Tim OpenDataLab basis data model besar Laboratorium Kecerdasan Buatan Shanghai (Laboratorium AI Shanghai) merilis alat ekstraksi data cerdas baru MinerU di Forum Utama WAIC Science Frontier 2024. Alat sumber terbuka ini bertujuan untuk menyederhanakan proses pemrosesan data AI dan membantu peneliti mengekstrak data berkualitas tinggi dari dokumen berukuran besar dengan lebih efisien. MinerU mendukung berbagai format dokumen, termasuk PDF, halaman web, epub, mobi dan docx, dll., dan mengubahnya menjadi format Markdown yang mudah dianalisis. Modul fungsional intinya Magic-PDF dan Magic-Doc masing-masing berfokus pada ekstraksi dokumen PDF dan halaman web/e-book, dan menggunakan model seperti LayoutLMv3, YOLOv8, UniMERNet, dan PaddleOCR untuk mencapai ekstraksi data berkualitas tinggi, sehingga meningkatkan kualitas data secara signifikan. efisiensi pemrosesan.
Pada Forum Utama WAIC Science Frontier 2024, tim OpenDataLab basis data model besar Laboratorium Kecerdasan Buatan Shanghai (Laboratorium AI Shanghai) merilis alat ekstraksi data cerdas baru yang disebut MinerU. Alat ini dirancang untuk menyederhanakan proses pemrosesan data AI dan membantu peneliti AI mengekstrak data berkualitas tinggi dari dokumen berukuran besar.
MinerU adalah alat ekstraksi data dokumen dan halaman web sumber terbuka lengkap yang dapat mengonversi dokumen PDF multi-modal termasuk gambar, tabel, rumus, dll. ke dalam format Penurunan Harga yang jelas dan mudah dianalisis. Itu juga dapat dengan cepat mengurai dan mengekstrak konten formal dari halaman web yang berisi informasi gangguan seperti iklan, dan mendukung konversi batch berbagai format seperti epub, mobi, docx, dll. ke dalam Markdown.
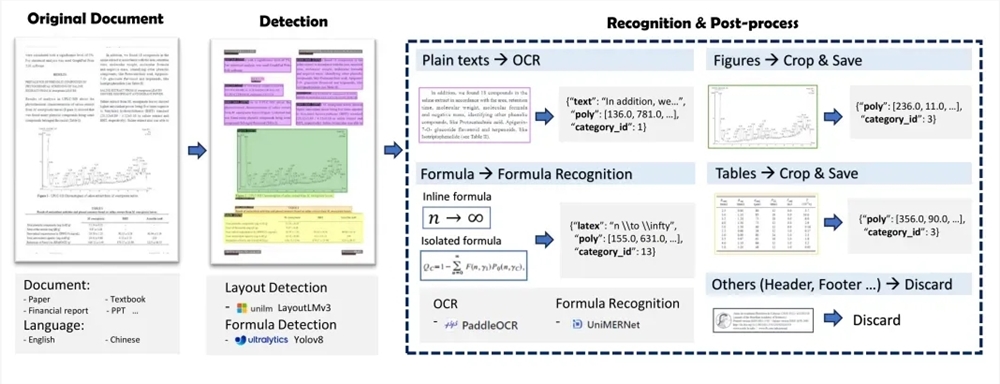
MinerU terdiri dari dua bagian utama: Magic-PDF dan Magic-Doc. Magic-PDF berfokus pada ekstraksi dokumen PDF dan mengubah PDF menjadi format Markdown. Ini dapat dengan cepat mengidentifikasi elemen tata letak PDF, secara otomatis menghapus konten non-teks, dan mempertahankan struktur dan format dokumen asli. Magic-Doc bertanggung jawab untuk mengekstraksi halaman web dan e-book, mendukung ekstraksi informasi halaman web umum seperti artikel, forum, musik, video, dll., serta konversi format e-book.
Pada tingkat teknis, proses ekstraksi dokumen PDF MinerU mencakup prapemrosesan klasifikasi dokumen PDF, analisis model, pemrosesan jalur pipa, dan pemeriksaan kualitas hasil ekstraksi PDF. Ini menggunakan serangkaian model, seperti LayoutLMv3, YOLOv8, UniMERNet dan PaddleOCR, untuk mencapai ekstraksi data dokumen berkualitas tinggi.
Peluncuran MinerU tidak hanya memberi peneliti AI alat pemrosesan data yang kuat, tetapi juga lebih lanjut mendorong peningkatan seluruh sistem alat rantai untuk pengembangan dan penerapan model besar.
Tautan pengalaman komunitas sihir:
https://modelscope.cn/studios/OpenDataLab/MinerU
Tautan kode sumber terbuka:
https://github.com/opendatalab/MinerU/
Model sumber terbuka MinerU (PDF-Extract-Kit):
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
Sumber terbuka dan kemudahan penggunaan MinerU akan sangat memudahkan peneliti dan pengembang AI, mempercepat efisiensi pemrosesan data di bidang AI, dan memberikan dukungan kuat untuk pengembangan model besar. Selamat mengunjungi tautan untuk merasakan dan menggunakan MinerU.