Dengan pesatnya perkembangan teknologi AI, permintaan akan model bahasa visual semakin meningkat dari hari ke hari, namun kebutuhan sumber daya komputasi yang tinggi membatasi penerapannya pada perangkat biasa. Editor Downcodes hari ini akan memperkenalkan kepada Anda model bahasa visual ringan yang disebut SmolVLM, yang dapat berjalan secara efisien pada perangkat dengan sumber daya terbatas, seperti laptop dan GPU tingkat konsumen. Kemunculan SmolVLM telah memberikan lebih banyak kesempatan kepada pengguna untuk merasakan teknologi AI yang canggih, menurunkan ambang batas penggunaan, dan juga memberi pengembang alat penelitian yang lebih nyaman.
Dalam beberapa tahun terakhir, terdapat peningkatan permintaan terhadap penerapan model pembelajaran mesin dalam tugas penglihatan dan bahasa, namun sebagian besar model memerlukan sumber daya komputasi yang besar dan tidak dapat berjalan secara efisien di perangkat pribadi. Terutama perangkat kecil seperti laptop, GPU konsumen, dan perangkat seluler menghadapi tantangan besar saat memproses tugas bahasa visual.
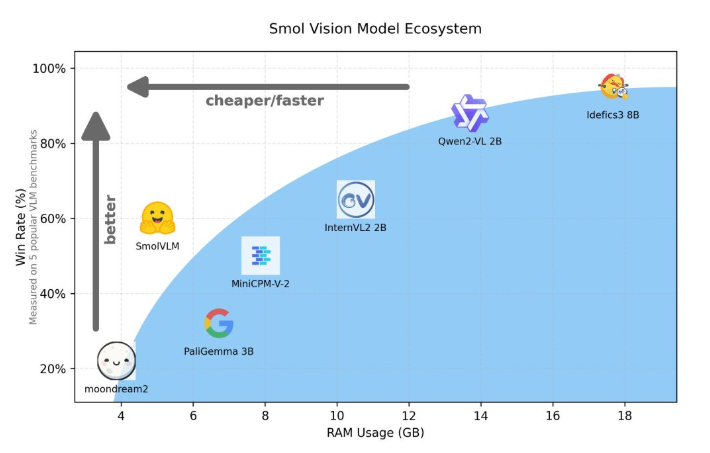
Mengambil Qwen2-VL sebagai contoh, meskipun memiliki kinerja yang sangat baik, ia memiliki persyaratan perangkat keras yang tinggi, sehingga membatasi kegunaannya dalam aplikasi waktu nyata. Oleh karena itu, mengembangkan model ringan untuk dijalankan dengan sumber daya yang lebih rendah telah menjadi kebutuhan yang penting.
Hugging Face baru-baru ini merilis SmolVLM, model bahasa visual parameter 2B yang dirancang khusus untuk penalaran sisi perangkat. SmolVLM mengungguli model serupa lainnya dalam hal penggunaan memori GPU dan kecepatan pembuatan token. Fitur utamanya adalah kemampuan untuk berjalan secara efisien pada perangkat yang lebih kecil, seperti laptop atau GPU kelas konsumen, tanpa mengorbankan kinerja. SmolVLM menemukan keseimbangan ideal antara kinerja dan efisiensi, memecahkan masalah yang sulit diatasi pada model serupa sebelumnya.
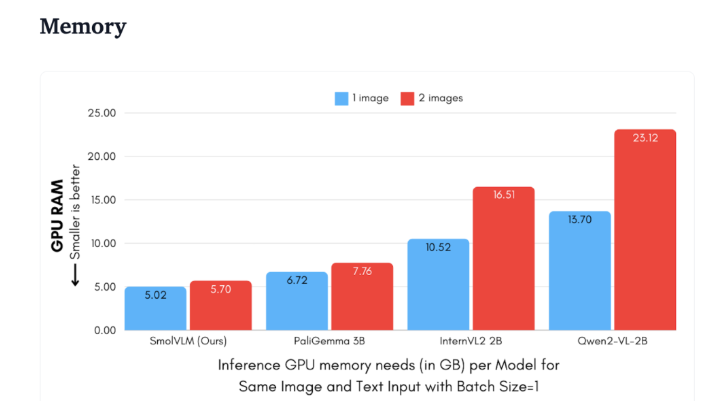
Dibandingkan dengan Qwen2-VL2B, SmolVLM menghasilkan token 7,5 hingga 16 kali lebih cepat, berkat arsitekturnya yang dioptimalkan, sehingga memungkinkan inferensi ringan. Efisiensi ini tidak hanya membawa manfaat praktis bagi pengguna akhir, namun juga sangat meningkatkan pengalaman pengguna.
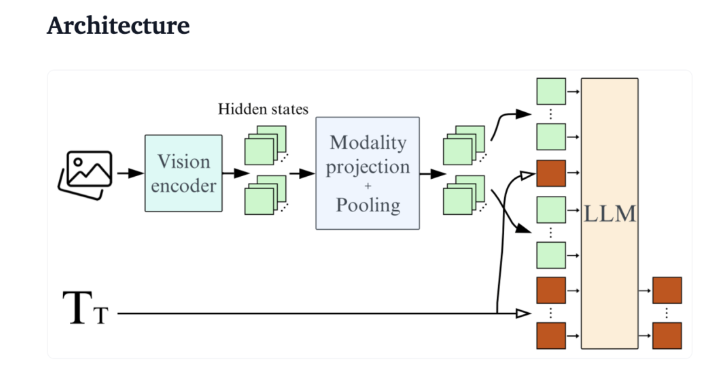
Dari sudut pandang teknis, SmolVLM memiliki arsitektur optimal yang mendukung inferensi sisi perangkat yang efisien. Pengguna bahkan dapat dengan mudah melakukan penyesuaian di Google Colab, sehingga sangat menurunkan ambang batas untuk eksperimen dan pengembangan.
Karena jejak memorinya yang kecil, SmolVLM dapat berjalan dengan lancar pada perangkat yang sebelumnya tidak dapat menampung model serupa. Saat menguji video YouTube 50-frame, SmolVLM berkinerja baik, mencetak 27,14%, dan mengungguli dua model yang lebih intensif sumber daya dalam hal konsumsi sumber daya, menunjukkan kemampuan beradaptasi dan fleksibilitas yang kuat.
SmolVLM merupakan tonggak penting dalam bidang model bahasa visual. Peluncurannya memungkinkan tugas bahasa visual yang kompleks dijalankan di perangkat sehari-hari, sehingga mengisi kesenjangan penting dalam alat AI saat ini.
SmolVLM tidak hanya unggul dalam kecepatan dan efisiensi, tetapi juga memberi pengembang dan peneliti alat yang ampuh untuk memfasilitasi pemrosesan bahasa visual tanpa biaya perangkat keras yang mahal. Seiring dengan semakin populernya teknologi AI, model seperti SmolVLM akan membuat kemampuan pembelajaran mesin yang canggih menjadi lebih mudah diakses.
demo: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
Secara keseluruhan, SmolVLM telah menetapkan tolok ukur baru untuk model bahasa visual yang ringan. Performanya yang efisien dan penggunaan yang mudah akan sangat mendorong mempopulerkan dan mengembangkan teknologi AI. Kami menantikan lebih banyak inovasi serupa di masa depan, sehingga teknologi AI dapat memberikan manfaat bagi lebih banyak orang.