Di era ledakan informasi, pemrosesan informasi teks dalam gambar secara efisien sangatlah penting. Editor Downcodes hari ini akan memperkenalkan model OCR revolusioner - GOT (General Optical Character Recognition Theory), yang menandai masuknya teknologi OCR ke era 2.0. Model GOT menggabungkan keunggulan OCR tradisional dan model bahasa besar, serta menghadirkan terobosan baru di bidang pengenalan teks dengan kinerja dan fleksibilitasnya yang kuat. Ia tidak hanya dapat mengenali dokumen dan teks adegan berbahasa Inggris dan Mandarin, tetapi juga menangani informasi kompleks seperti rumus matematika dan kimia, simbol musik, bagan, dll. Ia dapat disebut sebagai "pemain serba bisa" di bidang OCR.
Di era digital, mengubah konten teks dalam gambar menjadi teks yang dapat diedit dengan cepat adalah persyaratan umum dan penting. Kini, munculnya model pengenalan karakter optik (OCR) baru yang disebut GOT (General Optical Character Recognition Theory) menandai masuknya teknologi OCR ke era 2.0. Model inovatif ini menggabungkan keunggulan sistem OCR tradisional dan model bahasa skala besar untuk menciptakan alat pengenalan teks yang lebih efisien dan cerdas.
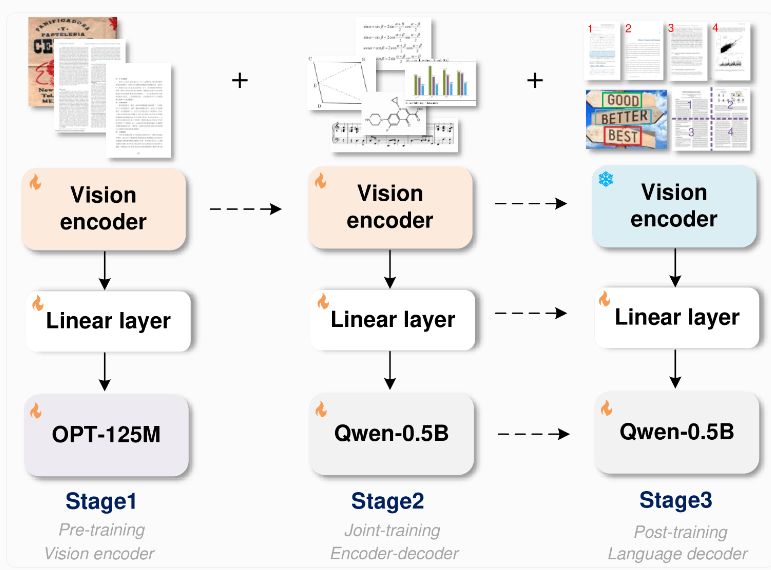
Model GOT mengadopsi arsitektur end-to-end yang inovatif. Desain ini tidak hanya menghemat sumber daya, tetapi juga memperluas kemampuan pengenalan melebihi pengenalan teks. Model ini terdiri dari encoder gambar dengan sekitar 80 juta parameter dan decoder dengan sekitar 5 juta parameter. Encoder gambar mampu mengompresi gambar hingga 1024x1024 piksel menjadi unit data, sedangkan decoder mengubah data tersebut menjadi teks hingga panjang 8000 karakter.
Kekuatan GOT terletak pada keserbagunaannya. Ia tidak hanya dapat mengenali dan mengonversi dokumen dan teks adegan berbahasa Inggris dan Mandarin, tetapi juga memproses rumus matematika dan kimia, simbol musik, figur geometris sederhana, dan berbagai bagan. Hal ini membuat GOT benar-benar serba bisa.
Untuk melatih model ini, tim peneliti pertama-tama berfokus pada tugas pengenalan teks, kemudian menggunakan Qwen-0.5B milik Alibaba sebagai decoder dan menyempurnakannya dengan berbagai data sintetis. Mereka menggunakan alat rendering profesional seperti LaTeX, Mathpix-markdown-it, dan Matplotlib untuk menghasilkan jutaan pasangan gambar-teks untuk pelatihan model.

Sorotan lain dari teknologi OCR2.0 adalah kemampuannya untuk mengekstrak teks berformat, judul, dan bahkan gambar multi-halaman dan mengubahnya menjadi format digital terstruktur. Hal ini membuka kemungkinan baru untuk pemrosesan dan analisis otomatis di berbagai bidang seperti sains, musik, dan analisis data.
Dalam pengujian berbagai tugas OCR, GOT telah menunjukkan kinerja luar biasa, mencapai hasil terdepan di industri dalam pengenalan dokumen dan teks adegan, dan bahkan melampaui banyak model profesional dan model bahasa besar dalam pengenalan grafik. Baik itu rumus struktur kimia yang kompleks, atau notasi musik dan visualisasi data, OCR2.0 dapat secara akurat menangkap dan mengubahnya menjadi format yang dapat dibaca mesin.
Untuk memungkinkan lebih banyak pengguna merasakan dan memanfaatkan teknologi ini, tim peneliti merilis demo dan kode gratis pada platform Hugging Face. Kehadiran OCR2.0 tidak diragukan lagi membawa revolusi di bidang pemrosesan informasi. Hal ini tidak hanya meningkatkan efisiensi, namun juga meningkatkan fleksibilitas, memungkinkan kita memproses informasi teks dalam gambar dengan lebih mudah.
Kemunculan model GOT tidak diragukan lagi telah memberikan vitalitas baru ke dalam teknologi OCR. Fitur-fiturnya yang efisien, akurat, dan serbaguna akan digunakan secara luas di semua lapisan masyarakat, sehingga memberikan lebih banyak kemudahan dalam pekerjaan dan kehidupan masyarakat. Kami berharap dapat lebih meningkatkan model GOT di masa depan dan memberikan lebih banyak kejutan!