Dalam beberapa tahun terakhir, model Transformer dan mekanisme perhatiannya telah membuat kemajuan yang signifikan di bidang model bahasa besar (LLM), namun masalah kerentanan terhadap gangguan dari informasi yang tidak relevan selalu ada. Editor Downcodes akan menafsirkan makalah terbaru untuk Anda, yang mengusulkan model baru yang disebut Transformator Diferensial (DIFF Transformer), yang bertujuan untuk memecahkan masalah gangguan perhatian pada model Transformator dan meningkatkan efisiensi dan akurasi model. Model ini secara efektif menyaring informasi yang tidak relevan melalui mekanisme perhatian diferensial yang inovatif, memungkinkan model untuk lebih fokus pada informasi penting, sehingga mencapai peningkatan yang signifikan dalam berbagai aspek, termasuk pemodelan bahasa, pemrosesan teks panjang, pengambilan informasi penting, dan Mengurangi ilusi model, dll. .
Model bahasa besar (LLM) akhir-akhir ini berkembang pesat, di mana model Transformer memainkan peran penting. Inti dari Transformer adalah mekanisme perhatian, yang bertindak seperti filter informasi dan memungkinkan model untuk fokus pada bagian terpenting kalimat. Tetapi bahkan Transformer yang kuat pun akan terganggu oleh informasi yang tidak relevan, sama seperti Anda mencoba mencari buku di perpustakaan, tetapi Anda kewalahan oleh tumpukan buku yang tidak relevan, dan efisiensinya tentu saja rendah.
Informasi tidak relevan yang dihasilkan oleh mekanisme perhatian ini disebut gangguan perhatian di makalah. Bayangkan Anda ingin mencari informasi penting dalam sebuah file, tetapi perhatian model Transformer tersebar ke berbagai tempat yang tidak relevan, seperti orang yang berpikiran sempit yang tidak dapat melihat poin-poin penting.
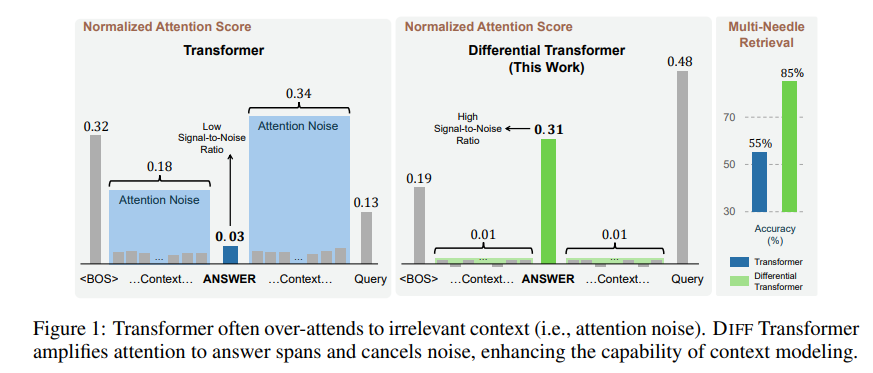
Untuk mengatasi masalah tersebut, makalah ini mengusulkan Transformator Diferensial (DIFF Transformer). Namanya sangat canggih, namun prinsipnya sebenarnya sangat sederhana, seperti halnya headphone peredam bising, kebisingan dihilangkan melalui perbedaan antara dua sinyal.
Inti dari Transformator Diferensial adalah mekanisme perhatian diferensial. Ini membagi kueri dan vektor kunci menjadi dua kelompok, menghitung masing-masing dua peta perhatian, dan kemudian mengurangi kedua peta ini untuk mendapatkan skor perhatian akhir. Proses ini seperti memotret objek yang sama dengan dua kamera, lalu melapiskan kedua foto tersebut, dan perbedaannya akan ditonjolkan.
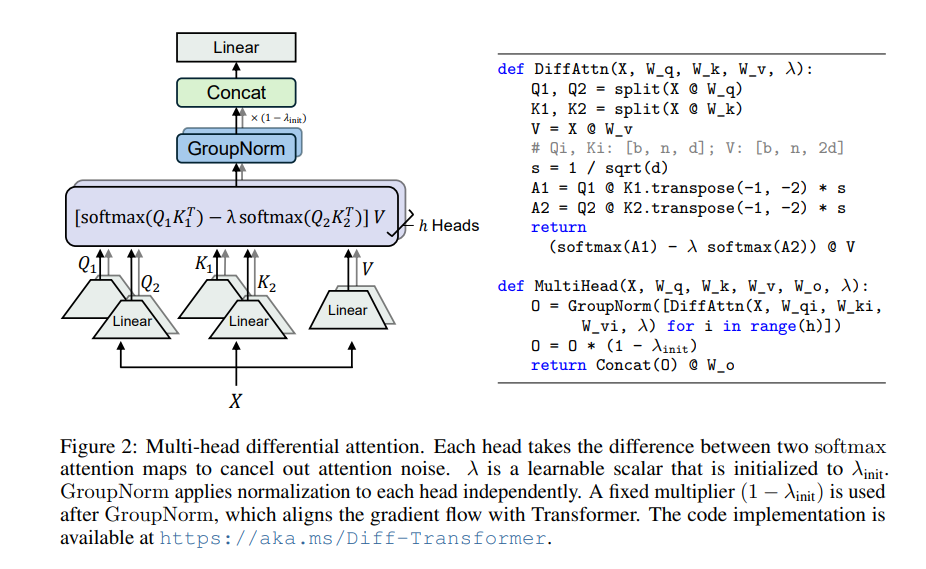
Dengan cara ini, Transformator Diferensial dapat secara efektif menghilangkan gangguan perhatian dan memungkinkan model lebih fokus pada informasi penting. Sama seperti saat Anda memakai headphone peredam bising, kebisingan di sekitar akan hilang dan Anda dapat mendengar suara yang Anda inginkan dengan lebih jelas.
Serangkaian percobaan dilakukan di makalah untuk membuktikan keunggulan Transformator Diferensial. Pertama, performanya baik dalam pemodelan bahasa, hanya membutuhkan 65% ukuran model atau data pelatihan Transformer untuk mencapai hasil serupa.
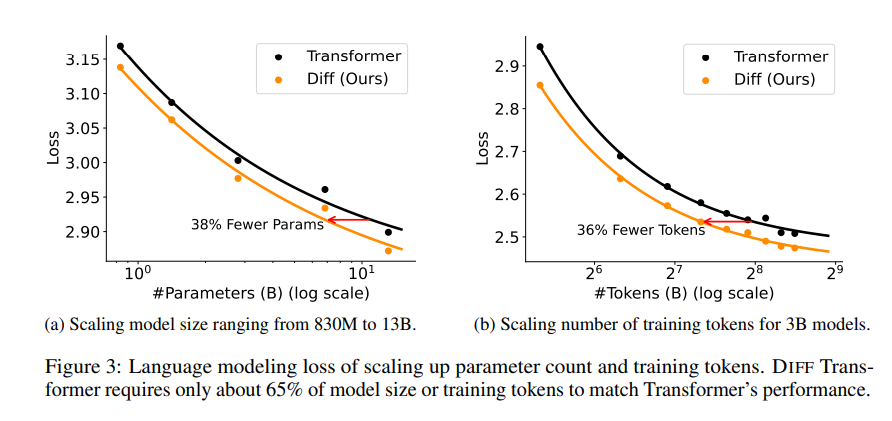
Kedua, Differential Transformer juga lebih baik dalam pemodelan teks panjang dan dapat secara efektif memanfaatkan informasi kontekstual yang lebih panjang.
Lebih penting lagi, Transformator Diferensial menunjukkan keunggulan signifikan dalam pengambilan informasi utama, pengurangan ilusi model, dan pembelajaran konteks.
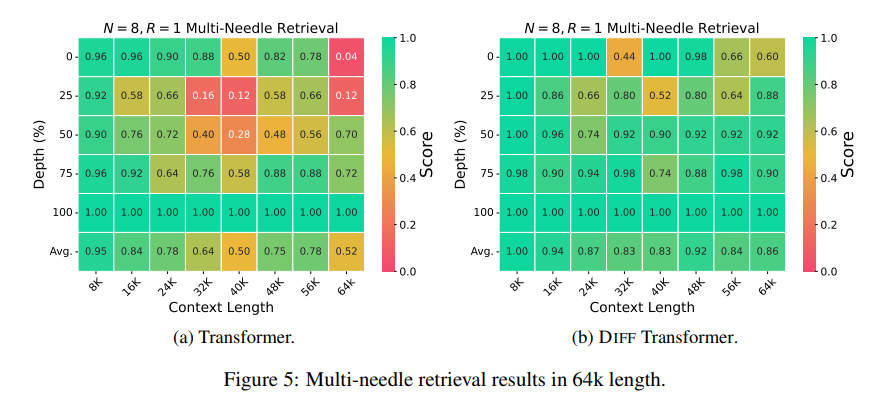
Dalam hal pengambilan informasi penting, Differential Transformer seperti mesin pencari presisi yang dapat secara akurat menemukan apa yang Anda inginkan dalam sejumlah besar informasi. Ia dapat mempertahankan akurasi tinggi bahkan dalam skenario dengan informasi yang sangat kompleks.
Dalam hal mengurangi halusinasi model, Differential Transformer dapat secara efektif menghindari "omong kosong" model dan menghasilkan ringkasan teks serta hasil tanya jawab yang lebih akurat dan andal.
Dari segi pembelajaran konteks, Transformator Diferensial lebih seperti ahli pembelajaran, mampu dengan cepat mempelajari pengetahuan baru dari sejumlah kecil sampel, dan efek pembelajaran lebih stabil, tidak seperti Transformer yang tidak mudah terpengaruh oleh urutan sampel. .
Selain itu, Transformator Diferensial juga dapat secara efektif mengurangi outlier dalam nilai aktivasi model, yang berarti lebih ramah terhadap kuantisasi model dan dapat mencapai kuantisasi bit yang lebih rendah, sehingga meningkatkan efisiensi model.
Secara keseluruhan, Transformator Diferensial secara efektif memecahkan masalah gangguan perhatian pada model Transformer melalui mekanisme perhatian diferensial dan mencapai peningkatan yang signifikan dalam berbagai aspek. Ini memberikan ide-ide baru untuk pengembangan model bahasa besar dan akan memainkan peran penting di lebih banyak bidang di masa depan.
Alamat makalah: https://arxiv.org/pdf/2410.05258
Secara keseluruhan, Transformator Diferensial menyediakan metode yang efektif untuk memecahkan masalah gangguan perhatian model Transformer. Performanya yang luar biasa di berbagai bidang menunjukkan posisi pentingnya dalam pengembangan model bahasa besar di masa depan. Editor Downcodes merekomendasikan pembaca untuk membaca makalah secara lengkap untuk mendapatkan pemahaman mendalam tentang detail teknis dan prospek penerapannya. Kami menantikan Differential Transformer membawa lebih banyak terobosan di bidang kecerdasan buatan!