Dalam beberapa tahun terakhir, pesatnya perkembangan teknologi kecerdasan buatan sangat bergantung pada pelatihan data yang sangat besar. Namun, editor Downcodes menemukan bahwa penelitian terbaru dari MIT dan institusi lain menunjukkan bahwa kesulitan memperoleh data meningkat secara dramatis. Data jaringan yang dulunya tersedia dengan mudah kini tunduk pada pembatasan yang semakin ketat, yang menimbulkan tantangan besar bagi pelatihan dan pengembangan AI. Studi tersebut, yang menganalisis berbagai kumpulan data open source, mengungkap kenyataan nyata ini.
Di balik pesatnya perkembangan kecerdasan buatan, muncul masalah serius—kesulitan perolehan data semakin meningkat. Penelitian terbaru dari MIT dan institusi lain menemukan bahwa data web yang tadinya mudah diakses kini menjadi semakin sulit diakses, sehingga menimbulkan tantangan besar bagi pelatihan dan penelitian AI.
Para peneliti menemukan bahwa situs web yang dirayapi oleh beberapa kumpulan data sumber terbuka seperti C4, RefineWeb, Dolma, dll. dengan cepat memperketat perjanjian lisensi mereka. Hal ini tidak hanya berdampak pada pelatihan model AI komersial, namun juga menghambat penelitian yang dilakukan oleh organisasi akademis dan nirlaba.

Penelitian ini dilakukan oleh empat pemimpin tim dari MIT Media Lab, Wellesley College, startup AI Raive dan institusi lainnya. Mereka mencatat bahwa pembatasan data semakin meluas dan asimetri serta inkonsistensi perizinan menjadi semakin nyata.
Tim peneliti menggunakan Robots Exclusion Protocol (REP) dan Terms of Service (ToS) situs web sebagai metode penelitian. Mereka menemukan bahwa bahkan crawler dari perusahaan AI besar seperti OpenAI menghadapi pembatasan yang semakin ketat.
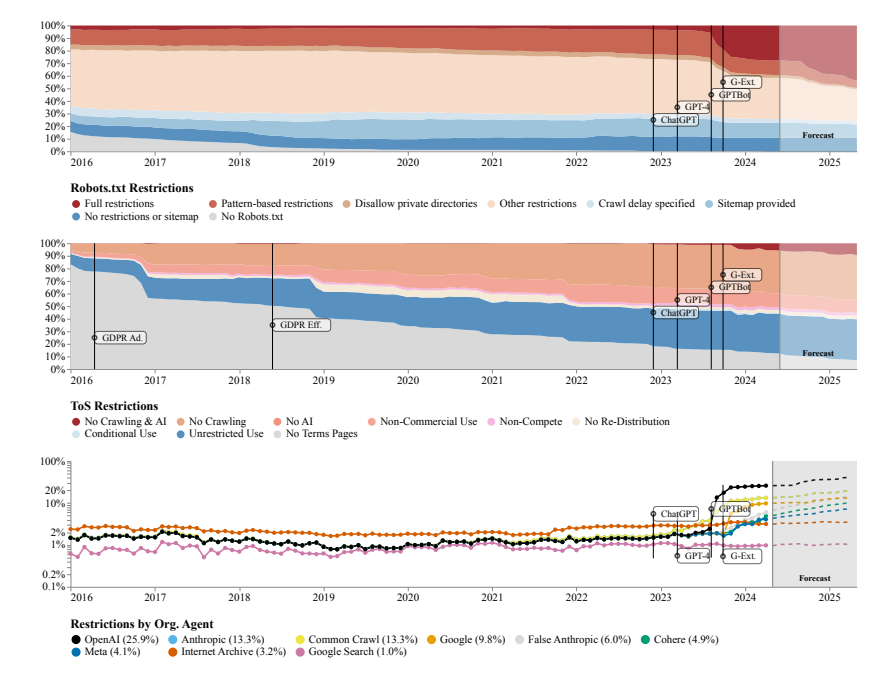
Model SARIMA memperkirakan bahwa di masa depan, baik melalui robots.txt maupun ToS, pembatasan data situs web akan terus meningkat. Hal ini menunjukkan bahwa akses terhadap data jaringan terbuka akan menjadi lebih sulit.
Studi ini juga menemukan bahwa data yang dirayapi dari Internet tidak sesuai dengan tujuan pelatihan model AI, yang mungkin berdampak pada penyelarasan model, praktik pengumpulan data, dan hak cipta.
Tim peneliti menyerukan perlunya perjanjian yang lebih fleksibel yang mencerminkan keinginan pemilik situs web, memisahkan kasus penggunaan yang diizinkan dan tidak diizinkan, dan menyinkronkan dengan persyaratan layanan. Pada saat yang sama, mereka ingin pengembang AI dapat menggunakan data di web terbuka untuk pelatihan, dan berharap undang-undang di masa depan akan mendukung hal ini.
Alamat makalah: https://www.dataprovenance.org/Consent_in_Crisis.pdf
Penelitian ini telah memperingatkan masalah akuisisi data di bidang kecerdasan buatan, dan juga menimbulkan tantangan baru dalam pelatihan dan pengembangan model AI di masa depan. Bagaimana menyeimbangkan akuisisi data dan hak serta kepentingan pemilik website akan menjadi isu utama yang perlu dipertimbangkan dan diselesaikan secara serius di bidang kecerdasan buatan. Editor Downcodes merekomendasikan untuk memperhatikan makalah ini untuk mempelajari lebih detail.