Baru-baru ini, model AI open source Reflection70B telah menarik perhatian luas di industri karena kontroversi kinerjanya. Model ini dirilis oleh HyperWrite, yang awalnya mengklaimnya sebagai model open source paling kuat di dunia dan menarik banyak perhatian karena kinerjanya yang luar biasa dalam pengujian pihak ketiga. Namun, beberapa lembaga dan pengguna independen kemudian mempertanyakan kinerjanya, dan hasil pengujian berbeda secara signifikan dari klaim awal HyperWrite.
Model AI open source Reflection70B yang baru saja debut baru-baru ini banyak dipertanyakan oleh industri.
Model yang dirilis oleh startup New York HyperWrite, yang diklaim sebagai varian Meta Llama3.1, telah menarik perhatian karena kinerjanya yang sangat baik dalam pengujian pihak ketiga. Namun, ketika beberapa hasil tes dirilis, reputasi Reflection70B mulai ditantang.
Penyebab masalah ini adalah salah satu pendiri dan CEO HyperWrite Matt Shumer mengumumkan Reflection70B di media sosial X pada tanggal 6 September, dan dengan percaya diri menyebutnya sebagai "model sumber terbuka terkuat di dunia".
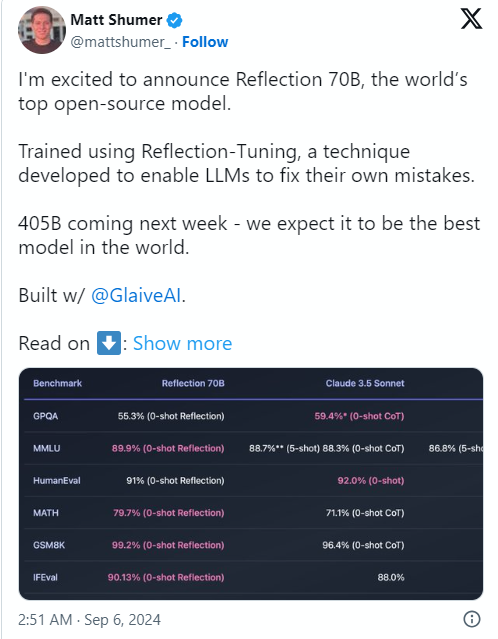
Shumer juga berbagi tentang teknologi “penyetelan reflektif” model, mengklaim bahwa metode ini memungkinkan model meninjau dirinya sendiri sebelum menghasilkan konten, sehingga meningkatkan akurasi.
Namun, sehari setelah pengumuman HyperWrite, Analisis Buatan, sebuah grup yang berspesialisasi dalam "analisis independen model AI dan penyedia hosting," menerbitkan analisisnya sendiri pada X, mencatat bahwa mereka mengevaluasi skor MMLU (Massive Multitask Language Understanding) Reflection Llama3.170B sama dengan Llama370B, tetapi jauh lebih rendah dibandingkan Llama3.170B Meta, yang merupakan perbedaan signifikan dari hasil yang awalnya diterbitkan oleh HyperWrite/Shumer.
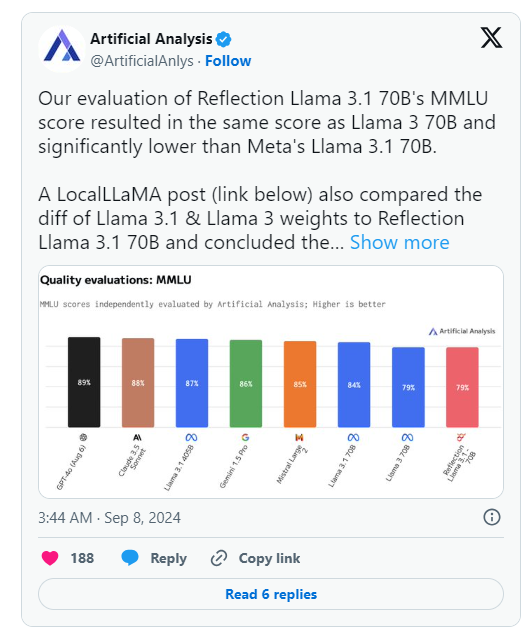
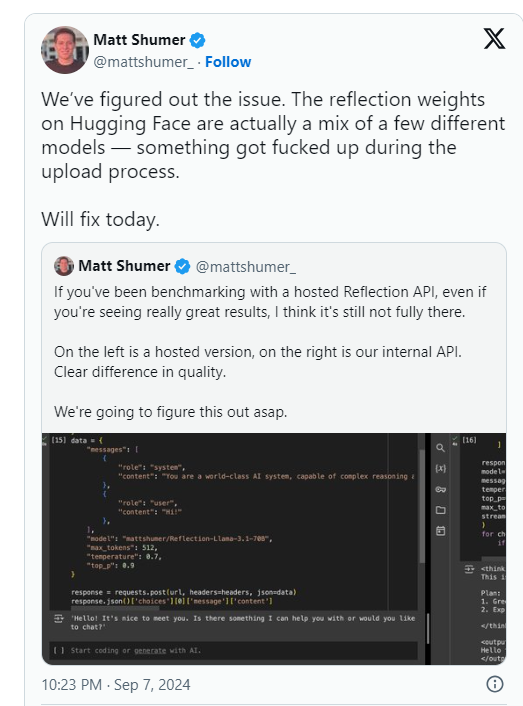
Shumer kemudian menyatakan bahwa ada masalah dengan bobot Reflection70B (atau pengaturan untuk model sumber terbuka) selama pengunggahan ke Hugging Face (repositori dan perusahaan hosting kode AI pihak ketiga), yang mungkin mengakibatkan kinerja lebih buruk daripada "API internal HyperWrite " versi. .
Analisis Buatan mengatakan dalam pernyataan berikutnya bahwa mereka memperoleh akses ke API pribadi dan melihat kinerja yang mengesankan, tetapi tidak pada tingkat yang dinyatakan semula. Karena pengujian ini dilakukan pada API pribadi, mereka tidak dapat memverifikasi secara independen apa yang mereka uji.
Kelompok ini mengangkat dua isu utama yang secara serius mempertanyakan klaim kinerja asli HyperWrite dan Shumer:
Sementara itu, pengguna di berbagai komunitas pembelajaran mesin dan AI di Reddit juga mempertanyakan kinerja dan asal usul Reflection70B. Beberapa orang menunjukkan bahwa Reflection70B tampaknya merupakan varian dari Llama3 daripada Llama-3.1 , berdasarkan perbandingan model yang diposting oleh pihak ketiga di Github, sehingga menimbulkan keraguan lebih lanjut terhadap klaim asli Shumer dan HyperWrite.
Hal ini mengakibatkan setidaknya satu pengguna X, Shin Megami Boson, memposting pada tanggal 8 September ET
Pada pukul 8:07 malam EDT, Shumer secara terbuka menuduh Shumer melakukan “perilaku curang” di komunitas riset AI dan merilis daftar panjang tangkapan layar dan bukti lainnya.
Yang lain menuduh bahwa model tersebut sebenarnya adalah "pembungkus" atau aplikasi yang dibangun di atas Claude3 milik pesaing berpemilik/sumber tertutup, Anthropic.
Namun, pengguna X lainnya membela Shumer dan Reflection70B, dengan beberapa juga membukukan kinerja mengesankan pada model mereka.
Saat ini, komunitas riset AI sedang menunggu tanggapan Shumer terhadap tuduhan penipuan tersebut dan pembaruan bobot model pada Hugging Face.
Setelah model Reflection70B dirilis, performanya dipertanyakan, dengan hasil pengujian yang gagal mereplikasi klaim awal.
⚙️ Pendiri HyperWrite menjelaskan bahwa masalah pengunggahan model menyebabkan penurunan kinerja dan meminta perhatian pada versi yang diperbarui.
Model ini telah hangat diperdebatkan di media sosial, dengan tuduhan dan pembelaan yang beragam.
Saat ini, insiden Reflection70B masih terus bergejolak, dan hasil akhirnya masih perlu menunggu penyelidikan dan tanggapan lebih lanjut. Kejadian ini juga mengingatkan kita bahwa kita harus berhati-hati dalam meningkatkan kinerja model AI apa pun dan mengandalkan hasil verifikasi independen untuk membuat penilaian.