Pelatihan kecerdasan buatan memakan waktu dan menghabiskan daya komputasi, yang selalu menjadi hambatan di bidang AI. Tim DeepMind baru-baru ini merilis studi terobosan dan mengusulkan metode penyaringan data baru yang disebut JEST, yang secara efektif memecahkan masalah ini. Editor Downcodes akan memberi Anda pemahaman mendalam tentang bagaimana JEST dapat meningkatkan efisiensi pelatihan AI dan menjelaskan prinsip teknis di baliknya.
Di bidang kecerdasan buatan, daya komputasi dan waktu selalu menjadi faktor utama yang menghambat kemajuan teknologi. Namun hasil penelitian terbaru tim DeepMind memberikan solusi atas masalah tersebut.
Mereka mengusulkan metode penyaringan data baru yang disebut JEST, yang mencapai pengurangan signifikan dalam waktu pelatihan AI dan kebutuhan daya komputasi dengan secara cerdas menyaring kumpulan data terbaik untuk pelatihan. Dikatakan dapat mengurangi waktu pelatihan AI sebanyak 13 kali lipat dan mengurangi kebutuhan daya komputasi hingga 90%.
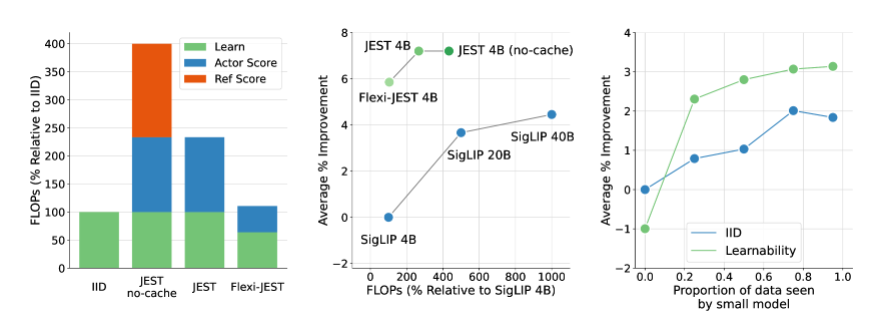
Inti dari metode JEST terletak pada pemilihan kumpulan data terbaik secara bersama-sama, bukan sampel individual, sebuah strategi yang telah terbukti sangat efektif dalam mempercepat pembelajaran multi-modal. Dibandingkan dengan metode penyaringan data pra-pelatihan tradisional berskala besar, JEST tidak hanya secara signifikan mengurangi jumlah iterasi dan operasi floating-point, namun juga melampaui metode canggih sebelumnya dengan hanya menggunakan 10% dari anggaran FLOP.
Penelitian tim DeepMind mengungkapkan tiga hal penting: memilih kumpulan data yang baik lebih efektif daripada memilih titik data satu per satu, perkiraan model online dapat digunakan untuk memfilter data dengan lebih efisien, dan kumpulan data kecil berkualitas tinggi dapat di-bootstrap untuk memanfaatkan kumpulan data yang lebih besar. . Temuan ini memberikan landasan teoritis untuk kinerja metode JEST yang efisien.
Prinsip kerja JEST adalah mengevaluasi kemampuan belajar titik data dengan memanfaatkan penelitian sebelumnya tentang kerugian RHO dan menggabungkan kerugian model pembelajaran dan model referensi yang telah dilatih sebelumnya. Ini memilih titik data yang lebih mudah untuk model yang telah dilatih sebelumnya tetapi lebih sulit untuk model pembelajaran saat ini guna meningkatkan efisiensi dan efektivitas pelatihan.
Selain itu, JEST juga mengadopsi metode berulang berdasarkan pemblokiran pengambilan sampel Gibbs untuk membangun batch secara bertahap, dan memilih subset sampel baru berdasarkan skor kemampuan belajar bersyarat di setiap iterasi. Pendekatan ini terus ditingkatkan seiring dengan semakin banyaknya data yang disaring, termasuk hanya menggunakan model referensi terlatih untuk menilai data.
Penelitian DeepMind ini tidak hanya membawa kemajuan terobosan di bidang pelatihan AI, tetapi juga memberikan ide dan metode baru untuk pengembangan teknologi AI di masa depan. Dengan optimalisasi lebih lanjut dan penerapan metode JEST, kami memiliki alasan untuk percaya bahwa pengembangan kecerdasan buatan akan membawa prospek yang lebih luas.
Makalah: https://arxiv.org/abs/2406.17711
Menyorot:
**Revolusi efisiensi pelatihan**: Metode JEST DeepMind mengurangi waktu pelatihan AI hingga 13 kali lipat dan mengurangi kebutuhan daya komputasi hingga 90%.
**Penyaringan kumpulan data**: JEST secara signifikan meningkatkan efisiensi pembelajaran multi-modal dengan bersama-sama memilih kumpulan data terbaik, bukan sampel individual.
?️ **Metode pelatihan inovatif**: JEST menggunakan perkiraan model online dan panduan kumpulan data berkualitas tinggi untuk mengoptimalkan distribusi data dan kemampuan generalisasi model pra-pelatihan skala besar.
Munculnya metode JEST membawa harapan baru bagi pelatihan AI, dan strategi penyaringan data yang efisien diharapkan dapat mendorong penerapan dan pengembangan teknologi AI di berbagai bidang. Di masa depan, kami berharap dapat melihat kinerja JEST dalam aplikasi yang lebih praktis dan lebih lanjut mendorong terobosan di bidang kecerdasan buatan. Editor Downcodes akan terus memperhatikan perkembangan yang relevan dan memberikan laporan yang lebih menarik kepada pembaca.