Mini-Omni, model bahasa multimodal berskala besar open source, merevolusi teknologi interaksi suara. Ini mengintegrasikan teknologi canggih untuk mewujudkan input dan output suara secara real-time, dan memiliki kemampuan untuk berpikir dan berbicara pada saat yang sama, menghadirkan pengalaman interaksi manusia-komputer yang lebih alami dan lancar. Keunggulan inti Mini-Omni terletak pada kemampuan pemrosesan ucapan real-time end-to-end. Tidak diperlukan konfigurasi tambahan model ASR atau TTS untuk menikmati percakapan yang lancar. Ini mendukung berbagai masukan modal dan secara fleksibel mengubahnya untuk beradaptasi dengan berbagai skenario kompleks dan memenuhi beragam kebutuhan.
Saat ini, dengan pesatnya perkembangan kecerdasan buatan, model bahasa multi-modal berskala besar open source yang disebut Mini-Omni memimpin inovasi teknologi interaksi suara. Sistem AI yang terintegrasi dengan berbagai teknologi canggih ini tidak hanya memungkinkan masukan dan keluaran suara secara real-time, namun juga memiliki kemampuan unik untuk berpikir dan berbicara pada saat yang sama, sehingga memberikan pengalaman interaksi alami yang belum pernah ada sebelumnya kepada pengguna.
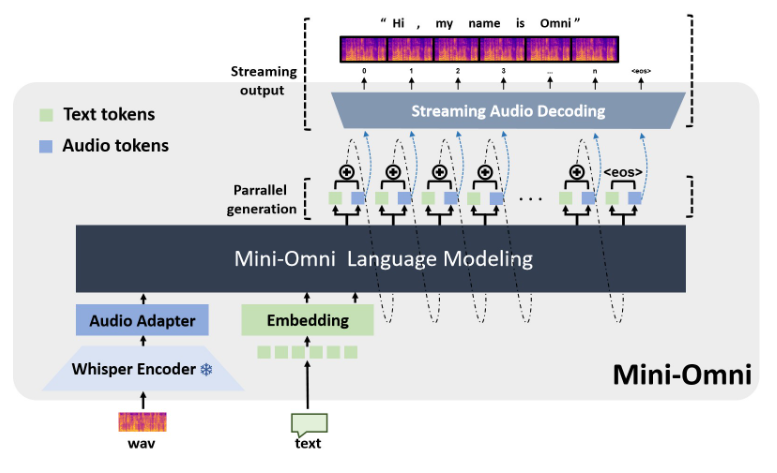
Keunggulan inti Mini-Omni terletak pada kemampuan pemrosesan suara real-time end-to-end. Pengguna dapat menikmati percakapan suara yang lancar tanpa konfigurasi tambahan model pengenalan ucapan otomatis (ASR) atau text-to-speech (TTS). Desain mulus ini sangat meningkatkan pengalaman pengguna dan membuat interaksi manusia-komputer menjadi lebih alami dan intuitif.
Selain fungsi suara, Mini-Omni juga mendukung input dalam berbagai mode seperti teks, dan secara fleksibel dapat beralih antar mode. Kemampuan pemrosesan multi-modal ini memungkinkan model untuk beradaptasi dengan berbagai skenario interaksi yang kompleks dan memenuhi beragam kebutuhan pengguna.
Yang paling layak untuk disebutkan adalah fungsi Any Model Can Talk dari Mini-Omni. Inovasi ini memungkinkan model AI lainnya dengan mudah mengintegrasikan kemampuan suara real-time Mini-Omni, sehingga sangat memperluas kemungkinan penerapan AI. Hal ini tidak hanya memberi pengembang lebih banyak pilihan, namun juga membuka jalan bagi penerapan teknologi AI lintas bidang.
Dari segi performa, Mini-Omni menunjukkan kekuatan komprehensifnya. Ini tidak hanya berfungsi dengan baik dalam tugas ucapan tradisional seperti pengenalan ucapan (ASR) dan pembuatan ucapan (TTS), namun juga menunjukkan potensi kuat dalam tugas multi-modal yang memerlukan kemampuan penalaran kompleks seperti TextQA dan SpeechQA. Kemampuan komprehensif ini memungkinkan Mini-Omni menangani berbagai skenario interaksi kompleks, mulai dari perintah suara sederhana hingga tugas tanya jawab yang memerlukan pemikiran mendalam.
Implementasi teknis Mini-Omni menggabungkan berbagai model dan teknologi AI canggih. Ia menggunakan Qwen2 sebagai dasar model bahasa besar, menggunakan litGPT untuk pelatihan dan inferensi, menggunakan bisikan untuk pengkodean audio, dan snac bertanggung jawab untuk decoding audio. Metode fusi multi-teknologi ini tidak hanya meningkatkan performa model secara keseluruhan, namun juga meningkatkan kemampuan adaptasinya dalam berbagai skenario.
Bagi pengembang dan peneliti, Mini-Omni menyediakan penggunaan yang nyaman. Dengan langkah instalasi sederhana, pengguna dapat meluncurkan Mini-Omni di lingkungan lokal mereka dan melakukan demonstrasi interaktif melalui alat seperti Streamlit dan Gradio. Fitur terbuka dan mudah digunakan ini memberikan dukungan kuat untuk mempopulerkan dan penerapan inovatif teknologi AI.
Alamat proyek: https://github.com/gpt-omni/mini-omni
Dengan fungsinya yang kuat, penggunaan yang mudah, dan fitur sumber terbuka, Mini-Omni menghadirkan kemungkinan baru di bidang interaksi suara AI dan patut mendapat perhatian dan eksplorasi dari pengembang dan peneliti. Perkembangannya di masa depan juga patut dinantikan.