Editor Downcodes mengetahui bahwa Groq baru-baru ini merilis mesin LLM yang luar biasa, yang kecepatan pemrosesannya jauh melebihi ekspektasi industri, memberikan pengalaman interaktif model bahasa berskala besar yang belum pernah terjadi sebelumnya kepada pengembang. Mesin ini didasarkan pada LLama3-8b-8192LLM open source Meta dan mendukung model lain. Kecepatan pemrosesannya mencapai 1256,54 tanda per detik, jauh di depan chip GPU dari perusahaan seperti Nvidia. Perkembangan terobosan ini tidak hanya menarik perhatian luas dari para pengembang, namun juga menghadirkan pengalaman aplikasi LLM yang lebih cepat dan fleksibel bagi pengguna biasa.
Groq baru-baru ini meluncurkan mesin LLM secepat kilat di situs webnya, memungkinkan pengembang untuk secara langsung melakukan kueri cepat dan pelaksanaan tugas pada model bahasa besar.
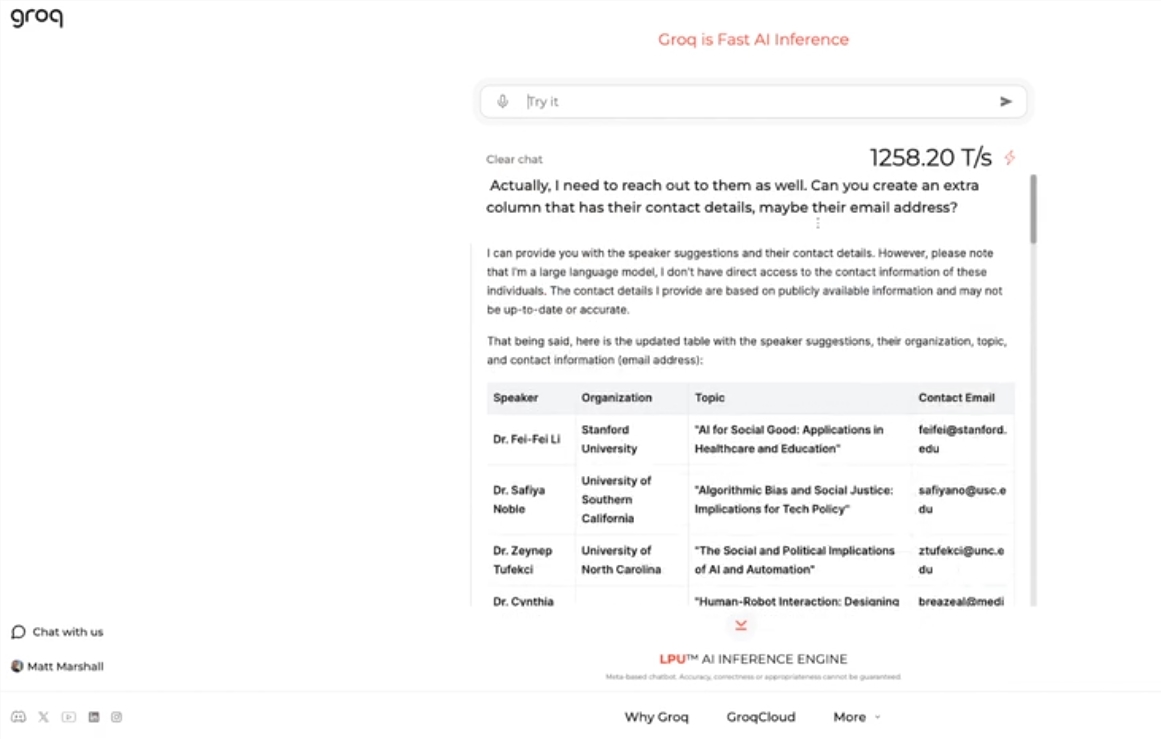
Mesin ini menggunakan sumber terbuka Meta LLama3-8b-8192LLM, mendukung model lain secara default, dan luar biasa cepat. Berdasarkan hasil pengujian, mesin Groq mampu menangani 1256,54 tanda per detik, jauh melebihi chip GPU dari perusahaan seperti Nvidia. Langkah ini menarik perhatian luas baik dari pengembang maupun non-pengembang, yang menunjukkan kecepatan dan fleksibilitas chatbot LLM.
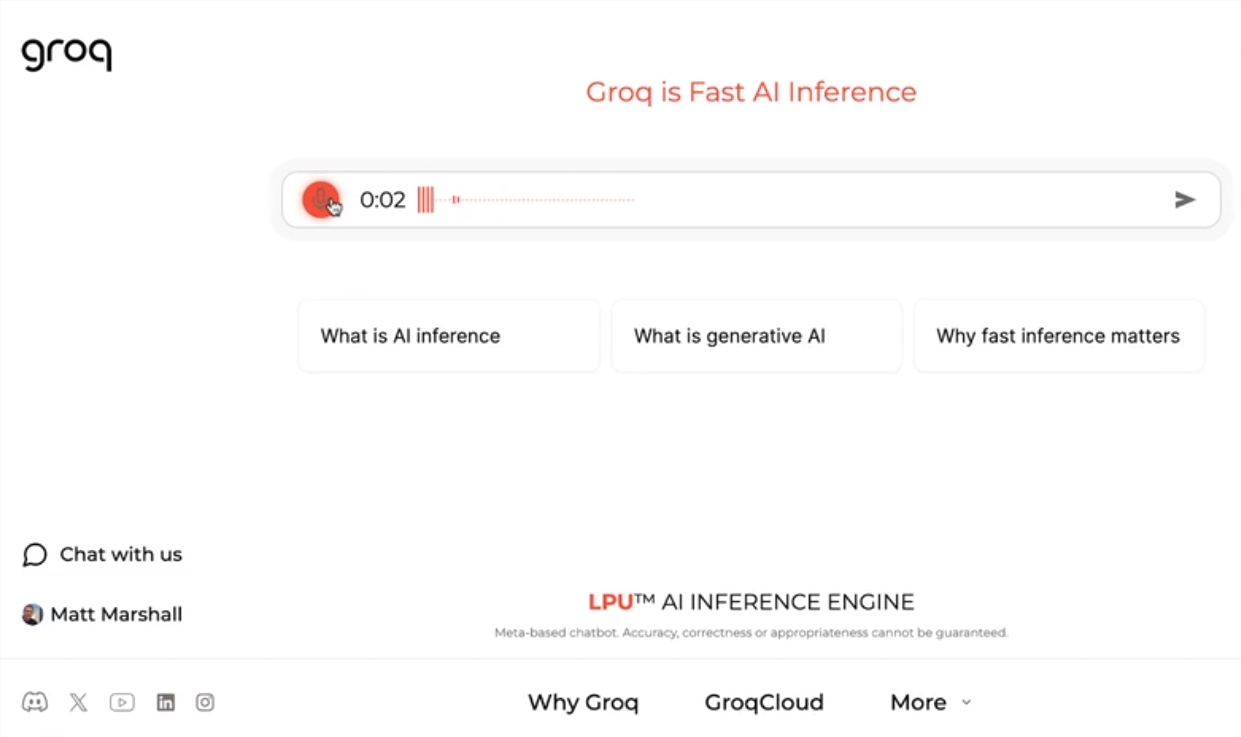
CEO Groq Jonathan Ross mengatakan penggunaan LLM akan semakin meningkat seiring orang-orang mengetahui betapa mudahnya menggunakannya pada mesin cepat Groq. Melalui demonstrasi tersebut, masyarakat dapat melihat bahwa berbagai tugas dapat diselesaikan dengan mudah dengan kecepatan ini, seperti membuat iklan lowongan kerja, memodifikasi konten artikel, dll. Mesin Groq bahkan dapat melakukan kueri berdasarkan perintah suara, menunjukkan kekuatan dan kemudahan penggunaan.
Selain menawarkan layanan beban kerja LLM gratis, Groq juga menyediakan konsol bagi pengembang yang memungkinkan mereka dengan mudah mengalihkan aplikasi yang dibangun di OpenAI ke Groq.
Metode peralihan sederhana ini telah menarik banyak pengembang, dan saat ini lebih dari 280.000 orang telah menggunakan layanan Groq. CEO Ross mengatakan bahwa pada tahun depan, lebih dari separuh perhitungan inferensi dunia akan dijalankan pada chip Groq, yang menunjukkan potensi dan prospek perusahaan di bidang AI.
Menyorot:
Groq meluncurkan mesin LLM secepat kilat, memproses 1256,54 tanda per detik, jauh lebih cepat daripada kecepatan GPU
Mesin Groq menunjukkan kecepatan dan fleksibilitas chatbot LLM, menarik perhatian pengembang dan non-pengembang
? Groq menyediakan layanan beban kerja LLM gratis yang telah digunakan oleh lebih dari 280.000 pengembang. Diharapkan setengah dari perhitungan inferensi dunia akan berjalan pada chipnya tahun depan
Mesin LLM cepat Groq tidak diragukan lagi membawa kemungkinan-kemungkinan baru di bidang AI, dan kinerjanya yang tinggi serta kemudahan penggunaannya akan mendorong penerapan teknologi LLM yang lebih luas. Editor Downcodes percaya bahwa perkembangan Groq di masa depan patut dinantikan!