super json mode
1.0.0
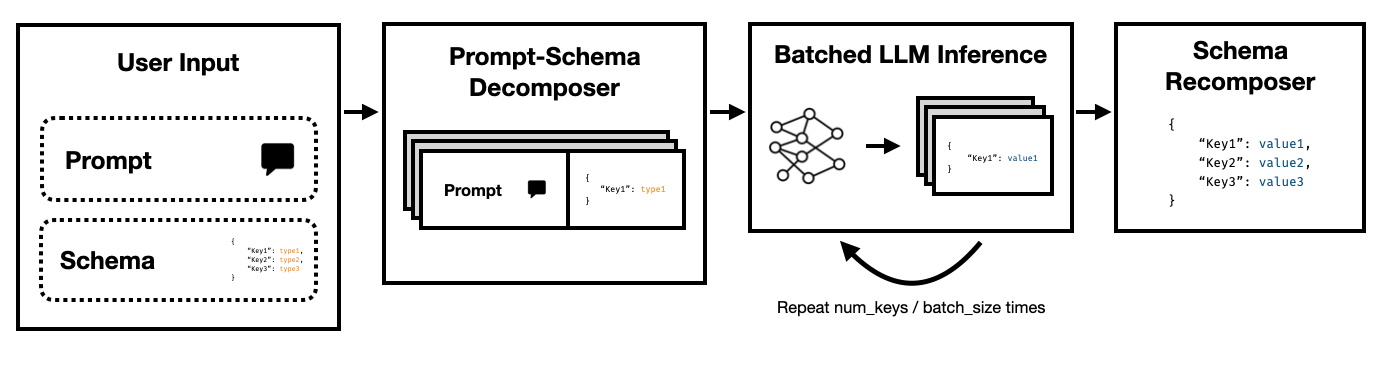
Super Json Mode adalah kerangka kerja Python yang memungkinkan penciptaan efisien output terstruktur dari LLM dengan memecah skema target menjadi komponen atom dan kemudian melakukan generasi secara paralel.
Ini mendukung kedua LLMS yang canggih melalui API Penyelesaian Legacy Openai dan Open Source LLMS seperti Via Hugging Face Transformers dan VLLM . Lebih banyak LLM akan segera didukung!
Dibandingkan dengan pipa generasi JSON yang naif yang mengandalkan transformer dan transformator HF, kami menemukan mode Super JSON dapat menghasilkan output sebanyak 10x lebih cepat . Ini juga lebih deterministik dan lebih kecil kemungkinannya untuk mengalami masalah parsing bila dibandingkan dengan generasi yang naif.
Instalasi Sederhana: pip install super-json-mode
Format output terstruktur, seperti JSON atau YAML, memiliki struktur paralel atau hierarkis yang melekat.
Pertimbangkan bagian tidak terstruktur berikut (dihasilkan oleh GPT-4):
Selamat datang di 123 Azure Lane, kediaman San Francisco yang menakjubkan menawarkan desain kontemporer yang fantastis, sekarang di pasaran seharga $ 2.500.000. Tersebar di atas 3.000 kaki persegi mewah, properti ini menggabungkan kecanggihan dan kenyamanan untuk menciptakan pengalaman hidup yang benar -benar unik.
Rumah yang indah untuk keluarga atau profesional, tempat tinggal eksklusif kami dilengkapi dengan lima kamar tidur yang luas, masing -masing kehangatan yang mengalir dan keanggunan modern. Kamar tidur direncanakan dengan hati -hati untuk memungkinkan ruang penyimpanan yang luas dan murah hati. Dengan tiga kamar mandi lengkap yang dirancang dengan elegan, tempat tinggal menjamin kenyamanan dan privasi bagi penghuninya.
Pintu masuk yang megah membawa Anda ke ruang tamu yang luas, memberikan suasana yang sangat baik untuk pertemuan atau malam yang tenang di dekat api. Dapur koki termasuk peralatan canggih, kabinet khusus, dan meja granit yang indah menjadikannya mimpi bagi siapa saja yang suka memasak.
Jika kami ingin mengekstrak address , square footage , number of bedrooms , number of bathrooms , dan price menggunakan LLM, kami dapat meminta model untuk mengisi skema sesuai dengan deskripsi.
Skema potensial (seperti yang dihasilkan dari objek Pydantic) bisa terlihat seperti ini:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
Dan output yang valid bisa terlihat seperti ini:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
Pendekatan yang jelas adalah untuk menyatukan skema di prompt dan meminta model untuk mengisinya. Ini adalah bagaimana sebagian besar tim saat ini mengekstrak output terstruktur dari teks tidak terstruktur menggunakan LLMS.
Namun, ini tidak efisien karena tiga alasan.
Perhatikan bagaimana masing -masing kunci ini tidak tergantung satu sama lain. Super Json Mode mengambil keuntungan dari paralelisme cepat dengan memperlakukan setiap pasangan nilai kunci dalam skema sebagai penyelidikan terpisah. Misalnya, kita dapat mengekstrak num_baths tanpa sudah menghasilkan address !
Meminta model untuk menghasilkan JSON dari awal tidak perlu mengkonsumsi token (dan dengan demikian waktu) pada sintaks yang dapat diprediksi, seperti kawat gigi dan nama kunci, yang sudah diharapkan dalam output. Ini adalah sebelumnya yang kuat pada generasi yang harus dapat kita gunakan untuk meningkatkan latensi.
LLMS secara paralel memalukan dan menjalankan pertanyaan dalam batch jauh lebih cepat daripada dalam urutan serial. Dengan demikian, kita dapat membagi skema atas beberapa pertanyaan. LLM kemudian akan mengisi skema untuk setiap kunci independen secara paralel dan memancarkan token yang jauh lebih sedikit dalam satu umpan, memungkinkan waktu inferensi yang jauh lebih cepat.
Jalankan perintah berikut:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Kami telah mencoba membuat mode super json super mudah digunakan. Lihat folder examples untuk lebih banyak contoh dan penggunaan vLLM .
Menggunakan openai dan gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Menggunakan Mistral 7B dengan Transformers Huggingface:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Ada banyak fitur yang dapat membuat mode Super JSON lebih baik. Inilah beberapa ide.
Analisis Output Kualitatif : Kami menjalankan tolok ukur kinerja, tetapi kami harus menghasilkan pendekatan yang lebih ketat untuk menilai output kualitatif mode Super JSON.
Pengambilan sampel terstruktur : Idealnya, kita harus menutupi log LLM untuk menegakkan batasan tipe, mirip dengan jsonFormer. Ada beberapa paket di luar sana yang sudah melakukan ini, dan baik yang harus mengintegrasikan pipa generasi JSON yang diparalelkan atau kami harus membangunnya ke dalam mode Super JSON.
Dukungan Grafik Ketergantungan : Mode Super JSON memiliki kasus kegagalan yang sangat jelas: ketika kunci memiliki ketergantungan pada kunci lain. Pertimbangkan gumpalan JSON dengan dua kunci, thought dan response . Output yang diinginkan semacam ini adalah umum untuk rantai-dipikirkan dengan model bahasa besar, dan sangat jelas bahwa response tergantung pada thought tersebut. Kita harus dapat meneruskan grafik dependensi dan petunjuk batch dengan cara agar output induk diselesaikan dan diteruskan ke item skema anak.
Dukungan Model Lokal : Mode Super JSON bekerja paling baik dalam situasi lokal di mana ukuran batch umumnya 1. Anda dapat mengeksploitasi batching untuk mengurangi latensi, mirip dengan decoding spekulatif. Llama.cpp adalah kerangka kerja utama untuk model lokal + inferensi CPU. Saya ingin menerapkan ini menggunakan ollama jika memungkinkan.
Dukungan TRT-LLM : VLLM sangat bagus dan mudah digunakan, tetapi idealnya kami berintegrasi dengan kerangka kerja yang jauh lebih banyak seperti TRT-LLM.
Kami menghargainya jika Anda mau mengutip repo ini jika Anda menemukan perpustakaan berguna untuk pekerjaan Anda:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Proyek ini dibangun untuk CS 229: Sistem untuk Pembelajaran Mesin. Terima kasih banyak kepada tim pengajar dan TAS atas bimbingan mereka di seluruh proyek ini.


