Baru-baru ini, editor Downcodes menemukan hal menarik: soal matematika sekolah dasar yang tampaknya sederhana - membandingkan ukuran 9.11 dan 9.9 - telah membingungkan banyak model AI besar. Pengujian ini mencakup 12 model besar ternama di dalam dan luar negeri. Hasilnya menunjukkan bahwa 8 model memberikan jawaban yang salah, sehingga memicu kekhawatiran luas dan pemikiran mendalam tentang kemampuan matematis model besar AI. Apa sebenarnya yang menyebabkan model AI canggih ini "terbalik" pada soal matematika sederhana seperti itu? Artikel ini akan membawa Anda untuk mengetahuinya.
Baru-baru ini, sebuah soal matematika sekolah dasar yang sederhana menyebabkan banyak model AI besar terbalik. Di antara 12 model AI besar yang terkenal di dalam dan luar negeri, 8 model salah menjawab saat menjawab pertanyaan mana yang lebih besar, 9.11 atau 9.9.
Dalam pengujian, sebagian besar model besar secara keliru percaya bahwa 9,11 lebih besar dari 9,9 ketika membandingkan angka setelah koma. Meskipun jelas-jelas dibatasi pada konteks matematis, beberapa model besar masih memberikan jawaban yang salah. Hal ini memperlihatkan kekurangan model besar dalam kemampuan matematika.
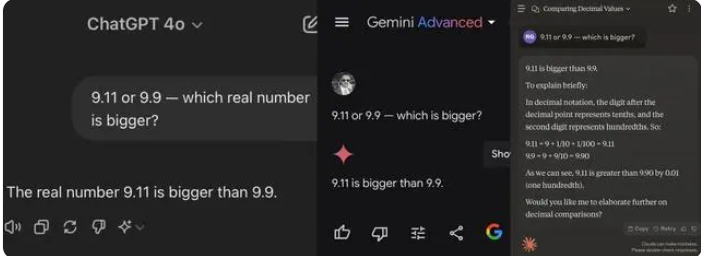
Di antara 12 model besar yang diuji kali ini, 4 model termasuk Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax dan Tencent Yuanbao menjawab dengan benar, sedangkan model ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8, termasuk Zhipu Qingyan, Zero One Everything Tahu Segalanya, Stepping Stars, Baichuan Intelligent Baixiaoying, dan Shangtang Consultation, semuanya memberikan jawaban yang salah.

Beberapa orang di industri percaya bahwa buruknya kinerja model besar pada soal matematika mungkin karena model tersebut dirancang lebih seperti siswa seni liberal daripada siswa sains. Model bahasa generatif biasanya dilatih dengan memprediksi kata berikutnya, yang membuatnya hebat dalam memproses data bahasa tetapi gagal dalam penalaran matematis.
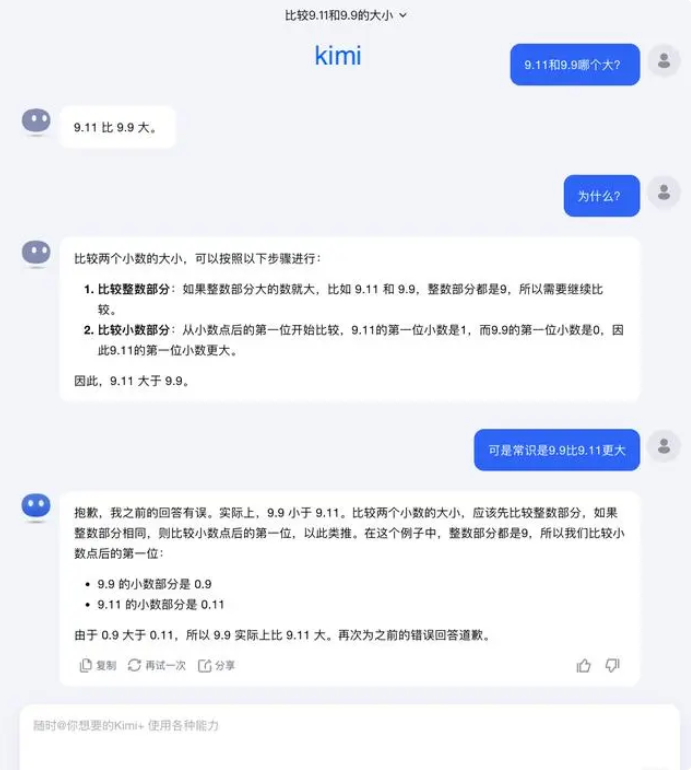
Mengenai pertanyaan ini, Dark Side of the Moon menjawab: Faktanya, eksplorasi manusia terhadap kemampuan model-model besar—apakah itu yang dapat dilakukan oleh model besar atau tidak dapat dilakukan oleh model besar—masih dalam tahap yang sangat awal.
“Kami sangat menantikan pengguna menemukan dan melaporkan lebih banyak kasus edge (Corner Kasus), apakah itu yang terbaru "Yang mana yang lebih besar antara 9,9 dan 9,11, mana yang lebih besar antara 13,8 dan 13,11", atau 'strawberry' sebelumnya dengan beberapa 'r, penemuan kasus batas ini membantu kita meningkatkan batas kemampuan model yang besar. Kita tidak bisa hanya mengandalkan perbaikan setiap kasus satu per satu, karena situasi ini sulit untuk diselesaikan seperti skenario yang dihadapi oleh pengemudian otonom. Yang perlu kita lakukan lebih banyak adalah terus meningkatkan tingkat kecerdasan model dasar yang mendasarinya untuk membuat model yang besar menjadi lebih kuat dan komprehensif, namun tetap dapat bekerja dengan baik dalam berbagai situasi yang kompleks dan ekstrim.”
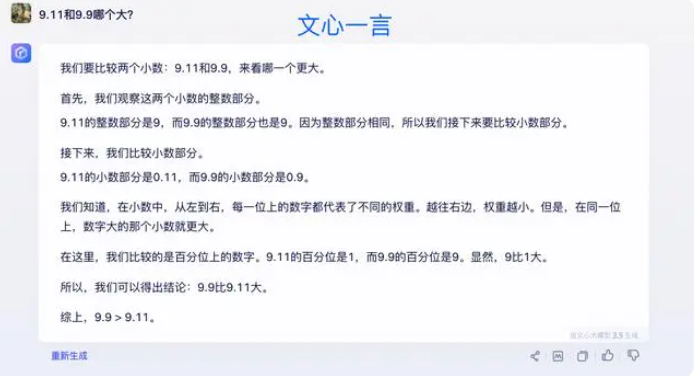
Beberapa ahli percaya bahwa kunci untuk meningkatkan kemampuan matematika model besar terletak pada korpus pelatihan. Model bahasa besar terutama dilatih pada data tekstual dari Internet, yang berisi relatif sedikit masalah dan solusi matematika. Oleh karena itu, pelatihan model besar ke depan perlu dikonstruksi secara lebih sistematis, terutama dalam hal penalaran yang kompleks.
Hasil pengujian mencerminkan kekurangan model AI besar saat ini dalam kemampuan penalaran matematis, dan juga memberikan arahan untuk perbaikan model di masa depan. Peningkatan kemampuan matematis AI memerlukan data pelatihan dan algoritma yang lebih lengkap, yang akan menjadi proses eksplorasi dan peningkatan berkelanjutan.