Kecerdasan buatan telah mencapai kemajuan yang signifikan dalam pengenalan gambar dalam beberapa tahun terakhir, namun pemahaman video masih merupakan tantangan besar. Dinamika dan kompleksitas data video menghadirkan kesulitan yang belum pernah terjadi sebelumnya pada AI. Namun, encoder video VideoPrism yang dikembangkan oleh tim peneliti Google diharapkan dapat mengubah situasi ini. Editor Downcodes akan memberi Anda pemahaman mendalam tentang fungsi-fungsi VideoPrism yang hebat, metode pelatihan, dan dampaknya yang besar terhadap bidang pemahaman video AI di masa depan.
Di dunia AI, mesin memahami video jauh lebih sulit daripada memahami gambar. Videonya dinamis, dengan suara, gerakan, dan banyak adegan kompleks. Dulu, dengan AI, menonton video seperti membaca buku dari surga, dan Anda sering kali bingung.
Namun kemunculan VideoPrism mungkin mengubah segalanya. Ini adalah encoder video yang dikembangkan oleh tim peneliti Google. Encoder ini dapat mencapai tingkat tercanggih dengan satu model pada berbagai tugas pemahaman video. Baik itu mengklasifikasikan video, memposisikannya, membuat subtitle, atau bahkan menjawab pertanyaan tentang video, VideoPrism dapat menanganinya dengan mudah.

Bagaimana cara melatih VideoPrism?
Proses pelatihan VideoPrism seperti mengajari anak cara mengamati dunia. Pertama, Anda harus menayangkan berbagai video, mulai dari kehidupan sehari-hari hingga observasi ilmiah. Kemudian, Anda juga melatihnya dengan beberapa pasangan subtitle video "berkualitas tinggi", dan beberapa teks paralel yang berisik (seperti teks pengenalan ucapan otomatis).
Metode pra-pelatihan
Data: VideoPrism menggunakan 36 juta pasangan subtitle video berkualitas tinggi dan 58,2 juta klip video dengan teks paralel yang berisik.
Arsitektur model: Berdasarkan trafo visual standar (ViT), menggunakan desain terfaktor dalam ruang dan waktu.
Algoritme pelatihan: mencakup dua tahap: pelatihan perbandingan video-teks dan pemodelan video bertopeng.
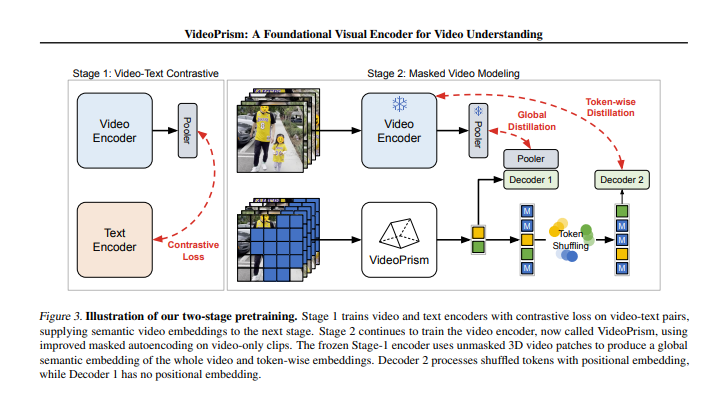
Selama proses pelatihan, VideoPrism akan melalui dua tahap. Pada tahap pertama, mempelajari hubungan antara video dan teks melalui pembelajaran kontrastif dan distilasi global-lokal. Pada tahap kedua, lebih meningkatkan pemahaman konten video melalui pemodelan video bertopeng.
Para peneliti menguji VideoPrism pada beberapa tugas pemahaman video, dan hasilnya sangat mengesankan. VideoPrism mencapai kinerja tercanggih pada 30 dari 33 tolok ukur. Baik itu menjawab pertanyaan video online atau tugas computer vision di bidang ilmiah, VideoPrism telah menunjukkan kemampuan yang kuat.
Kelahiran VideoPrism telah membawa kemungkinan baru dalam bidang pemahaman video AI. Tidak hanya dapat membantu AI lebih memahami konten video, hal ini juga dapat memainkan peran penting dalam bidang pendidikan, hiburan, keamanan, dan bidang lainnya.
Namun VideoPrism juga menghadapi beberapa tantangan, seperti cara menangani video panjang dan cara menghindari bias selama proses pelatihan. Ini adalah masalah yang perlu diatasi dalam penelitian masa depan.
Alamat makalah: https://arxiv.org/pdf/2402.13217
Secara keseluruhan, kemunculan VideoPrism menandai kemajuan besar di bidang pemahaman video AI. Performanya yang kuat dan prospek penerapannya yang luas sangat menarik. Di masa depan, dengan perkembangan teknologi yang berkelanjutan, saya yakin VideoPrism akan menunjukkan nilainya di lebih banyak bidang dan memberikan lebih banyak kemudahan dalam kehidupan masyarakat.