna telah berkontribusi akses ke sumber daya Azure yang terkait dengan solusi.
Solusi ini menggunakan beberapa parameter konfigurasi di config.json yang secara langsung memengaruhi fungsionalitas dan kinerjanya. Harap perhatikan pengaturan ini:
RETRIEVE_NUM_OF_DOCUMEN: Konfigurasi ini mengontrol jumlah awal dokumen yang diambil untuk analisis. Nilai yang terlalu tinggi atau rendah dapat menyebabkan kesalahan "indeks di luar jangkauan" karena pemrosesan peringkat hasil pencarian AI.
Cross_encoder_at_k: Konfigurasi ini mempengaruhi proses peringkat. Nilai yang tinggi dapat mengakibatkan dokumen yang tidak relevan dimasukkan dalam hasil akhir.
LLM_RERANK_THRESHOLD: Konfigurasi ini menentukan dokumen mana yang diteruskan ke Model Bahasa (LLM) untuk pemrosesan lebih lanjut. Menetapkan nilai ini terlalu tinggi dapat menciptakan konteks yang terlalu besar untuk ditangani LLM, berpotensi menyebabkan kesalahan pemrosesan atau hasil yang terdegradasi. Ini juga dapat menghasilkan pengecualian dari titik akhir Azure OpenAI.
Sebelum menjalankan solusi ini, pastikan Anda telah mengatur dengan benar kedua nama penyebaran Azure OpenAI Anda di dalam file config.json dan menambahkan rahasia yang relevan ke variabel lingkungan (file .env). Informasi ini sangat penting bagi aplikasi untuk terhubung ke sumber daya dan fungsi OpenAi Azure yang sesuai seperti yang dirancang. Jika Anda tidak yakin tentang data konfigurasi, silakan merujuk ke .env.template dan file config.json. Solusinya telah diuji dengan model GPT 3.5 turbo dan membutuhkan tes lebih lanjut untuk model lain.
Selama langkah pembuatan QNA, Anda kadang -kadang dapat menghadapi kesalahan yang terkait dengan output JSON yang diterima dari Azure Openai. Kesalahan ini dapat mencegah keberhasilan beberapa pertanyaan dan jawaban yang sukses. Inilah yang perlu Anda ketahui:
Pemformatan yang salah: Output JSON dari Azure Openai mungkin tidak mematuhi format yang diharapkan, menyebabkan masalah dengan proses pembuatan QNA. Penyaringan Konten: Azure OpenAi memiliki filter konten di tempat. Jika teks input atau respons yang dihasilkan dianggap tidak pantas, itu dapat menyebabkan kesalahan. Keterbatasan API: Layanan Azure OpenAI memiliki token dan batasan tingkat yang mempengaruhi output.
Metrik evaluasi end-to-end: Tidak semua metrik yang membandingkan jawaban yang dihasilkan dan kebenaran darat dapat menangkap perbedaan dalam semantik. Misalnya, metrik seperti levenshtein atau jaro_winkler hanya mengukur jarak edit. Metrik cosine juga tidak mengizinkan perbandingan semantik: ia menggunakan implementasi berbasis token TextDistance berdasarkan vektor frekuensi istilah. Untuk menghitung kesamaan semantik antara jawaban yang dihasilkan dan respons yang diharapkan, pertimbangkan untuk menggunakan metrik berbasis embedding seperti skor BerT ( bert_ ).
Metrik evaluasi komponen-bijaksana: metrik evaluasi menggunakan llm-as-judges tidak deterministik. Metrik llm_ yang termasuk dalam akselerator menggunakan model yang ditunjukkan dalam bidang konfigurasi azure_oai_eval_deployment_name . Prompt yang digunakan untuk instruksi evaluasi dapat disesuaikan dan termasuk dalam file prompts.py ( llm_answer_relevance_instruction , llm_context_recall_instruction , llm_context_precision_instruction ).
Metrik berbasis pengambilan: Skor MAP dihitung dengan membandingkan setiap potongan yang diambil dengan pertanyaan dan potongan yang digunakan untuk menghasilkan pasangan QNA. Untuk menilai apakah potongan yang diambil relevan atau tidak, kesamaan antara potongan yang diambil dan gabungan dari pertanyaan pengguna akhir dan potongan yang digunakan dalam langkah QNA ( 02_qa_generation.py ) dihitung menggunakan spacyevaluator. Kesamaan spacy default dengan rata -rata vektor token, yang berarti bahwa perhitungan tidak peka terhadap urutan kata -kata. Secara default, ambang kesamaan diatur ke 80% ( spacy_evaluator.py ).
Kami menyambut kontribusi dan saran Anda. Untuk berkontribusi, Anda perlu menyetujui perjanjian lisensi kontributor (CLA) yang menegaskan Anda memiliki hak untuk, dan benar -benar melakukannya, beri kami hak untuk menggunakan kontribusi Anda. Untuk detailnya, kunjungi [https://cla.opensource.microsoft.com].
Saat Anda mengirimkan permintaan tarik, bot CLA akan secara otomatis memeriksa apakah Anda perlu memberikan CLA dan memberi Anda instruksi (misalnya, pemeriksaan status, komentar). Ikuti instruksi dari bot. Anda hanya perlu melakukan ini sekali untuk semua repo yang menggunakan CLA kami.
Sebelum Anda berkontribusi, pastikan untuk berlari
pip install -e .
pre-commit install
Proyek ini mengikuti kode perilaku open source Microsoft. Untuk informasi lebih lanjut, lihat FAQ Kode Perilaku atau hubungi [email protected] dengan pertanyaan atau komentar.
bug/11-short-descriptionfeature/22-short-descriptionexample_snake_case .git config --global user.name "First Last"Proyek ini mungkin berisi merek dagang atau logo untuk proyek, produk, atau layanan. Anda harus mengikuti pedoman merek dagang & merek Microsoft untuk menggunakan merek dagang atau logo Microsoft dengan benar. Jangan gunakan merek dagang atau logo Microsoft dalam versi yang dimodifikasi dari proyek ini dengan cara yang menyebabkan kebingungan atau menyiratkan sponsor Microsoft. Ikuti kebijakan merek dagang atau logo pihak ketiga mana pun yang dikandung oleh proyek ini.


