Laporan editor Downcode: Dalam beberapa tahun terakhir, teknologi animasi gambar berbasis audio telah berkembang pesat, namun model yang ada masih memiliki hambatan dalam hal efisiensi dan durasi. Untuk mengatasi masalah ini, para peneliti telah mengembangkan teknologi baru yang disebut JoyVASA, yang secara signifikan meningkatkan kualitas dan efisiensi animasi gambar berbasis audio melalui desain dua tahap yang cerdik. JoyVASA tidak hanya mampu menghasilkan video animasi yang lebih panjang, namun juga mendukung animasi wajah hewan dan menunjukkan kompatibilitas multi-bahasa yang baik, menghadirkan kemungkinan-kemungkinan baru dalam bidang produksi animasi.
Baru-baru ini, para peneliti telah mengusulkan teknologi baru yang disebut JoyVASA, yang bertujuan untuk meningkatkan efek animasi gambar berbasis audio. Dengan pengembangan berkelanjutan model pembelajaran mendalam dan difusi, animasi potret berbasis audio telah membuat kemajuan signifikan dalam kualitas video dan akurasi sinkronisasi bibir. Namun, kompleksitas model yang ada meningkatkan efisiensi pelatihan dan inferensi, sekaligus membatasi durasi dan kontinuitas antar-frame video.
JoyVASA mengadopsi desain dua tahap. Tahap pertama memperkenalkan kerangka representasi wajah yang dipisahkan untuk memisahkan ekspresi wajah dinamis dari representasi wajah tiga dimensi yang statis.
Pemisahan ini memungkinkan sistem untuk menggabungkan model wajah 3D statis dengan rangkaian tindakan dinamis untuk menghasilkan video animasi yang lebih panjang. Pada tahap kedua, tim peneliti melatih transformator difusi yang dapat menghasilkan rangkaian tindakan langsung dari isyarat audio, sebuah proses yang tidak bergantung pada identitas karakter. Terakhir, generator berdasarkan pelatihan tahap pertama mengambil representasi wajah 3D dan urutan tindakan yang dihasilkan sebagai masukan untuk merender efek animasi berkualitas tinggi.
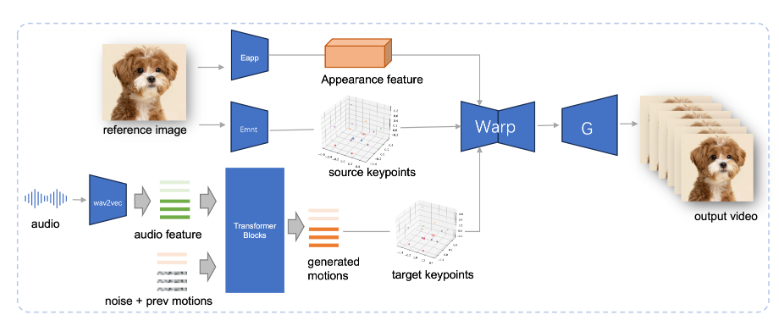
Khususnya, JoyVASA tidak terbatas pada animasi potret manusia, namun juga dapat menganimasikan wajah hewan dengan mulus. Model ini dilatih pada kumpulan data campuran, yang menggabungkan data pribadi berbahasa Mandarin dan data publik berbahasa Inggris, sehingga menunjukkan kemampuan dukungan multi-bahasa yang baik. Hasil eksperimen membuktikan keefektifan metode ini. Penelitian di masa depan akan fokus pada peningkatan kinerja real-time dan menyempurnakan kontrol ekspresi untuk lebih memperluas penerapan kerangka ini dalam animasi gambar.
Kemunculan JoyVASA menandai terobosan penting dalam teknologi animasi berbasis audio, yang mempromosikan kemungkinan-kemungkinan baru di bidang animasi.
Pintu masuk proyek: https://jdh-algo.github.io/JoyVASA/
Inovasi teknologi JoyVASA terletak pada desain dua tahap yang efisien dan kemampuan dukungan multi-bahasa yang kuat, yang memberikan solusi produksi animasi yang lebih nyaman dan efisien. Di masa depan, dengan semakin berkembangnya teknologi, JoyVASA diharapkan dapat digunakan secara luas di lebih banyak bidang, sehingga menghadirkan karya animasi yang lebih realistis dan menarik. Menantikan lebih banyak terobosan teknologi dan memimpin babak baru dalam perkembangan industri animasi!