Tencent Youtu Lab dan institusi lainnya telah menjadikan model bahasa besar multi-modal pertama VITA sebagai sumber terbuka, yang dapat memproses video, gambar, teks, dan audio secara bersamaan dan memberikan pengalaman interaktif yang lancar. Kemunculan VITA bertujuan untuk menutupi kekurangan model bahasa skala besar yang ada dalam pemrosesan dialek Tiongkok. Berdasarkan model Mixtral8×7B, kosakata bahasa Mandarin diperluas dan instruksi bilingual disempurnakan, sehingga keduanya mahir berbahasa Inggris. dan fasih berbahasa Cina. Hal ini menandai kemajuan signifikan bagi komunitas open source dalam pemahaman dan interaksi multimodal.
Baru-baru ini, para peneliti dari Tencent Youtu Lab dan institusi lain meluncurkan model bahasa besar multi-modal open source pertama VITA, yang dapat memproses video, gambar, teks, dan audio secara bersamaan, dan pengalaman interaktifnya juga kelas satu.
Model VITA lahir untuk mengisi kekurangan model bahasa besar dalam pengolahan dialek bahasa Mandarin. Ini didasarkan pada model Mixtral8×7B yang kuat, kosakata bahasa Mandarin yang diperluas, dan instruksi bilingual yang disempurnakan, membuat VITA tidak hanya mahir berbahasa Inggris, tetapi juga fasih berbahasa Mandarin.
Fitur utama:
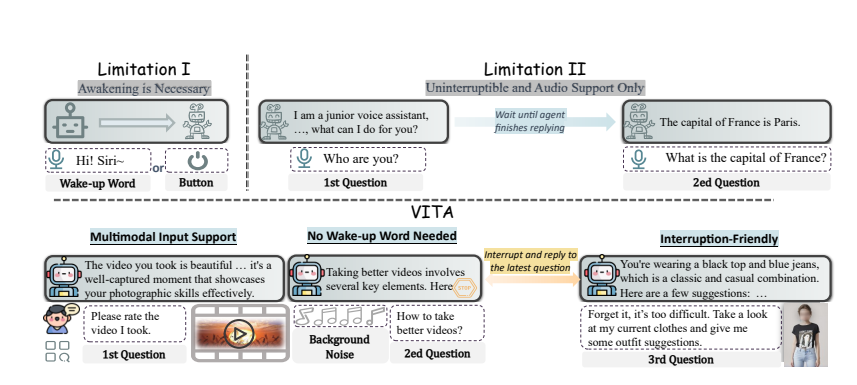
Pemahaman multimodal: Kemampuan VITA untuk memproses video, gambar, teks, dan audio belum pernah terjadi sebelumnya di antara model sumber terbuka.
Interaksi alami: Tidak perlu mengucapkan "Hai, VITA" setiap saat, ia dapat merespons kapan saja saat Anda berbicara, dan bahkan saat Anda sedang berbicara dengan orang lain, ia dapat tetap sopan dan tidak menyela sesuka hati.
Pelopor Sumber Terbuka: VITA merupakan langkah penting bagi komunitas sumber terbuka dalam pemahaman dan interaksi multi-modal, yang meletakkan dasar untuk penelitian selanjutnya.
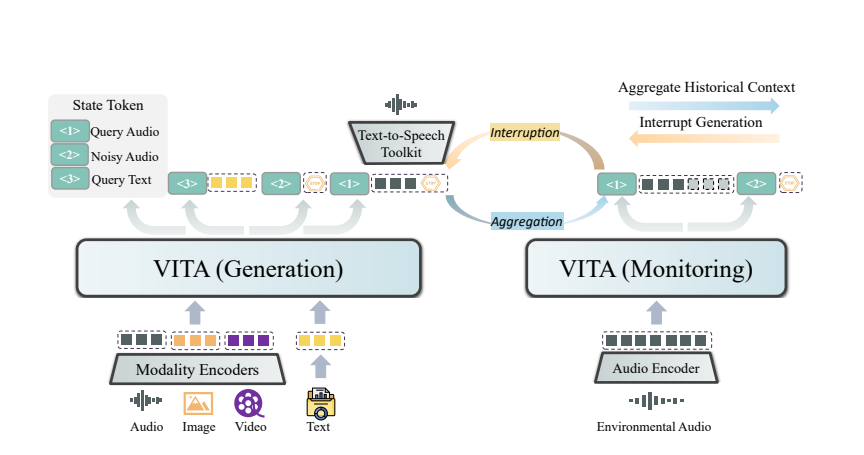
Keajaiban VITA berasal dari penerapan model gandanya. Satu model bertanggung jawab untuk menghasilkan tanggapan terhadap pertanyaan pengguna, dan model lainnya terus melacak masukan lingkungan untuk memastikan bahwa setiap interaksi akurat dan tepat waktu.
VITA tidak hanya bisa ngobrol saja, tapi juga bisa menjadi teman ngobrol saat berolahraga, bahkan memberikan nasehat saat bepergian. Itu juga dapat menjawab pertanyaan berdasarkan gambar atau konten video yang Anda berikan, menunjukkan kepraktisan yang kuat.
Meskipun VITA telah menunjukkan potensi besar, VITA masih terus berkembang dalam hal sintesis ucapan emosional dan dukungan multi-modal. Para peneliti berencana untuk memungkinkan VITA generasi berikutnya menghasilkan audio berkualitas tinggi dari video dan input teks, dan bahkan menjajaki kemungkinan menghasilkan audio dan video berkualitas tinggi secara bersamaan.
Open source model VITA tidak hanya merupakan kemenangan teknis, namun juga merupakan inovasi mendalam dalam cara interaksi cerdas. Dengan pendalaman penelitian, kami memiliki alasan untuk percaya bahwa VITA akan memberikan kami pengalaman interaktif yang lebih cerdas dan manusiawi.
Alamat makalah: https://arxiv.org/pdf/2408.05211
Sumber terbuka VITA memberikan arah baru untuk pengembangan model bahasa besar multi-modal. Fungsinya yang kuat dan pengalaman interaktif yang nyaman menunjukkan bahwa interaksi manusia-komputer akan lebih cerdas dan manusiawi di masa depan. Kami berharap VITA dapat membuat terobosan yang lebih besar di masa depan dan memberikan lebih banyak kemudahan bagi kehidupan masyarakat.