Tim peneliti AI Apple merilis generasi baru keluarga model bahasa besar multi-modal MM1.5, yang dapat mengintegrasikan beberapa tipe data seperti teks dan gambar, dan telah menunjukkan kinerja yang kuat dalam tugas-tugas seperti menjawab pertanyaan visual, pembuatan gambar, dan multi- kemampuan interpretasi data modal. MM1.5 mengatasi kesulitan model multi-modal sebelumnya dalam memproses gambar kaya teks dan tugas visual yang mendetail. Melalui pendekatan berpusat data yang inovatif, model ini menggunakan data OCR resolusi tinggi dan deskripsi gambar sintetis untuk meningkatkan kinerja model secara signifikan. . Pemahaman. Editor Downcodes akan memberi Anda pemahaman mendalam tentang inovasi MM1.5 dan kinerjanya yang luar biasa dalam berbagai pengujian benchmark.
Baru-baru ini, tim peneliti AI Apple meluncurkan generasi baru rangkaian model bahasa besar multi-modal (MLLM) - MM1.5. Rangkaian model ini dapat menggabungkan beberapa tipe data seperti teks dan gambar, menunjukkan kepada kita kemampuan baru AI untuk memahami tugas-tugas kompleks. Tugas-tugas seperti menjawab pertanyaan visual, pembuatan gambar, dan interpretasi data multimodal semuanya dapat diselesaikan dengan lebih baik dengan bantuan model ini.
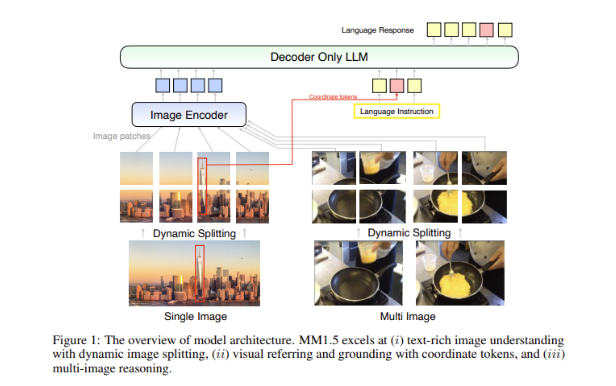
Tantangan besar dalam model multimodal adalah bagaimana mencapai interaksi yang efektif antara tipe data yang berbeda. Model masa lalu sering kali kesulitan dengan gambar yang kaya teks atau tugas penglihatan yang mendetail. Oleh karena itu, tim peneliti Apple memperkenalkan metode pusat data yang inovatif ke dalam model MM1.5, menggunakan data OCR resolusi tinggi dan deskripsi gambar sintetis untuk memperkuat kemampuan pemahaman model.
Metode ini tidak hanya memungkinkan MM1.5 mengungguli model sebelumnya dalam tugas pemahaman visual dan pemosisian, namun juga meluncurkan dua versi khusus model: MM1.5-Video dan MM1.5-UI, yang masing-masing digunakan untuk pemahaman dan pemosisian video. . Analisis antarmuka seluler.
Pelatihan model MM1.5 dibagi menjadi tiga tahap utama.
Tahap pertama adalah pra-pelatihan skala besar, menggunakan 2 miliar pasang data gambar dan teks, 600 juta dokumen teks-gambar yang disisipkan, dan 2 triliun token hanya teks.
Tahap kedua adalah untuk lebih meningkatkan kinerja tugas gambar yang diperkaya teks melalui pra-pelatihan berkelanjutan terhadap 45 juta data OCR berkualitas tinggi dan 7 juta deskripsi sintetis.
Terakhir, pada tahap penyempurnaan yang diawasi, model dioptimalkan menggunakan data gambar tunggal, multi-gambar, dan hanya teks yang dipilih dengan cermat agar lebih baik dalam referensi visual mendetail dan penalaran multi-gambar.
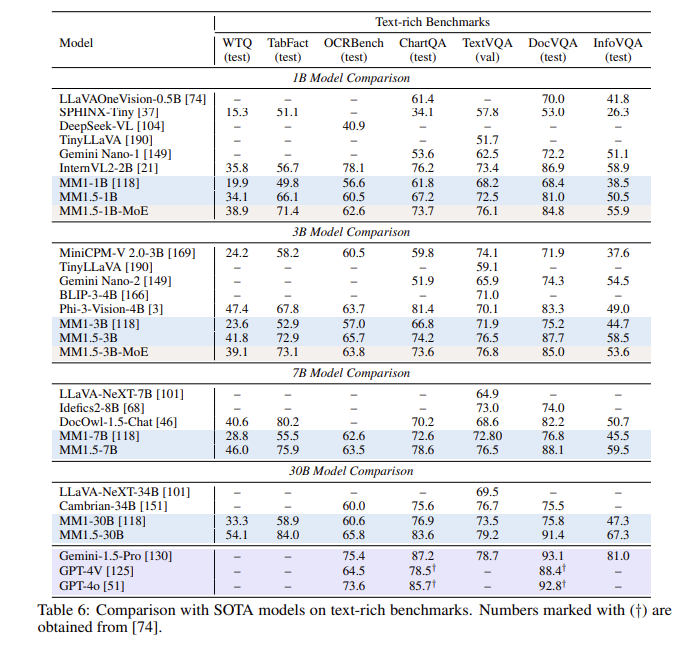
Setelah serangkaian evaluasi, model MM1.5 berkinerja baik dalam beberapa pengujian benchmark, terutama ketika menangani pemahaman gambar kaya teks, dengan peningkatan 1,4 poin dibandingkan model sebelumnya. Selain itu, bahkan MM1.5-Video, yang dirancang khusus untuk pemahaman video, telah mencapai tingkat terdepan dalam tugas-tugas terkait dengan kemampuan multi-modalnya yang kuat.
Rangkaian model MM1.5 tidak hanya menetapkan tolok ukur baru untuk model bahasa besar multi-modal, namun juga menunjukkan potensinya dalam berbagai aplikasi, mulai dari pemahaman teks gambar umum hingga analisis video dan antarmuka pengguna, semuanya dengan kinerja luar biasa.
Menyorot:
**Varian model**: Mencakup model padat dan model MoE dengan parameter dari 1 miliar hingga 30 miliar, memastikan skalabilitas dan penerapan yang fleksibel.
? **Data Pelatihan**: Memanfaatkan 2 miliar pasangan gambar-teks, 600 juta dokumen teks-gambar yang disisipkan, dan 2 triliun token khusus teks.
**Peningkatan kinerja**: Dalam pengujian benchmark yang berfokus pada pemahaman gambar kaya teks, peningkatan sebesar 1,4 poin dicapai dibandingkan model sebelumnya.
Secara keseluruhan, rangkaian model MM1.5 Apple telah membuat kemajuan signifikan di bidang model bahasa besar multi-modal, dan metode inovatif serta kinerja luar biasa memberikan arah baru untuk pengembangan AI di masa depan. Kami menantikan MM1.5 menunjukkan potensinya dalam lebih banyak skenario aplikasi.