Editor Downcodes mengetahui bahwa studi terobosan di Universitas Yale mengungkap rahasia pelatihan model AI: kompleksitas data tidak semakin tinggi, semakin baik, tetapi terdapat kondisi "tepi kekacauan" yang optimal. Tim peneliti dengan cerdik menggunakan model otomat seluler untuk melakukan eksperimen, mengeksplorasi dampak data dengan kompleksitas berbeda terhadap efek pembelajaran model AI, dan sampai pada kesimpulan yang menarik.
Tim peneliti Universitas Yale baru-baru ini merilis hasil penelitian yang inovatif, mengungkapkan temuan utama dalam pelatihan model AI: data dengan efek pembelajaran AI terbaik tidaklah lebih sederhana atau lebih kompleks, namun terdapat tingkat kompleksitas yang optimal - —sebuah keadaan yang dikenal sebagai ujung kekacauan.
Tim peneliti melakukan eksperimen dengan menggunakan Element Cellular Automata (ECA), yang merupakan sistem sederhana di mana keadaan masa depan setiap unit hanya bergantung pada dirinya sendiri dan keadaan dua unit yang berdekatan. Meskipun aturannya sederhana, sistem seperti itu dapat menghasilkan pola yang beragam mulai dari yang sederhana hingga yang sangat kompleks. Para peneliti kemudian mengevaluasi kinerja model bahasa ini pada tugas penalaran dan prediksi gerakan catur.
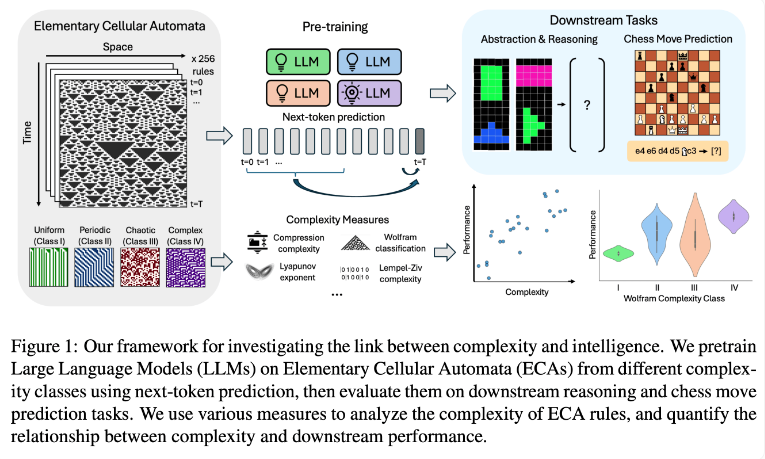
Hasil penelitian menunjukkan bahwa model AI yang dilatih dengan aturan ECA yang lebih kompleks memiliki performa lebih baik dalam tugas berikutnya. Secara khusus, model yang dilatih pada ECA Kelas IV dalam Klasifikasi Wolfram menunjukkan performa terbaik. Pola-pola yang dihasilkan oleh aturan-aturan tersebut tidak sepenuhnya teratur dan tidak sepenuhnya kacau, melainkan menunjukkan kompleksitas yang terstruktur.
Para peneliti menemukan bahwa ketika model dihadapkan pada pola yang terlalu sederhana, mereka sering kali hanya mempelajari solusi sederhana. Sebaliknya, model yang dilatih pada pola yang lebih kompleks akan mengembangkan kemampuan pemrosesan yang lebih canggih bahkan ketika solusi sederhana tersedia. Tim peneliti berspekulasi bahwa kompleksitas representasi yang dipelajari ini merupakan faktor kunci dalam kemampuan model untuk mentransfer pengetahuan ke tugas lain.
Temuan ini mungkin menjelaskan mengapa model bahasa besar seperti GPT-3 dan GPT-4 sangat efisien. Para peneliti percaya bahwa data yang sangat besar dan beragam yang digunakan dalam pelatihan model ini mungkin telah menciptakan efek yang mirip dengan pola ECA yang kompleks dalam penelitian mereka.
Penelitian ini memberikan ide-ide baru untuk pelatihan model AI dan perspektif baru untuk memahami kemampuan hebat model bahasa besar. Di masa depan, mungkin kita dapat lebih meningkatkan performa dan kemampuan generalisasi model AI dengan mengontrol kompleksitas data pelatihan secara lebih tepat. Redaksi Downcodes meyakini hasil penelitian ini akan memberikan dampak besar pada bidang kecerdasan buatan.