Apple telah merilis peningkatan besar pada model kecerdasan buatan multimodal MM1 - MM1.5. Peningkatan ini bukan merupakan perulangan versi sederhana, namun merupakan peningkatan menyeluruh pada kemampuan model, yang secara signifikan meningkatkan kinerjanya dalam pemahaman gambar, pengenalan teks, dan eksekusi perintah visual. Editor Downcodes akan menjelaskan secara rinci peningkatan MM1.5 dan signifikansinya dalam bidang kecerdasan buatan multi-modal.
Apple baru-baru ini meluncurkan pembaruan besar pada model kecerdasan buatan multi-modal MM1, meningkatkannya ke versi MM1.5. Peningkatan ini bukan sekadar perubahan nomor versi sederhana, namun peningkatan kemampuan menyeluruh, sehingga model dapat menunjukkan performa yang lebih bertenaga di berbagai bidang.
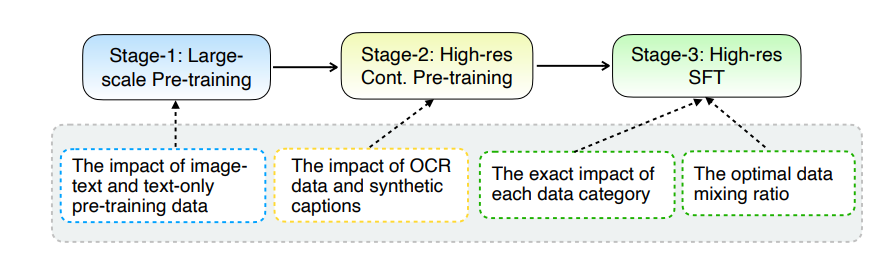
Peningkatan inti MM1.5 terletak pada metode pemrosesan data yang inovatif. Model ini mengadopsi pendekatan pelatihan yang berpusat pada data, dan kumpulan data pelatihan disaring dan dioptimalkan secara cermat. Secara khusus, MM1.5 menggunakan data OCR definisi tinggi dan deskripsi gambar sintetis, serta instruksi visual yang dioptimalkan untuk menyempurnakan campuran data. Pengenalan data ini telah meningkatkan performa model secara signifikan dalam pengenalan teks, pemahaman gambar, dan pelaksanaan instruksi visual.

Dalam hal ukuran model, MM1.5 mencakup beberapa versi mulai dari 1 miliar hingga 30 miliar parameter, termasuk varian intensif dan campuran ahli (MoE). Perlu dicatat bahwa model parameter skala 1 miliar dan 3 miliar yang lebih kecil pun dapat mencapai tingkat kinerja yang mengesankan dengan data dan strategi pelatihan yang dirancang dengan cermat.
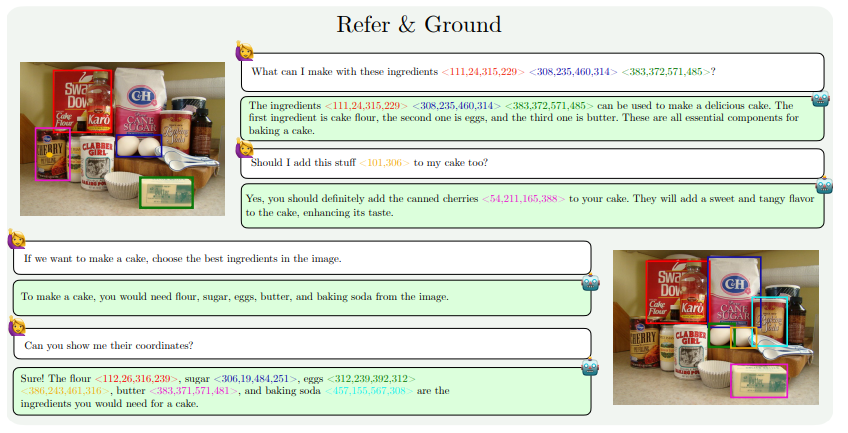
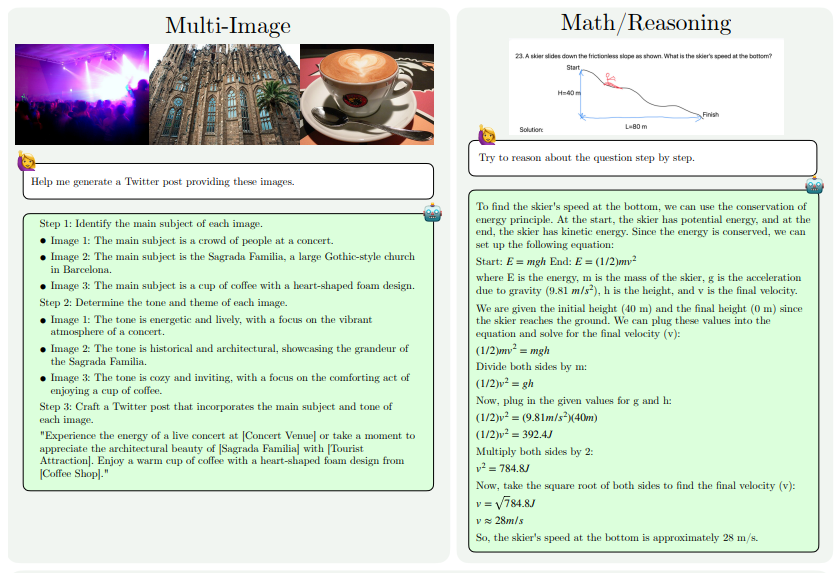
Peningkatan kemampuan MM1.5 terutama tercermin dalam aspek berikut: pemahaman gambar intensif teks, referensi visual dan pemosisian, penalaran multi-gambar, pemahaman video, dan pemahaman UI seluler. Kemampuan ini memungkinkan MM1.5 untuk diterapkan pada skenario yang lebih luas, seperti mengidentifikasi pemain dan instrumen dari foto konser, memahami data grafik dan menjawab pertanyaan terkait, menemukan lokasi objek tertentu dalam pemandangan yang kompleks, dll.
Untuk mengevaluasi kinerja MM1.5, para peneliti membandingkannya dengan model multimodal canggih lainnya. Hasilnya menunjukkan bahwa MM1.5-1B berkinerja baik pada model dengan skala 1 miliar parameter, jauh lebih baik dibandingkan model lain pada level yang sama. MM1.5-3B mengungguli MiniCPM-V2.0 dan setara dengan InternVL2 dan Phi-3-Vision. Selain itu, penelitian ini juga menemukan bahwa apakah itu model padat atau model MoE, kinerjanya akan meningkat secara signifikan seiring dengan peningkatan skala.
Keberhasilan MM1.5 tidak hanya mencerminkan kekuatan penelitian dan pengembangan Apple di bidang kecerdasan buatan, namun juga menunjukkan jalan bagi pengembangan model multimodal di masa depan. Dengan mengoptimalkan metode pemrosesan data dan arsitektur model, model berskala lebih kecil pun dapat mencapai performa yang kuat, yang sangat penting dalam penerapan model AI berperforma tinggi pada perangkat dengan sumber daya terbatas.
Alamat makalah: https://arxiv.org/pdf/2409.20566
Secara keseluruhan, peluncuran MM1.5 menandai kemajuan signifikan dalam teknologi kecerdasan buatan multimodal. Inovasinya dalam pemrosesan data dan arsitektur model memberikan ide dan arahan baru untuk pengembangan model AI di masa depan. Kami berharap Apple terus menghadirkan lebih banyak hasil terobosan di bidang kecerdasan buatan.