Penyetelan instruksi pada model besar adalah kunci untuk meningkatkan kinerjanya. Tencent Youtu Labs, bekerja sama dengan Shanghai Jiao Tong University, menerbitkan ulasan mendetail yang memberikan gambaran mendalam tentang evaluasi dan pemilihan kumpulan data penyetelan instruksi. Artikel sepanjang 10.000 kata ini, berdasarkan lebih dari 400 dokumen terkait, memberikan panduan komprehensif untuk penyesuaian instruksi model besar dari tiga dimensi kualitas, keragaman, dan kepentingan data, serta menunjukkan tantangan penelitian yang ada dan prospek pengembangan di masa depan arah. Artikel ini membahas berbagai metode evaluasi, termasuk indikator yang dirancang sendiri, indikator berbasis model, penilaian otomatis GPT, dan evaluasi manual, yang bertujuan untuk membantu peneliti memilih kumpulan data yang optimal dan meningkatkan kinerja dan stabilitas model besar.
Dengan peningkatan berulang yang berkelanjutan, model besar menjadi lebih pintar, namun agar mereka benar-benar memahami kebutuhan kita, penyesuaian instruksi adalah kuncinya. Para ahli dari Tencent Youtu Lab dan Shanghai Jiao Tong University bersama-sama menerbitkan ulasan sepanjang 10.000 kata yang membahas secara mendalam evaluasi dan pemilihan kumpulan data penyetelan instruksi, mengungkap misteri bagaimana meningkatkan kinerja model besar.
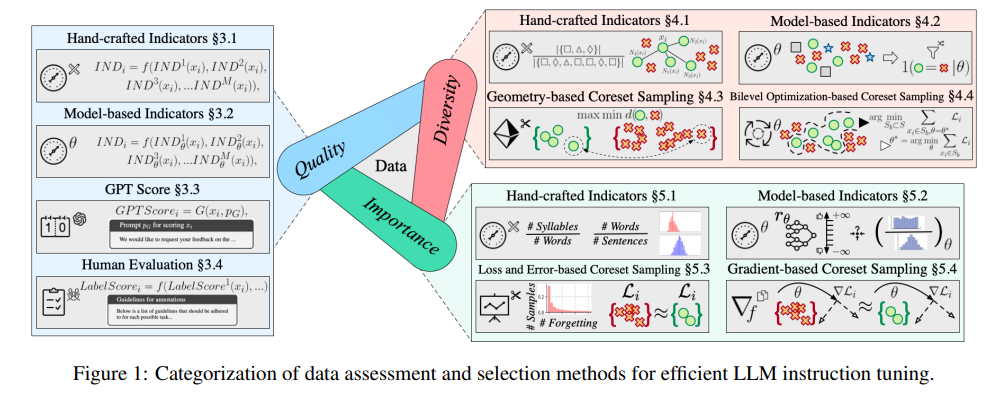
Tujuan dari model besar adalah untuk menguasai esensi pemrosesan bahasa alami, dan penyetelan instruksi merupakan langkah penting dalam proses pembelajaran mereka. Para ahli memberikan analisis mendalam tentang cara mengevaluasi dan memilih kumpulan data untuk memastikan bahwa model besar berkinerja baik di berbagai tugas.
Tinjauan ini tidak hanya luar biasa panjangnya, namun juga mencakup lebih dari 400 dokumen relevan, memberikan kita panduan terperinci dari tiga dimensi kualitas, keragaman, dan kepentingan data.
Kualitas data secara langsung mempengaruhi efektivitas penyetelan instruksi. Para ahli telah mengusulkan berbagai metode evaluasi, termasuk indikator yang dirancang sendiri, indikator berbasis model, penilaian otomatis GPT, dan evaluasi manual yang sangat diperlukan.
Penilaian keberagaman berfokus pada kekayaan kumpulan data, termasuk keragaman kosa kata, semantik, dan distribusi data secara keseluruhan. Dengan kumpulan data yang beragam, model dapat digeneralisasi dengan lebih baik ke berbagai skenario.
Evaluasi pentingnya adalah memilih sampel yang paling penting untuk pelatihan model. Hal ini tidak hanya meningkatkan efisiensi pelatihan, tetapi juga memastikan stabilitas dan akurasi model saat menghadapi tugas yang kompleks.
Meskipun penelitian saat ini telah mencapai hasil tertentu, para ahli juga menunjukkan tantangan yang ada, seperti lemahnya korelasi antara pemilihan data dan kinerja model, dan kurangnya standar terpadu untuk mengevaluasi kualitas instruksi.
Ke depannya, para ahli menyerukan pembentukan tolok ukur khusus untuk mengevaluasi model penyetelan instruksi sekaligus meningkatkan kemampuan interpretasi jalur seleksi untuk beradaptasi dengan berbagai tugas hilir.
Penelitian yang dilakukan oleh Tencent Youtu Lab dan Shanghai Jiao Tong University tidak hanya memberi kita sumber daya yang berharga, namun juga menunjukkan arah pengembangan model besar. Seiring dengan kemajuan teknologi, kita mempunyai alasan untuk percaya bahwa model berukuran besar akan menjadi lebih cerdas dan memberikan pelayanan yang lebih baik kepada manusia.
Alamat makalah: https://arxiv.org/pdf/2408.02085
Penelitian ini memberikan panduan berharga untuk penyetelan instruksi model besar dan meletakkan dasar yang kuat untuk pengembangan model besar di masa depan. Kami menantikan lebih banyak hasil penelitian serupa di masa depan, yang akan mendorong kemajuan berkelanjutan dari teknologi model besar dan memberikan pelayanan yang lebih baik kepada umat manusia.