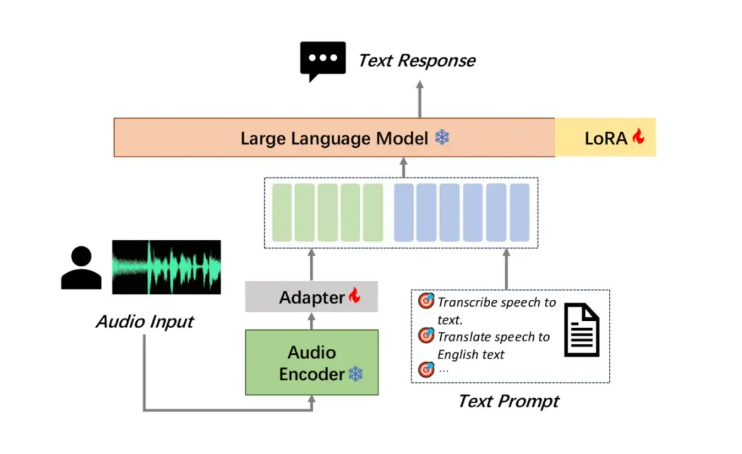
Moore Thread telah menjadikan model pemahaman audio besar MooER sebagai sumber terbuka, yang merupakan model ucapan sumber terbuka besar pertama di industri berdasarkan pelatihan dan inferensi GPU berfitur lengkap dalam negeri, yang merupakan sebuah pencapaian. MooER mendukung pengenalan suara berbahasa Mandarin dan Inggris serta terjemahan fonetik Mandarin-Inggris, menunjukkan kemampuan pemrosesan multi-bahasa yang kuat. Struktur model tiga bagian yang inovatif (Encoder, Adapter, dan Decoder) memungkinkan model memproses audio dan melakukan tugas hilir secara efisien. Saat ini, kode inferensi dan model yang dilatih berdasarkan 5.000 jam data telah bersumber terbuka, yang akan sangat mendorong pengembangan. teknologi audio AI di dalam dan luar negeri.
MooER berkinerja baik dalam uji komparatif beberapa model besar pemahaman audio sumber terbuka yang terkenal, dengan tingkat kesalahan kata dalam bahasa Mandarin (CER) serendah 4,21% dan tingkat kesalahan kata dalam bahasa Inggris (WER) sebesar 17,98%, terutama BLEU pada bahasa Mandarin -Set tes terjemahan bahasa Inggris. Skornya mencapai 25,2, memimpin model sumber terbuka lainnya. Model MooER-80k yang dilatih berdasarkan data berdurasi 80.000 jam memiliki performa yang lebih kuat, dengan CER dan WER masing-masing berkurang menjadi 3,50% dan 12,66%, yang menunjukkan potensi besar. Langkah Moore Thread ini tidak hanya menunjukkan kekuatan GPU domestik yang kuat di bidang AI, tetapi juga memberikan vitalitas baru dalam pengembangan teknologi audio AI global. MooER diharapkan dapat membawa lebih banyak terobosan di masa depan.
Dalam uji perbandingan dengan beberapa model besar pemahaman audio open source terkenal, MooER-5K berkinerja sangat baik. Pada tes bahasa Mandarin, tingkat kesalahan kata (CER) mencapai 4,21%; pada tes bahasa Inggris, tingkat kesalahan kata (WER) adalah 17,98%, lebih baik atau setara dengan model teratas lainnya. Perlu disebutkan secara khusus bahwa pada set tes terjemahan Mandarin-Inggris Covost2zh2en, skor BLEU MooER mencapai 25,2, jauh di depan model sumber terbuka lainnya dan mencapai tingkat yang sebanding dengan aplikasi tingkat industri.
Yang lebih menarik lagi adalah model MooER-80k yang dilatih berdasarkan data 80.000 jam menunjukkan performa yang lebih kuat. CER pada set pengujian bahasa Mandarin semakin turun menjadi 3,50%, dan WER pada set pengujian bahasa Inggris juga dioptimalkan menjadi 12,66. %. Menunjukkan potensi pengembangan yang sangat besar.
MooER open source Moore Thread tidak hanya menunjukkan kekuatan aplikasi GPU domestik di bidang AI, tetapi juga menyuntikkan vitalitas baru ke dalam pengembangan teknologi audio AI global. Dengan semakin banyaknya data dan kode pelatihan yang menjadi sumber terbuka, industri ini berharap MooER dapat membawa lebih banyak terobosan dalam pengenalan suara, terjemahan, dan bidang lainnya, serta mendorong pemasyarakatan dan penerapan inovatif teknologi audio AI.
Alamat: https://arxiv.org/pdf/2408.05101
MooER yang bersumber terbuka menandai bahwa GPU dalam negeri telah mencapai kemajuan signifikan di bidang model besar AI, menyediakan sumber daya dan platform berharga bagi pengembang dalam dan luar negeri. MooER diharapkan dapat berperan dalam lebih banyak skenario aplikasi di masa depan dan mendorong inovasi berkelanjutan serta pengembangan teknologi audio AI.