Di kalangan AI, pemenang Turing Award Yann Lecun adalah tipikal orang asing.
Meskipun banyak pakar teknis sangat yakin bahwa sepanjang jalur teknis saat ini, realisasi AGI hanya tinggal menunggu waktu, Yann Lecun telah berulang kali mengajukan keberatan.
Dalam perdebatan sengit dengan rekan-rekannya, dia mengatakan lebih dari sekali bahwa jalur teknologi arus utama saat ini tidak dapat membawa kita ke AGI, dan bahkan tingkat AI saat ini tidak sebaik kucing.
Pemenang Turing Award, kepala ilmuwan AI Meta, profesor Universitas New York, dll. Gelar-gelar menakjubkan dan pengalaman praktis garis depan yang berat ini membuat kita tidak mungkin mengabaikan wawasan pakar AI ini.

Jadi, apa pendapat Yann LeCun tentang masa depan AI? Dalam pidato publiknya baru-baru ini, ia sekali lagi menguraikan sudut pandangnya: AI tidak akan pernah bisa mencapai kecerdasan mendekati tingkat manusia hanya dengan mengandalkan pelatihan teks.
Beberapa pandangan adalah sebagai berikut:
1. Di masa depan, orang-orang pada umumnya akan memakai kacamata pintar atau perangkat pintar jenis lainnya. Perangkat ini akan memiliki sistem asisten bawaan untuk membentuk tim virtual cerdas pribadi guna meningkatkan kreativitas dan efisiensi pribadi.
2. Tujuan sistem cerdas bukan untuk menggantikan manusia, tetapi untuk meningkatkan kecerdasan manusia sehingga manusia dapat bekerja lebih efisien.
3. Bahkan seekor kucing peliharaan pun memiliki model di otaknya yang lebih kompleks daripada yang bisa dibangun oleh sistem AI mana pun.
4. FAIR pada dasarnya tidak lagi berfokus pada model bahasa, namun bergerak menuju tujuan jangka panjang sistem AI generasi berikutnya.
5. Sistem AI tidak dapat mencapai kecerdasan yang mendekati tingkat kecerdasan manusia hanya dengan melatih data teks saja.
6. Yann Lecun menyarankan untuk meninggalkan model generatif, model probabilistik, pembelajaran kontrastif dan pembelajaran penguatan, dan sebagai gantinya mengadopsi arsitektur JEPA dan model berbasis energi, karena percaya bahwa metode ini lebih mungkin mendorong pengembangan AI.
7. Meskipun mesin pada akhirnya akan melampaui kecerdasan manusia, mereka akan dikendalikan karena mereka mempunyai tujuan.
Menariknya, ada satu episode sebelum pidato dimulai.
Saat pembawa acara memperkenalkan LeCun, dia memanggilnya sebagai kepala ilmuwan AI di Facebook AI Research Institute (FAIR) .
Terkait hal ini, LeCun mengklarifikasi sebelum pidatonya bahwa huruf "F" di FAIR tidak lagi mewakili Facebook, melainkan berarti " Fundamental ".
Teks asli pidato di bawah ini disusun oleh APPSO dan telah diedit. Terakhir, link video asli terlampir: https://www.youtube.com/watch?v=4DsCtgtQlZU
AI tidak memahami dunia sebaik kucing Anda
Oke, jadi saya akan berbicara tentang AI tingkat manusia dan bagaimana kita akan mencapainya dan mengapa kita tidak akan mencapainya.
Pertama, kita sangat membutuhkan AI pada tingkat manusia.
Karena di masa depan, salah satunya adalah sebagian besar dari kita akan memakai kacamata pintar atau perangkat jenis lainnya. Kita akan berbicara dengan perangkat ini, dan sistem ini akan menampung asisten, mungkin lebih dari satu, mungkin seluruh rangkaian asisten.
Hal ini pada dasarnya akan membuat kita masing-masing memiliki tim virtual cerdas yang bekerja untuk kita.
Oleh karena itu, setiap orang akan menjadi "bos", tetapi "karyawan" tersebut bukanlah manusia sungguhan. Kita perlu membangun sistem seperti ini, yang pada dasarnya bertujuan untuk meningkatkan kecerdasan manusia dan menjadikan manusia lebih kreatif dan efisien.

Namun untuk itu, kita membutuhkan mesin yang dapat memahami dunia, mengingat berbagai hal, memiliki intuisi dan akal sehat, serta bernalar dan merencanakan pada tingkat yang sama dengan manusia.
Meskipun Anda mungkin pernah mendengar beberapa pendukung mengatakan bahwa sistem AI saat ini tidak memiliki kemampuan ini. Jadi kita perlu meluangkan waktu untuk mempelajari cara membuat model dunia, untuk memiliki model mental tentang cara kerja dunia.
Hampir setiap hewan mempunyai model seperti itu. Kucing Anda harus memiliki model yang lebih kompleks daripada yang dapat dibuat atau dirancang oleh sistem AI mana pun.

Kita memerlukan sistem yang memiliki memori persisten yang tidak dimiliki model bahasa (LLM) saat ini, sistem yang dapat merencanakan rangkaian tindakan kompleks yang tidak dapat dilakukan oleh sistem saat ini, dan sistem yang dapat dikontrol dan aman.
Oleh karena itu, saya akan mengusulkan arsitektur yang disebut AI yang digerakkan oleh tujuan. Saya menulis makalah visi tentang ini sekitar dua tahun lalu dan menerbitkannya. Banyak orang di FAIR yang bekerja keras untuk mewujudkan rencana ini.
FAIR telah mengerjakan lebih banyak proyek aplikasi di masa lalu, namun Meta menciptakan divisi produk yang disebut Generative AI (Gen AI) satu setengah tahun yang lalu untuk fokus pada produk AI.
Mereka melakukan penelitian dan pengembangan terapan, sehingga kini FAIR telah diarahkan ke tujuan jangka panjang sistem AI generasi berikutnya. Kami pada dasarnya tidak lagi fokus pada model bahasa.
Keberhasilan AI, termasuk model bahasa besar (LLM) , dan khususnya keberhasilan banyak sistem lainnya selama 5 atau 6 tahun terakhir, bergantung pada serangkaian teknik, termasuk, tentu saja, pembelajaran yang diawasi sendiri.

Inti dari pembelajaran mandiri adalah melatih sistem bukan untuk tugas tertentu, namun mencoba merepresentasikan data masukan dengan cara yang baik. Salah satu cara untuk mencapai hal ini adalah melalui pemulihan kerusakan dan pembangunan kembali.
Jadi Anda dapat mengambil sepotong teks dan merusaknya dengan menghapus beberapa kata atau mengubah kata lain. Proses ini dapat digunakan untuk teks, urutan DNA, protein atau apa pun, dan bahkan gambar sampai batas tertentu. Anda kemudian melatih jaringan saraf besar untuk merekonstruksi masukan yang lengkap, versi yang tidak rusak.
Ini adalah model generatif karena berupaya merekonstruksi sinyal asli.
Jadi, kotak merah itu seperti fungsi biaya ya? Ini menghitung jarak antara masukan Y dan keluaran y yang direkonstruksi, dan ini adalah parameter yang harus diminimalkan selama proses pembelajaran. Dalam proses ini, sistem mempelajari representasi internal dari masukan, yang dapat digunakan untuk berbagai tugas selanjutnya.
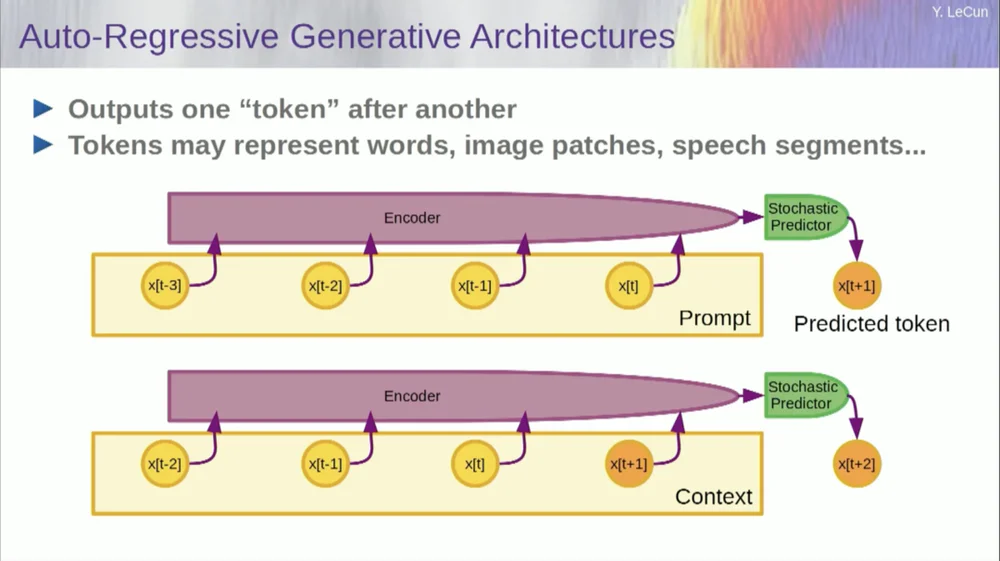
Tentu saja, ini dapat digunakan untuk memprediksi kata-kata dalam teks, yang merupakan fungsi dari prediksi autoregresif .
Model bahasa adalah kasus khusus dalam hal ini, di mana arsitektur dirancang sedemikian rupa sehingga ketika memprediksi suatu item, token, atau kata, ia hanya dapat melihat token lain di sebelah kirinya.
Ia tidak bisa melihat ke masa depan. Jika Anda melatih sistem dengan benar, menampilkan teks, dan memintanya memprediksi kata berikutnya atau token berikutnya dalam teks, maka Anda dapat menggunakan sistem untuk memprediksi kata berikutnya. Kemudian Anda menambahkan kata berikutnya ke masukan, memprediksi kata kedua, dan menambahkannya ke masukan, memprediksi kata ketiga.
Ini adalah prediksi autoregresif .
Inilah yang dilakukan LLM, ini bukan konsep baru, ini sudah ada sejak masa Shannon , kembali ke tahun 50an, yang sudah lama sekali, namun perubahannya adalah kita sekarang memiliki arsitektur jaringan saraf yang sangat besar, Anda dapat melatih pada sejumlah besar data dan fitur akan muncul darinya.
Namun prediksi autoregresif semacam ini memiliki beberapa keterbatasan besar, dan tidak ada alasan nyata dalam pengertian biasa di sini.
Namun batasan lainnya adalah bahwa ini hanya berfungsi untuk data dalam bentuk objek diskrit, simbol, token, kata-kata, dll., yang pada dasarnya adalah hal-hal yang dapat didiskritisasi.
Kita masih kehilangan sesuatu yang penting dalam mencapai kecerdasan tingkat manusia.
Saya tidak berbicara tentang kecerdasan tingkat manusia di sini, tetapi bahkan kucing atau anjing Anda pun dapat mencapai beberapa prestasi luar biasa yang berada di luar jangkauan sistem AI saat ini.

Anak berusia 10 tahun mana pun bisa belajar membersihkan meja dan mengisi mesin cuci piring sekaligus, bukan? Tidak perlu latihan atau semacamnya kan?
Dibutuhkan sekitar 20 jam latihan bagi anak berusia 17 tahun untuk belajar mengemudi.
Kami masih belum memiliki mobil self-driving Level 5, dan tentunya kami belum memiliki robot rumahan yang mampu membersihkan meja dan mengisi mesin pencuci piring.
AI tidak akan pernah mencapai kecerdasan yang mendekati tingkat manusia hanya dengan berlatih menggunakan teks
Jadi kita benar-benar kehilangan sesuatu yang penting yang jika tidak kita dapat melakukan hal-hal ini dengan sistem AI.
Kita terus-menerus menjumpai sesuatu yang disebut Paradoks Moravec , yaitu hal-hal yang tampak sepele bagi kita dan bahkan tidak dianggap cerdas sebenarnya sangat sulit dilakukan dengan mesin, dan hal-hal seperti manipulasi Pemikiran abstrak kompleks tingkat tinggi seperti bahasa tampaknya sulit dilakukan. sangat sederhana untuk mesin, dan hal yang sama berlaku untuk hal-hal seperti bermain catur dan Go.
Mungkin salah satu alasannya adalah ini.
Model bahasa besar (LLM) biasanya dilatih pada 20 triliun token.
Sebuah token pada dasarnya terdiri dari tiga perempat kata, rata-rata. Oleh karena itu, totalnya ada 1,5×10^13 kata. Setiap token berukuran sekitar 3B, biasanya ini membutuhkan 6×1013 byte.
Diperlukan waktu sekitar beberapa ratus ribu tahun bagi kita untuk membaca ini, bukan? Ini pada dasarnya adalah gabungan semua teks publik di internet.

Tapi coba pikirkan seorang anak berusia empat tahun yang telah terjaga selama 16.000 jam. Kita memiliki 2 juta serabut saraf optik yang memasuki otak kita. Setiap serabut saraf mengirimkan data dengan kecepatan sekitar 1B per detik, mungkin setengah byte per detik. Beberapa perkiraan mengatakan angkanya bisa mencapai 3 miliar per detik.
Tidak masalah, itu adalah urutan besarnya.
Jumlah data ini kira-kira 10 hingga 14 byte pangkat, yang hampir sama besarnya dengan LLM. Jadi, dalam empat tahun, anak berusia empat tahun telah melihat data visual sebanyak model bahasa terbesar yang dilatih pada teks yang tersedia untuk umum di seluruh internet.
Dengan menggunakan data sebagai titik awal, hal ini memberi tahu kita beberapa hal.
Pertama, hal ini memberi tahu kita bahwa kita tidak akan pernah mencapai tingkat kecerdasan manusia hanya dengan berlatih menggunakan teks. Ini tidak akan terjadi.
Kedua, informasi visual sangat berlebihan. Setiap serabut saraf optik mengirimkan 1B informasi per detik, yang sudah dikompresi 100 banding 1 dibandingkan dengan fotoreseptor di retina Anda.
Ada sekitar 60 juta hingga 100 juta fotoreseptor di retina kita. Fotoreseptor ini dikompresi menjadi 1 juta serabut saraf oleh neuron di depan retina. Jadi sudah ada kompresi 100 banding 1. Kemudian pada saat mencapai otak, informasi tersebut diperluas sekitar 50 kali lipat.
Jadi yang saya ukur adalah informasi terkompresi, namun masih sangat mubazir. Dan redundansi sebenarnya adalah hal yang dibutuhkan oleh pembelajaran dengan pengawasan mandiri. Pembelajaran dengan pengawasan mandiri hanya akan mempelajari hal-hal berguna dari data yang berlebihan. Jika data sangat terkompresi, yang berarti data menjadi gangguan acak, maka Anda tidak dapat mempelajari apa pun.
Anda memerlukan redundansi untuk mempelajari apa pun. Anda perlu mempelajari struktur dasar data. Oleh karena itu, kita perlu melatih sistem untuk mempelajari akal sehat dan fisika dengan menonton video atau hidup di dunia nyata.
Urutan kata-kata saya mungkin sedikit membingungkan. Saya terutama ingin memberi tahu Anda apa itu arsitektur kecerdasan buatan yang berorientasi pada tujuan. Berbeda sekali dengan LLM atau neuron feedforward yang proses inferensinya tidak hanya melalui serangkaian lapisan jaringan syaraf, namun sebenarnya menjalankan algoritma optimasi.
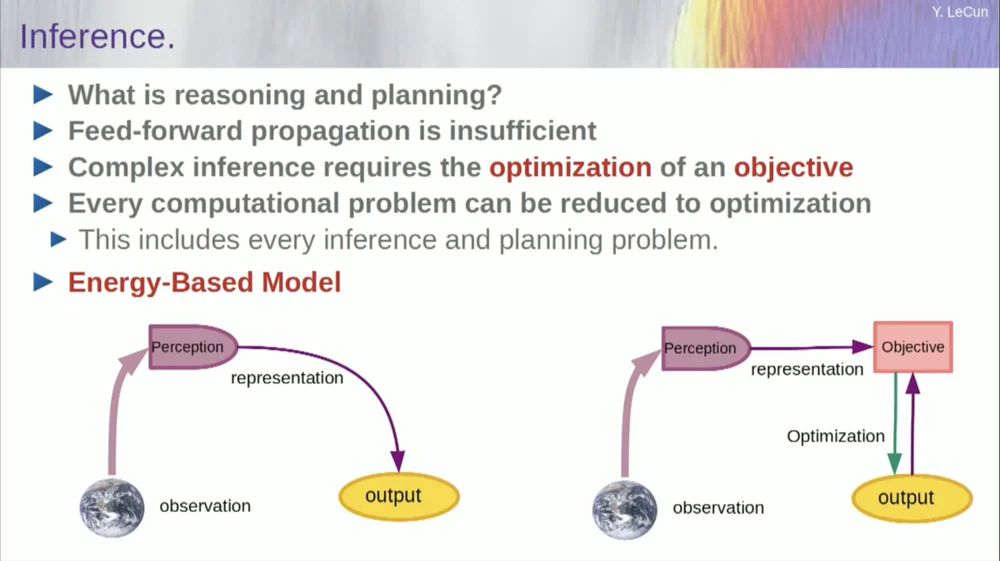
Secara konseptual, tampilannya seperti ini.
Proses feedforward adalah proses dimana observasi dijalankan melalui sistem persepsi. Misalnya, jika Anda memiliki serangkaian lapisan jaringan saraf dan menghasilkan keluaran, maka untuk setiap masukan, Anda hanya dapat memiliki satu keluaran, namun dalam banyak kasus, untuk suatu persepsi, mungkin terdapat beberapa kemungkinan interpretasi keluaran. Anda memerlukan proses pemetaan yang tidak hanya menghitung fungsionalitas, namun menyediakan banyak keluaran untuk satu masukan. Satu-satunya cara untuk mencapai hal ini adalah melalui fungsi implisit.
Pada dasarnya, kotak merah di sisi kanan kerangka tujuan ini mewakili fungsi yang pada dasarnya mengukur kompatibilitas antara suatu masukan dan keluaran yang diusulkan, dan kemudian menghitung keluaran dengan mencari nilai keluaran yang paling sesuai dengan masukan tersebut. Anda dapat membayangkan bahwa tujuan ini adalah semacam fungsi energi, dan Anda meminimalkan energi ini dengan keluaran sebagai variabel.
Anda mungkin memiliki banyak solusi, dan Anda mungkin memiliki cara untuk menangani banyak solusi tersebut. Hal ini berlaku pada sistem persepsi manusia. Jika Anda memiliki banyak interpretasi terhadap persepsi tertentu, otak Anda secara otomatis akan beralih di antara interpretasi tersebut. Jadi ada beberapa bukti bahwa hal semacam ini memang terjadi.
Tapi izinkan saya kembali ke arsitektur. Jadi manfaatkan prinsip penalaran ini dengan optimasi. Berikut asumsi-asumsinya, jika Anda mau, tentang cara kerja pikiran manusia. Anda melakukan pengamatan di dunia. Sistem persepsi memberi Anda gambaran tentang keadaan dunia saat ini. Namun tentu saja, ini hanya memberi Anda gambaran tentang keadaan dunia yang dapat Anda rasakan saat ini.
Anda mungkin ingat beberapa gagasan tentang keadaan dunia. Hal ini dapat dikombinasikan dengan isi memori dan dimasukkan ke dalam model dunia.
Apa itu model? Model dunia adalah model mental tentang bagaimana Anda berperilaku di dunia, sehingga Anda dapat membayangkan rangkaian tindakan yang mungkin Anda ambil, dan model dunia Anda akan memungkinkan Anda memprediksi dampak rangkaian tindakan tersebut terhadap dunia.
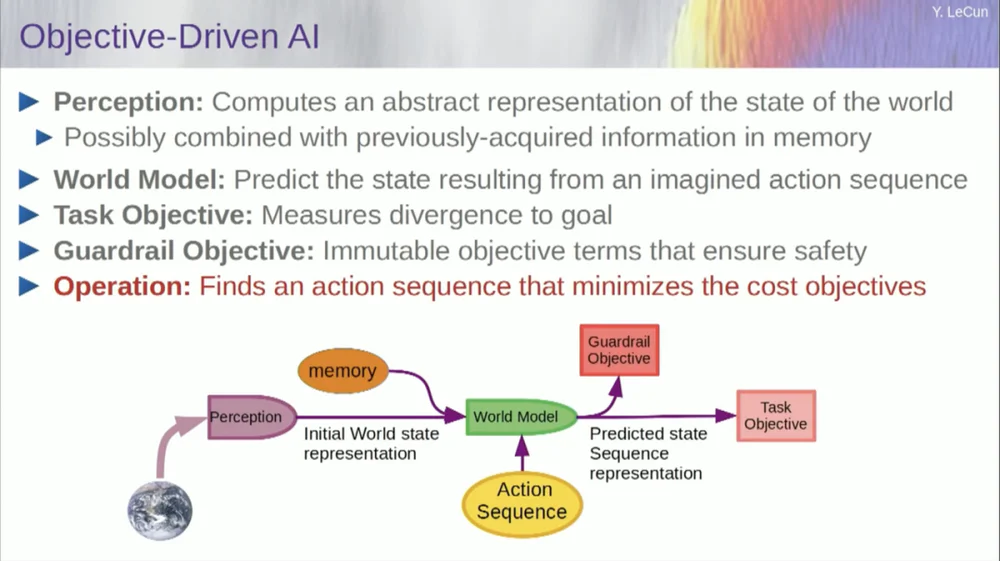
Jadi kotak hijau mewakili model dunia yang Anda gunakan untuk memasukkan serangkaian tindakan hipotetis yang memprediksi keadaan akhir dunia nanti, atau keseluruhan lintasan yang Anda prediksi akan terjadi di dunia.
Anda menggabungkannya dengan serangkaian fungsi tujuan. Salah satu tujuannya adalah untuk mengukur seberapa baik tujuan tersebut tercapai, apakah tugas telah selesai, dan mungkin serangkaian tujuan lain yang berfungsi sebagai margin keselamatan, pada dasarnya mengukur sejauh mana lintasan yang diikuti atau tindakan yang diambil tidak menimbulkan bahaya bagi robot. atau orang-orang di sekitar mesin, dll. tunggu.
Jadi sekarang proses penalaran (saya belum bicara tentang belajar) hanyalah penalaran dan terdiri dari menemukan rangkaian tindakan yang meminimalkan tujuan tersebut, menemukan rangkaian tindakan yang meminimalkan tujuan tersebut. Ini adalah proses penalaran.
Jadi ini bukan sekedar proses feedforward. Anda dapat melakukan ini dengan mencari opsi terpisah, tapi itu tidak efisien. Pendekatan yang lebih baik adalah memastikan bahwa semua kotak ini dapat dibedakan, Anda dapat melakukan propagasi mundur gradien melalui kotak tersebut dan kemudian memperbarui urutan tindakan melalui penurunan gradien.

Nah, ide ini sebenarnya bukanlah hal baru dan sudah ada selama lebih dari 60 tahun, bahkan mungkin lebih lama lagi. Pertama, izinkan saya berbicara tentang keuntungan menggunakan model dunia untuk alasan seperti ini. Keuntungannya adalah Anda dapat menyelesaikan tugas baru tanpa perlu belajar apa pun.
Kami melakukan ini dari waktu ke waktu. Ketika kita dihadapkan pada situasi baru, kita memikirkannya, membayangkan konsekuensi dari tindakan kita, dan kemudian mengambil serangkaian tindakan yang akan mencapai tujuan kita (apa pun itu) . Kita tidak perlu belajar untuk menyelesaikan tugas itu , kita bisa merencanakan. Jadi itu pada dasarnya adalah perencanaan.
Anda dapat menggabungkan sebagian besar bentuk penalaran hingga pengoptimalan. Oleh karena itu, proses inferensi melalui pengoptimalan secara inheren lebih kuat daripada sekadar menjalankan beberapa lapisan jaringan saraf. Seperti yang saya katakan, gagasan penalaran melalui optimasi telah ada selama lebih dari 60 tahun.
Dalam bidang teori kendali optimal, hal ini disebut kendali prediktif model.
Anda memiliki model sistem yang ingin Anda kendalikan, seperti roket, pesawat terbang, atau robot. Anda dapat membayangkan menggunakan model dunia Anda untuk menghitung efek dari serangkaian perintah kontrol.
Kemudian Anda mengoptimalkan urutan ini sehingga gerakan tersebut mencapai hasil yang Anda inginkan. Semua perencanaan gerak dalam robotika klasik dilakukan dengan cara ini, dan ini bukanlah hal baru. Hal baru di sini adalah kita akan mempelajari model dunia dan sistem persepsi akan mengekstraksi representasi abstrak yang sesuai.
Sekarang, sebelum saya membahas contoh cara menjalankan sistem ini, Anda dapat membangun sistem AI secara keseluruhan dengan semua komponen berikut: model dunia, fungsi biaya yang dapat dikonfigurasi untuk tugas yang ada, modul pengoptimalan (yaitu, benar-benar mengoptimalkan, menemukan modul tertentu yang menentukan urutan tindakan optimal untuk model dunia) , memori jangka pendek, sistem persepsi, dll.
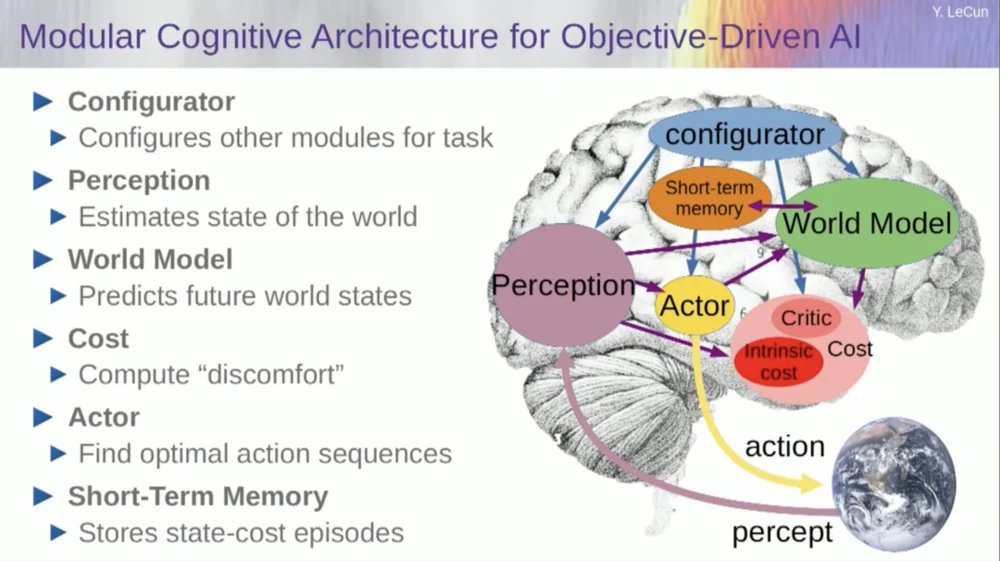
Jadi, bagaimana cara kerjanya? Jika tindakan Anda bukan merupakan tindakan tunggal, namun serangkaian tindakan, dan model dunia Anda sebenarnya adalah sebuah sistem yang memberi tahu Anda, dengan mempertimbangkan keadaan dunia pada waktu T dan kemungkinan tindakan, prediksi keadaan dunia pada waktu T+1 .
Anda ingin memprediksi dampak rangkaian dua tindakan dalam situasi ini. Anda dapat menjalankan model dunia Anda beberapa kali untuk mencapai hal ini.
Dapatkan representasi keadaan dunia awal, masukkan asumsi nol untuk tindakan, gunakan model untuk memprediksi keadaan berikutnya, lalu lakukan tindakan pertama, hitung keadaan berikutnya, hitung biaya, lalu gunakan metode backpropagation dan optimasi berbasis gradien untuk cari tahu apa yang akan meminimalkan Biaya dua tindakan. Ini adalah kontrol prediktif model.
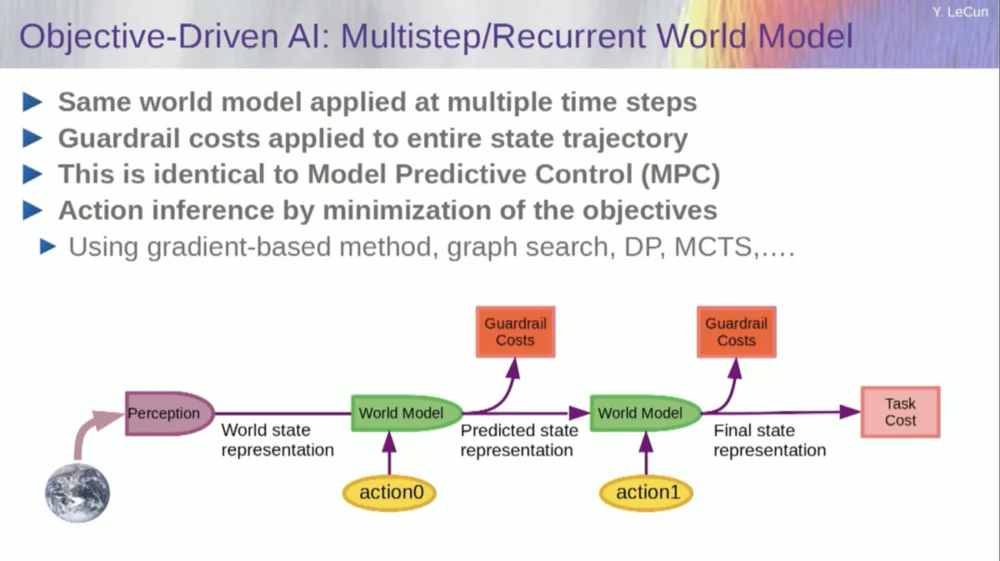
Saat ini, dunia belum sepenuhnya deterministik, jadi Anda harus menggunakan variabel laten agar sesuai dengan model dunia Anda. Variabel laten pada dasarnya adalah variabel yang dapat dialihkan dalam sekumpulan data atau diambil dari suatu distribusi, dan variabel tersebut mewakili peralihan model dunia antara beberapa prediksi yang sesuai dengan observasi.
Yang lebih menarik lagi adalah sistem cerdas saat ini tidak mampu melakukan sesuatu yang dapat dilakukan manusia dan bahkan hewan, yaitu perencanaan hierarkis.
Misalnya, jika Anda merencanakan perjalanan dari New York ke Paris, Anda dapat menggunakan pemahaman Anda tentang dunia, tubuh Anda, dan mungkin gagasan Anda tentang keseluruhan konfigurasi perjalanan dari sini ke Paris untuk merencanakan seluruh perjalanan Anda bersama Anda. kontrol otot tingkat rendah.
Benar? Jika Anda menjumlahkan jumlah langkah pengendalian otot per sepuluh milidetik dari semua hal yang harus Anda lakukan sebelum pergi ke Paris, itu adalah angka yang sangat besar. Jadi yang Anda lakukan adalah merencanakan dengan cara perencanaan hierarkis, di mana Anda memulai dari tingkat yang sangat tinggi dan berkata, oke, untuk sampai ke Paris, saya harus ke bandara dulu, naik pesawat.
Bagaimana cara menuju bandara? Katakanlah saya berada di New York City dan saya harus turun ke bawah dan mencari taksi. Bagaimana caranya aku turun ke bawah? Saya harus bangun dari kursi, membuka pintu, berjalan menuju lift, menekan tombol, dll. Bagaimana cara saya bangun dari kursi?
Pada titik tertentu Anda harus menyatakan hal-hal sebagai tindakan kontrol otot tingkat rendah, namun kami tidak merencanakan semuanya dengan cara tingkat rendah, kami melakukan perencanaan hierarkis.

Bagaimana melakukan hal ini dengan menggunakan sistem AI masih belum terpecahkan dan kami tidak memiliki petunjuk.
Hal ini nampaknya menjadi syarat penting bagi perilaku cerdas.
Jadi, bagaimana kita mempelajari model dunia yang mampu melakukan perencanaan hierarkis, mampu bekerja pada berbagai tingkat abstraksi? Tidak ada seorang pun yang menunjukkan sesuatu yang mendekati ini. Ini adalah tantangan besar. Gambar menunjukkan contoh yang baru saja saya sebutkan.
Jadi, bagaimana kita melatih model dunia ini sekarang? Karena ini memang menjadi masalah besar.
Saya mencoba mencari tahu pada usia berapa bayi mempelajari konsep dasar tentang dunia. Bagaimana mereka mempelajari fisika intuitif, intuisi fisik, dan sebagainya? Hal ini terjadi jauh sebelum mereka mulai mempelajari hal-hal seperti bahasa dan interaksi.
Jadi kemampuan seperti pelacakan wajah sebenarnya terjadi sejak dini. Gerak biologis, pembedaan benda hidup dan benda mati, juga muncul sejak dini. Hal yang sama berlaku untuk keteguhan objek, yang mengacu pada fakta bahwa suatu objek tetap ada ketika objek tersebut ditutup oleh objek lain.
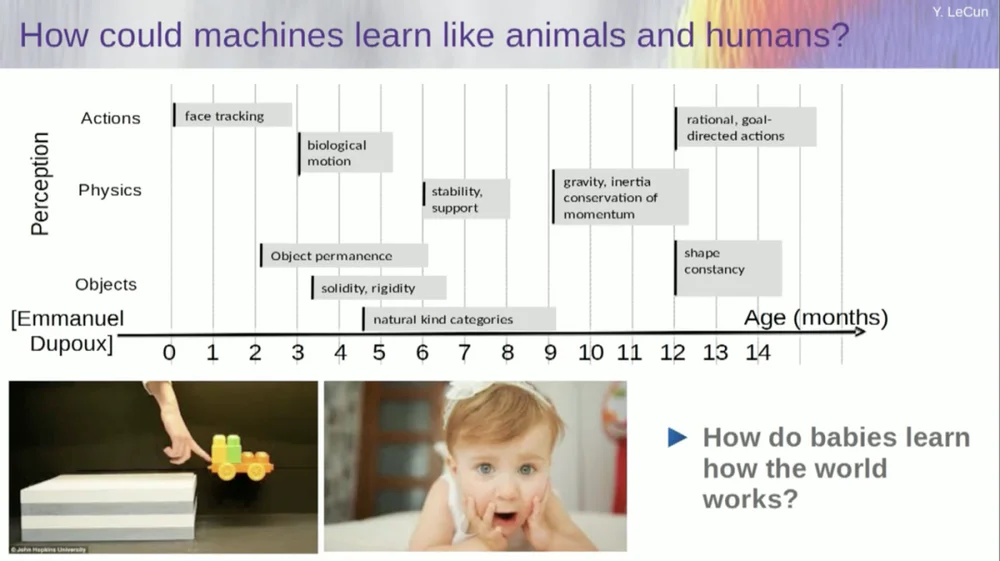
Dan bayi belajar secara alami, Anda tidak perlu memberi mereka nama. Mereka akan mengetahui bahwa kursi, meja, dan kucing itu berbeda. Adapun konsep-konsep seperti stabilitas dan dukungan, seperti gravitasi, inersia, konservasi, dan momentum, sebenarnya baru muncul sekitar usia sembilan bulan.
Ini membutuhkan waktu yang lama. Jadi jika Anda menunjukkan skenario di sebelah kiri kepada bayi berusia enam bulan, di mana kereta berada di atas platform, dan Anda mendorongnya keluar dari platform, kereta tersebut tampak melayang di udara. Bayi berusia enam bulan akan memperhatikan hal ini, sedangkan bayi berusia sepuluh bulan akan merasa bahwa hal ini tidak boleh terjadi dan benda tersebut harus jatuh.
Ketika sesuatu yang tidak terduga terjadi, itu berarti “model dunia” Anda salah. Jadi berhati-hatilah karena itu bisa membunuhmu.
Jadi jenis pembelajaran yang perlu terjadi di sini sangat mirip dengan jenis pembelajaran yang telah kita bahas sebelumnya.
Ambil masukannya, ubahlah dengan cara tertentu, dan latih jaringan saraf besar untuk memprediksi bagian yang hilang. Jika Anda melatih sistem untuk memprediksi apa yang akan terjadi dalam video, sama seperti kita melatih jaringan saraf untuk memprediksi apa yang akan terjadi dalam teks, mungkin sistem tersebut akan dapat mempelajari akal sehat.
Sayangnya, kami telah mencobanya selama sepuluh tahun dan gagal total. Kami belum pernah mendekati sistem yang benar-benar dapat mempelajari pengetahuan umum hanya dengan mencoba memprediksi piksel dalam video.
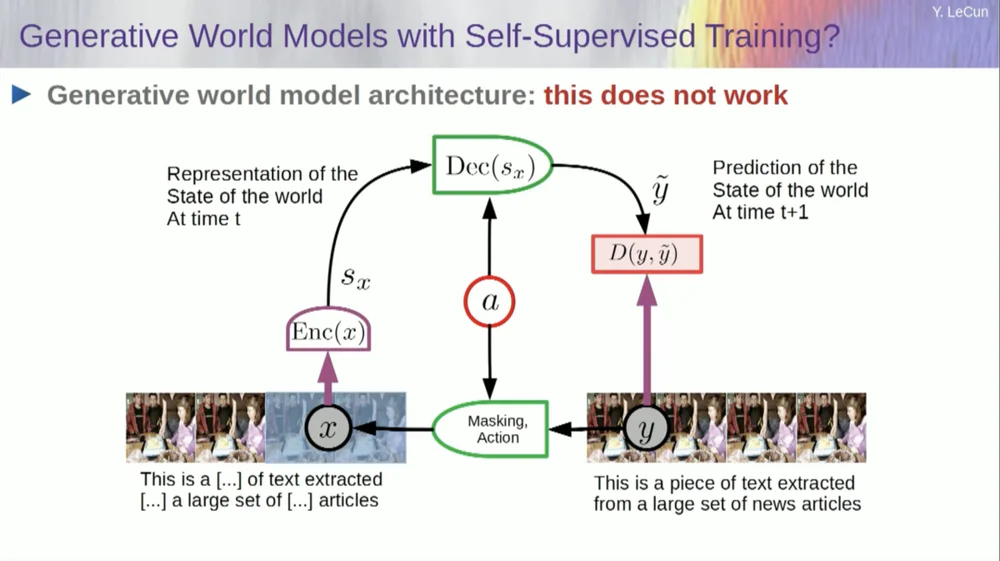
Anda dapat melatih sistem untuk memprediksi video yang terlihat bagus. Ada banyak contoh sistem pembuatan video, namun secara internal sistem tersebut bukanlah model yang baik untuk dunia fisik. Kita tidak bisa melakukan ini pada mereka.
Oke, jadi gagasan bahwa kita akan menggunakan model generatif untuk memprediksi apa yang akan terjadi pada individu, dan sistem akan secara ajaib memahami struktur dunia, adalah sebuah kegagalan total.
Selama dekade terakhir kami telah mencoba banyak pendekatan.
Gagal karena ada banyak kemungkinan masa depan. Dalam ruang terpisah seperti teks, tempat Anda dapat memprediksi kata mana yang akan mengikuti rangkaian kata, Anda dapat menghasilkan distribusi probabilitas atas kemungkinan kata dalam kamus. Namun jika menyangkut bingkai video, kami tidak memiliki cara yang baik untuk merepresentasikan distribusi probabilitas bingkai video. Faktanya, tugas ini sepenuhnya mustahil.

Seperti, saya mengambil video ruangan ini, kan? Saya mengambil kamera dan merekam bagian itu dan kemudian menghentikan videonya. Saya bertanya kepada sistem apa yang akan terjadi selanjutnya. Ini mungkin memprediksi ruangan yang tersisa. Akan ada tembok, akan ada orang yang duduk di atasnya, dan kepadatannya mungkin akan sama dengan yang di sebelah kiri, tapi sangat mustahil untuk secara akurat memprediksi pada tingkat piksel semua detail dari penampilan Anda masing-masing. , tekstur dunia, dan ukuran ruangan yang tepat.
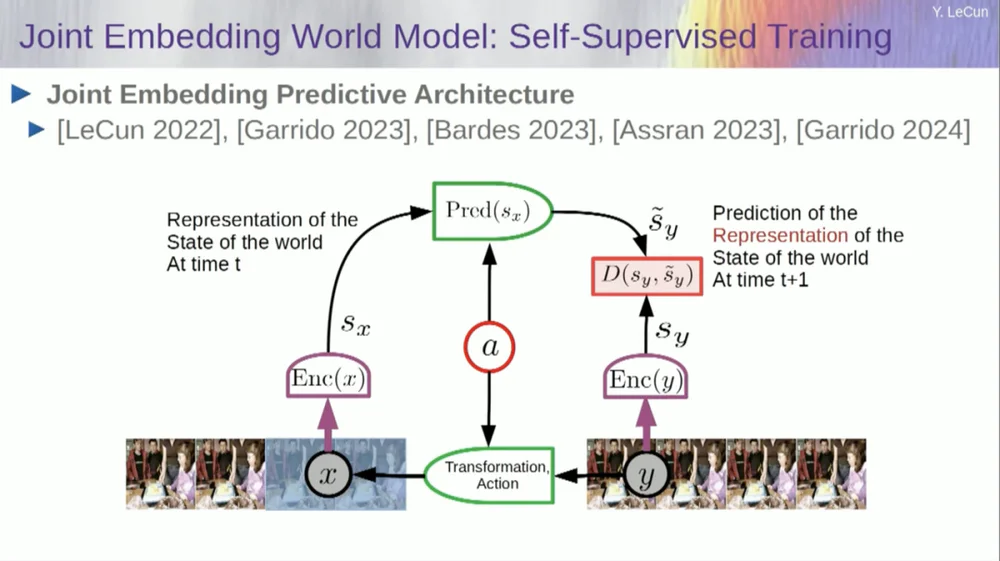
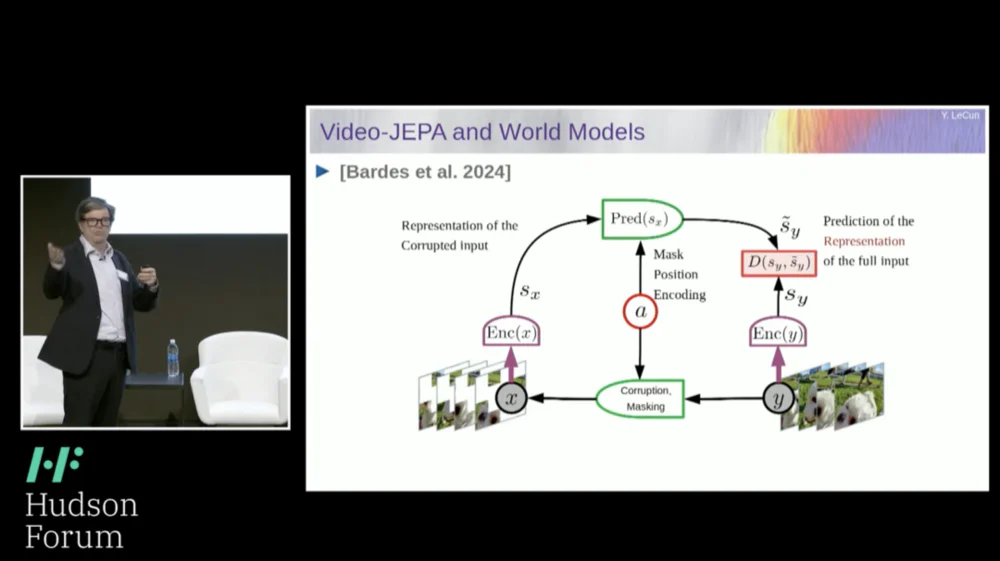
Jadi, solusi yang saya usulkan adalah Joint Embedding Prediction Architecture (JEPA) .
Idenya adalah untuk berhenti memprediksi piksel dan sebagai gantinya mempelajari representasi abstrak tentang cara kerja dunia dan kemudian membuat prediksi dalam ruang representasi tersebut. Itulah arsitekturnya, arsitektur prediksi penyematan bersama. Kedua penyematan ini masing-masing mengambil X (versi yang rusak) dan Y, diproses oleh encoder, lalu sistem dilatih untuk memprediksi representasi Y berdasarkan representasi X.
Sekarang masalahnya adalah jika Anda melatih sistem seperti itu hanya menggunakan penurunan gradien, propagasi mundur untuk meminimalkan kesalahan prediksi, sistem itu akan runtuh. Ia mungkin mempelajari representasi yang konstan sehingga prediksi menjadi sangat sederhana, namun tidak informatif.
Jadi yang saya ingin Anda ingat adalah perbedaan antara autoencoder, arsitektur generatif, autoencoder bertopeng, dll., yang mencoba merekonstruksi prediksi, versus arsitektur penyematan gabungan yang membuat prediksi dalam ruang representasi.
Saya rasa masa depan terletak pada arsitektur penyematan gabungan ini, dan kami memiliki banyak bukti empiris bahwa cara terbaik untuk mempelajari representasi gambar yang baik adalah dengan menggunakan arsitektur pengeditan gabungan.
Semua upaya untuk mempelajari representasi gambar melalui rekonstruksi gagal dan tidak berjalan dengan baik, dan meskipun ada banyak proyek besar yang mengklaim bahwa mereka berhasil, namun kenyataannya tidak, dan kinerja terbaik diperoleh dengan arsitektur di sebelah kanan.
Sekarang, jika dipikir-pikir, inilah inti dari kecerdasan kita: menemukan representasi yang baik dari suatu fenomena sehingga kita dapat membuat prediksi, itulah inti dari sains.
nyata. Bayangkan saja, jika Anda ingin memprediksi lintasan suatu planet, planet adalah objek yang sangat kompleks, sangat besar, memiliki berbagai karakteristik seperti cuaca, suhu, dan kepadatan.
Walaupun merupakan benda yang kompleks, namun untuk memprediksi lintasan suatu planet, Anda hanya perlu mengetahui 6 angka: 3 koordinat posisi dan 3 vektor kecepatan, itu saja, tidak perlu melakukan apa-apa lagi. Ini adalah contoh yang sangat penting yang benar-benar menunjukkan bahwa inti dari kekuatan prediksi terletak pada menemukan representasi yang baik dari hal-hal yang kita amati.

Jadi, bagaimana kita melatih sistem seperti itu?
Jadi, Anda ingin mencegah sistem mogok. Salah satu cara untuk melakukan ini adalah dengan menggunakan semacam fungsi biaya yang mengukur kandungan informasi dari keluaran representasi oleh encoder dan mencoba memaksimalkan kandungan informasi dan meminimalkan informasi negatif. Sistem pelatihan Anda harus secara bersamaan mengekstrak informasi sebanyak mungkin dari masukan sambil meminimalkan kesalahan prediksi dalam ruang representasi tersebut.
Sistem akan menemukan trade-off antara mengekstraksi informasi sebanyak mungkin dan tidak mengekstraksi informasi yang tidak dapat diprediksi. Anda akan mendapatkan ruang representasi yang bagus di mana prediksi dapat dibuat.
Sekarang, bagaimana Anda mengukur informasi? Di sinilah segalanya menjadi sedikit aneh. Saya akan melewatkan ini.
Mesin akan melampaui kecerdasan manusia dan aman serta terkendali
Sebenarnya ada cara untuk memahami hal ini secara matematis melalui pelatihan, model berbasis energi, dan fungsi energi, tetapi saya tidak punya waktu untuk membahasnya.
Pada dasarnya, saya memberi tahu Anda beberapa hal berbeda di sini: tinggalkan model generatif demi arsitektur JEPA, tinggalkan model probabilistik demi model berbasis energi, tinggalkan metode pembelajaran kontrastif, dan pembelajaran penguatan. Saya sudah mengatakan ini selama 10 tahun.
Dan inilah empat pilar pembelajaran mesin yang paling populer saat ini. Jadi saya mungkin tidak terlalu populer saat ini.
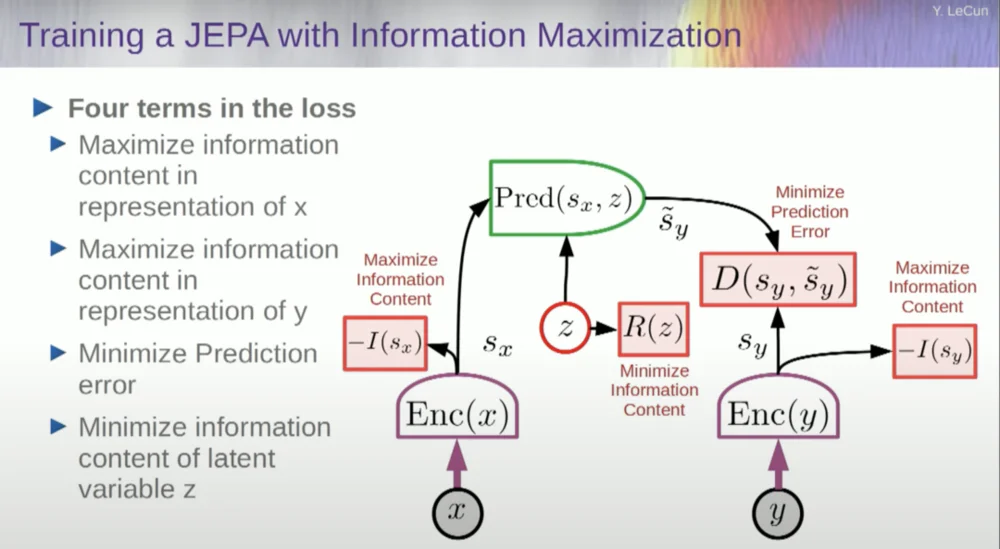
Salah satu pendekatannya adalah memperkirakan kandungan informasi, mengukur kandungan informasi yang berasal dari encoder.
Saat ini ada enam cara berbeda untuk mencapai hal ini. Sebenarnya, ada metode yang disebut MCR, dari rekan saya di NYU, yang mencegah sistem mogok dan menghasilkan konstanta.
Ambil variabel dari encoder dan pastikan variabel tersebut memiliki standar deviasi bukan nol. Anda dapat memasukkan ini ke dalam fungsi biaya dan memastikan bobot dicari dan variabel tidak diciutkan dan menjadi konstanta. Ini relatif sederhana.
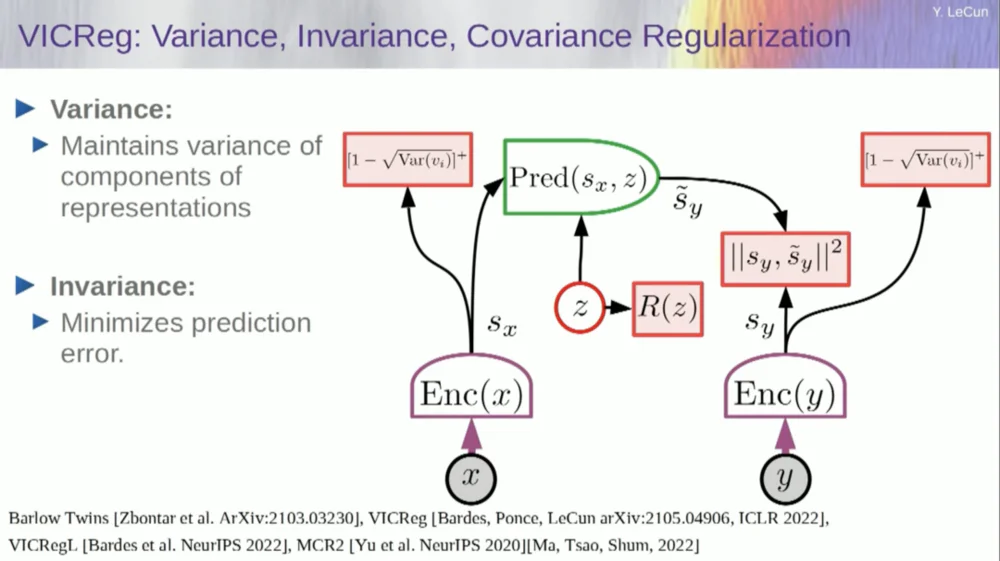
Masalahnya sekarang adalah sistem bisa "mencurangi" dan membuat semua variabel sama atau berkorelasi tinggi. Oleh karena itu, Anda perlu menambahkan suku lain, suku di luar diagonal yang diperlukan untuk meminimalkan matriks kovarians variabel-variabel ini, untuk memastikan bahwa variabel-variabel tersebut terkait.
Tentu saja ini tidak cukup, karena variabel-variabelnya mungkin masih bergantung, tetapi tidak berhubungan. Oleh karena itu, kami mengadopsi metode lain untuk memperluas dimensi SX ke ruang berdimensi lebih tinggi VX dan menerapkan regularisasi varians-kovarians dalam ruang ini untuk memastikan bahwa persyaratan terpenuhi.
Ada trik lain disini, karena yang saya maksimalkan adalah batas atas isi informasi. Saya ingin konten informasi aktual mengikuti maksimalisasi batas atas saya. Yang saya perlukan adalah batas bawah agar menembus batas bawah dan informasinya bertambah. Sayangnya, kami tidak memiliki informasi tentang batas bawah, atau setidaknya kami tidak tahu cara menghitungnya.
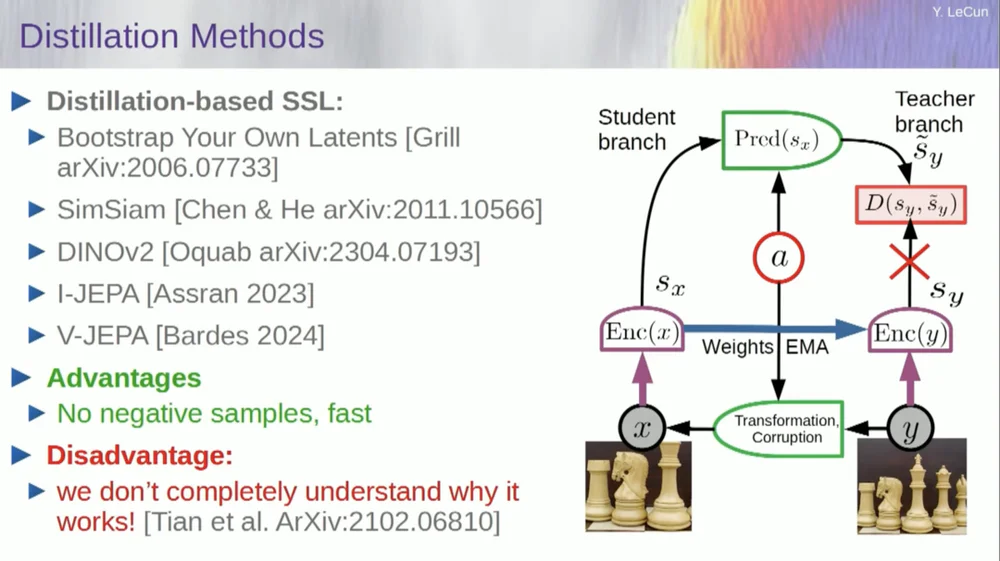
Ada rangkaian metode kedua yang disebut "metode gaya distilasi".
Metode ini bekerja dengan cara yang misterius. Jika Anda ingin tahu persis siapa yang melakukan apa, Anda harus bertanya pada pria yang duduk di sini di Grill.
Dia memiliki esai pribadi tentang hal ini yang menjelaskannya dengan sangat baik. Ide intinya adalah memperbarui hanya satu bagian model tanpa melakukan propagasi mundur gradien di bagian lain dan membagi bobot dengan cara yang menarik. Ada juga banyak makalah tentang aspek ini.
Pendekatan ini bekerja dengan baik jika Anda ingin melatih sistem yang sepenuhnya diawasi sendiri untuk menghasilkan representasi gambar yang baik. Penghancuran gambar dilakukan melalui masking, dan beberapa pekerjaan terbaru yang kami lakukan untuk video memungkinkan kami melatih sistem untuk mengekstrak representasi video yang bagus untuk digunakan dalam tugas hilir seperti video pengenalan tindakan, dll. Anda dapat melihat bahwa menutupi sebagian besar video dan membuat prediksi melalui proses ini menggunakan trik distilasi dalam ruang representasi untuk mencegah keruntuhan. Ini berhasil dengan baik.
Jadi jika kita berhasil dalam proyek ini dan mendapatkan sistem yang mampu menalar, merencanakan, dan memahami dunia fisik, maka seperti inilah semua interaksi kita di masa depan.
Diperlukan waktu bertahun-tahun, bahkan mungkin satu dekade, agar semuanya berfungsi dengan baik. Mark Zuckerberg terus bertanya kepada saya berapa lama waktu yang dibutuhkan. Kalau kita berhasil melakukan itu, oke, kita akan punya sistem yang memediasi semua interaksi kita dengan dunia digital. Mereka akan menjawab semua pertanyaan kami.
Mereka akan bersama kita untuk waktu yang lama dan pada dasarnya akan menjadi gudang seluruh pengetahuan manusia. Ini terasa seperti masalah infrastruktur, seperti Internet. Ini bukan sekedar produk dan lebih merupakan infrastruktur.
Platform AI ini harus bersifat open source. IBM dan Meta berpartisipasi dalam kelompok yang disebut Artificial Intelligence Alliance (Aliansi Kecerdasan Buatan) yang mempromosikan platform kecerdasan buatan sumber terbuka. Kami memerlukan platform ini yang bersifat open source karena kami memerlukan keragaman dalam sistem AI ini.

Kita membutuhkan mereka untuk memahami semua bahasa, semua budaya, semua sistem nilai di dunia, dan Anda tidak akan mendapatkannya hanya dari satu sistem yang diproduksi oleh sebuah perusahaan di Pantai Barat atau Pantai Timur Amerika. Amerika. Ini harus menjadi kontribusi dari seluruh dunia.
Tentu saja pelatihan model keuangan membutuhkan biaya yang sangat mahal sehingga hanya sedikit perusahaan yang mampu melakukannya. Jika perusahaan seperti Meta dapat menyediakan model yang mendasarinya sebagai open source, maka dunia dapat menyempurnakannya untuk tujuan mereka sendiri. Filosofi inilah yang dianut oleh Meta dan IBM.

Jadi AI open source bukan hanya sebuah ide bagus, namun juga diperlukan untuk keragaman budaya dan bahkan mungkin pelestarian demokrasi.
Pelatihan dan penyesuaian akan dilakukan melalui crowdsourcing atau oleh ekosistem startup dan perusahaan lain.
Salah satu hal yang mendorong pertumbuhan ekosistem startup AI adalah ketersediaan model AI open source tersebut. Berapa lama waktu yang dibutuhkan untuk mencapai kecerdasan buatan secara umum? Entahlah, bisa memakan waktu bertahun-tahun hingga puluhan tahun.

Banyak perubahan yang terjadi, dan masih banyak permasalahan yang perlu diselesaikan. Hal ini hampir pasti akan lebih sulit dari yang kita kira. Hal ini tidak terjadi dalam satu hari, namun merupakan evolusi bertahap dan bertahap.
Jadi bukan suatu saat kita akan menemukan rahasia kecerdasan buatan secara umum, menyalakan mesin dan langsung memiliki kecerdasan super, dan kita semua akan dimusnahkan oleh kecerdasan super, bukan, bukan itu masalahnya.
Mesin akan melampaui kecerdasan manusia, namun mereka akan terkendali karena mereka digerakkan oleh tujuan. Kami menetapkan tujuan untuk mereka dan mereka mencapainya. Seperti kebanyakan dari kita di sini adalah pemimpin di industri atau akademisi.
Kami bekerja dengan orang-orang yang lebih pintar dari kami, dan saya juga melakukannya. Hanya karena ada banyak orang yang lebih pintar dari saya bukan berarti mereka ingin mendominasi atau mengambil alih, itulah kenyataannya. Tentu saja ada resiko di balik ini, tapi saya akan membiarkannya untuk dibahas nanti, terima kasih banyak.