Dalam beberapa tahun terakhir, biaya pelatihan model bahasa skala besar masih tinggi, dan hal ini menjadi faktor penting yang menghambat pengembangan AI. Cara mengurangi biaya pelatihan dan meningkatkan efisiensi telah menjadi fokus industri. Editor Downcodes memberi Anda interpretasi makalah terbaru dari para peneliti di Universitas Harvard dan Universitas Stanford. Makalah ini mengusulkan aturan penskalaan "sadar-akurasi" yang secara efektif mengurangi biaya pelatihan dengan menyesuaikan akurasi pelatihan model, bahkan dalam beberapa kasus dalam hal ini, ini juga dapat meningkatkan kinerja model. Mari kita lihat lebih dekat penelitian menarik ini.
Di bidang kecerdasan buatan, skala yang lebih besar tampaknya berarti kemampuan yang lebih besar pula. Dalam upaya mendapatkan model bahasa yang lebih canggih, perusahaan teknologi besar dengan panik menyusun parameter model dan data pelatihan, namun ternyata biayanya juga meningkat. Apakah tidak ada cara yang hemat biaya dan efisien untuk melatih model bahasa?
Para peneliti dari Universitas Harvard dan Stanford baru-baru ini menerbitkan sebuah makalah di mana mereka menemukan bahwa keakuratan pelatihan model seperti kunci tersembunyi yang dapat membuka “kode biaya” pelatihan model bahasa.
Apa yang dimaksud dengan akurasi model? Sederhananya, ini mengacu pada parameter model dan jumlah digit yang digunakan dalam proses perhitungan. Model pembelajaran mendalam tradisional biasanya menggunakan angka floating point 32-bit (FP32) untuk pelatihan, namun dalam beberapa tahun terakhir, seiring dengan perkembangan perangkat keras, jenis angka dengan presisi lebih rendah digunakan, seperti angka floating point 16-bit (FP16) atau 8- bit integers (INT8) Pelatihan sudah dimungkinkan.
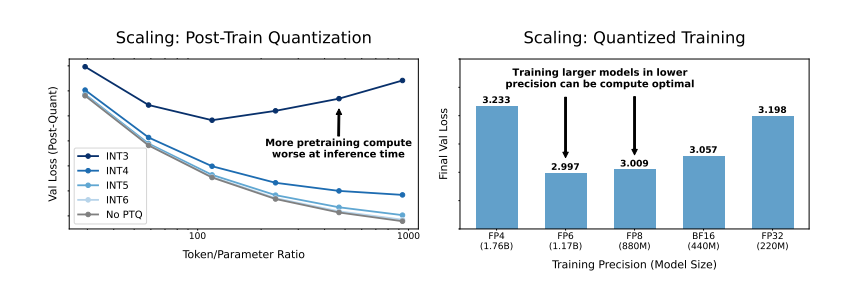
Jadi, apa dampak pengurangan akurasi model terhadap performa model? Pertanyaan inilah yang ingin dieksplorasi dalam makalah ini. Melalui sejumlah besar eksperimen, para peneliti menganalisis perubahan biaya dan kinerja pelatihan model dan inferensi dengan akurasi yang berbeda, dan mengusulkan seperangkat aturan penskalaan "sadar-akurasi" yang baru.
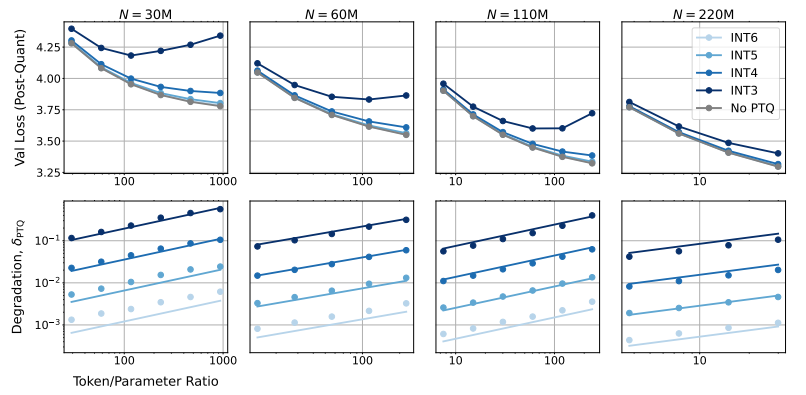
Mereka menemukan bahwa pelatihan dengan presisi lebih rendah secara efektif mengurangi "jumlah parameter efektif" model, sehingga mengurangi jumlah komputasi yang diperlukan untuk pelatihan. Artinya, dengan anggaran komputasi yang sama, kita dapat melatih model dengan skala yang lebih besar, atau pada skala yang sama, menggunakan akurasi yang lebih rendah dapat menghemat banyak sumber daya komputasi.
Yang lebih mengejutkan lagi, para peneliti juga menemukan bahwa dalam beberapa kasus, pelatihan dengan presisi yang lebih rendah justru dapat meningkatkan performa model! Misalnya, bagi model yang memerlukan "kuantisasi pasca-pelatihan" Jika model menggunakan presisi yang lebih rendah selama tahap pelatihan, model akan lebih tahan terhadap pengurangan presisi setelah kuantisasi, sehingga menunjukkan kinerja yang lebih baik selama tahap inferensi.
Jadi, presisi mana yang harus kita pilih untuk melatih model tersebut? Dengan menganalisis aturan penskalaannya, para peneliti sampai pada beberapa kesimpulan menarik:
Pelatihan presisi 16-bit tradisional mungkin tidak optimal. Penelitian mereka menunjukkan bahwa presisi 7-8 digit mungkin merupakan pilihan yang lebih hemat biaya.
Juga tidak bijaksana untuk secara membabi buta mengikuti pelatihan dengan presisi sangat rendah (seperti 4 digit). Karena dengan akurasi yang sangat rendah, jumlah parameter efektif model akan turun tajam untuk mempertahankan performa, kita perlu meningkatkan ukuran model secara signifikan, yang pada gilirannya akan menyebabkan biaya komputasi yang lebih tinggi.
Akurasi pelatihan optimal dapat bervariasi untuk model dengan ukuran berbeda. Untuk model yang memerlukan banyak "pelatihan berlebihan", seperti seri Llama-3 dan Gemma-2, pelatihan dengan akurasi lebih tinggi mungkin lebih hemat biaya.
Penelitian ini memberikan perspektif baru dalam memahami dan mengoptimalkan pelatihan model bahasa. Hal ini memberi tahu kita bahwa pilihan akurasi tidak bersifat statis, namun perlu dipertimbangkan berdasarkan ukuran model tertentu, volume data pelatihan, dan skenario aplikasi.
Tentu saja, ada beberapa keterbatasan dalam penelitian ini. Misalnya, model yang mereka gunakan berskala relatif kecil, dan hasil eksperimen mungkin tidak dapat digeneralisasikan secara langsung ke model berskala lebih besar. Selain itu, mereka hanya fokus pada fungsi kerugian model dan tidak mengevaluasi performa model pada tugas hilir.
Meskipun demikian, penelitian ini masih memiliki implikasi penting. Hal ini mengungkap hubungan kompleks antara akurasi model, performa model, dan biaya pelatihan, serta memberi kita wawasan berharga untuk merancang dan melatih model bahasa yang lebih canggih dan ekonomis di masa depan.
Makalah: https://arxiv.org/pdf/2411.04330
Secara keseluruhan, penelitian ini memberikan ide dan metode baru untuk mengurangi biaya pelatihan model bahasa skala besar, dan memberikan nilai referensi penting untuk pengembangan AI di masa depan. Editor Downcodes menantikan kemajuan lebih lanjut dalam penelitian akurasi model dan berkontribusi dalam membangun model AI yang lebih hemat biaya.