Editor Downcodes mengetahui bahwa Ai2, sebuah lembaga penelitian AI nirlaba, baru-baru ini merilis seri model bahasa OLMo2 baru, yang merupakan generasi kedua dari seri "Model Bahasa Terbuka" (OLMo). OLMo2 menganut konsep kode sumber terbuka sepenuhnya, dan data pelatihan, alat, dan kodenya sepenuhnya terbuka. Hal ini sangat penting dalam bidang AI saat ini dan mewakili pencapaian baru dalam pengembangan AI sumber terbuka. Tidak seperti model lain yang mengklaim sebagai "terbuka", OLMo2 secara ketat mengikuti definisi Inisiatif Sumber Terbuka, memenuhi standar ketat AI sumber terbuka, dan memberikan dukungan teknis yang kuat dan sumber daya pembelajaran yang berharga kepada komunitas AI.
Ai2, sebuah organisasi penelitian AI nirlaba, baru-baru ini merilis seri OLMo2 barunya, yang merupakan model generasi kedua dari seri "Model Bahasa Terbuka" (OLMo) yang diluncurkan oleh organisasi tersebut. Peluncuran OLMo2 tidak hanya memberikan dukungan teknis yang kuat untuk komunitas AI, tetapi juga mewakili perkembangan terbaru dari AI open source dengan kode sumber yang sepenuhnya terbuka.
Tidak seperti model bahasa "terbuka" lainnya yang saat ini ada di pasaran seperti seri Llama Meta, OLMo2 memenuhi definisi ketat dari Inisiatif Sumber Terbuka, yang berarti bahwa data pelatihan, alat, dan kode yang digunakan untuk pengembangannya bersifat publik dan dapat diakses oleh siapa saja menggunakan. Sebagaimana didefinisikan oleh Open Source Initiative, OLMo2 memenuhi persyaratan organisasi untuk standar "AI open source", yang diselesaikan pada bulan Oktober tahun ini.
Ai2 menyebutkan dalam blognya bahwa selama proses pengembangan OLMo2, semua data pelatihan, kode, rencana pelatihan, metode evaluasi, dan pos pemeriksaan perantara sepenuhnya terbuka, yang bertujuan untuk mendorong inovasi dan penemuan dalam komunitas sumber terbuka melalui sumber daya bersama. “Dengan berbagi data, solusi, dan temuan kami secara terbuka, kami berharap dapat menyediakan sumber daya bagi komunitas open source untuk menemukan metode baru dan teknologi inovatif.”
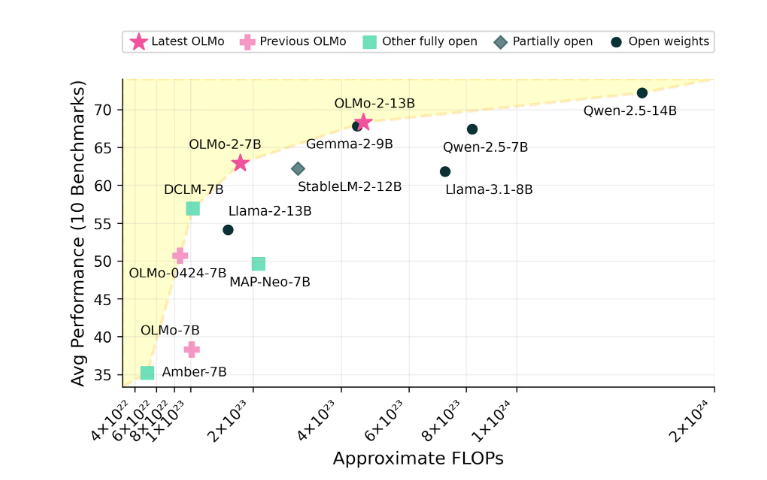
Seri OLMo2 mencakup dua versi: satu adalah OLMo7B dengan 7 miliar parameter, dan yang lainnya adalah OLMo13B dengan 13 miliar parameter. Jumlah parameter secara langsung memengaruhi performa model, dan versi dengan lebih banyak parameter biasanya dapat menangani tugas yang lebih kompleks. OLMo2 bekerja dengan baik pada tugas-tugas teks umum, mampu menyelesaikan tugas-tugas seperti menjawab pertanyaan, merangkum dokumen, dan menulis kode.

Catatan sumber gambar: Gambar dihasilkan oleh AI, dan gambar tersebut disahkan oleh penyedia layanan Midjourney
Untuk melatih OLMo2, Ai2 menggunakan kumpulan data yang berisi lima triliun token. Token adalah unit terkecil dalam model bahasa. 1 juta token kira-kira sama dengan 750.000 kata. Data pelatihan mencakup konten dari situs web berkualitas tinggi, makalah akademis, papan diskusi tanya jawab, dan buku kerja matematika sintetik, dan dipilih dengan cermat untuk memastikan efisiensi dan keakuratan model.
Ai2 yakin dengan kinerja OLMo2, mengklaim bahwa ia telah bersaing dengan model open source seperti Meta's Llama3.1 dalam hal kinerja. Ai2 menunjukkan bahwa kinerja OLMo27B bahkan melampaui Llama3.18B dan menjadi salah satu model bahasa terbuka penuh terkuat saat ini. Seluruh model OLMo2 beserta komponennya dapat diunduh secara gratis melalui situs resmi Ai2 dan mengikuti lisensi Apache2.0, yang berarti model tersebut tidak hanya dapat digunakan untuk penelitian tetapi juga untuk aplikasi komersial.
Sifat open source dari OLMo2 akan sangat mendorong kerja sama terbuka dan inovasi di bidang AI, memberikan ruang pengembangan yang lebih luas bagi para peneliti dan pengembang. Kami menantikan OLMo2 menghadirkan lebih banyak terobosan dan aplikasi di masa depan.