Alibaba telah meluncurkan model ucapan open source baru Qwen2-Audio, yang telah meningkatkan pengenalan ucapan, terjemahan, dan analisis audio secara signifikan. Fungsi dan kinerjanya melampaui produk generasi sebelumnya Qwen-Audio, dan bahkan melampauinya dalam beberapa pengujian benchmark OpenAI. besar-v3. Qwen2-Audio mendukung berbagai bahasa dan menyediakan versi dasar dan versi yang disempurnakan dengan instruksi. Pengguna dapat mengajukan pertanyaan melalui suara dan melakukan pengenalan dan analisis konten audio, seperti menentukan usia dan emosi pembicara atau menganalisis berbagai suara komponen dalam audio. Model ini menggunakan perintah bahasa yang lebih alami untuk pra-pelatihan, meningkatkan pemahaman dan kemampuan respons secara signifikan, serta memperkenalkan dua mode obrolan suara dan analisis audio untuk meningkatkan kealamian interaksi pengguna.
Baru-baru ini, Alibaba meluncurkan model pidato open source baru Qwen2-Audio berdasarkan Qwen-Audio-nya. Model ini tidak hanya berkinerja baik dalam pengenalan ucapan, terjemahan, dan analisis audio, namun juga mencapai peningkatan signifikan dalam fungsi dan kinerja. Qwen2-Audio menyediakan versi dasar dan versi instruksi yang disempurnakan. Pengguna dapat mengajukan pertanyaan kepada model audio melalui suara, dan mengenali serta menganalisis konten.
Misalnya, pengguna dapat meminta seorang wanita untuk berbicara, dan Qwen2-Audio dapat menentukan usianya atau menganalisis emosinya; jika suara berisik dimasukkan, model dapat menganalisis berbagai komponen suara. Qwen2-Audio mendukung berbagai bahasa termasuk Cina, Kanton, Prancis, Inggris, dan Jepang, yang memberikan kemudahan luar biasa untuk pengembangan analisis sentimen dan aplikasi terjemahan.
Pintu masuk produk: https://top.aibase.com/tool/qwen2-audio
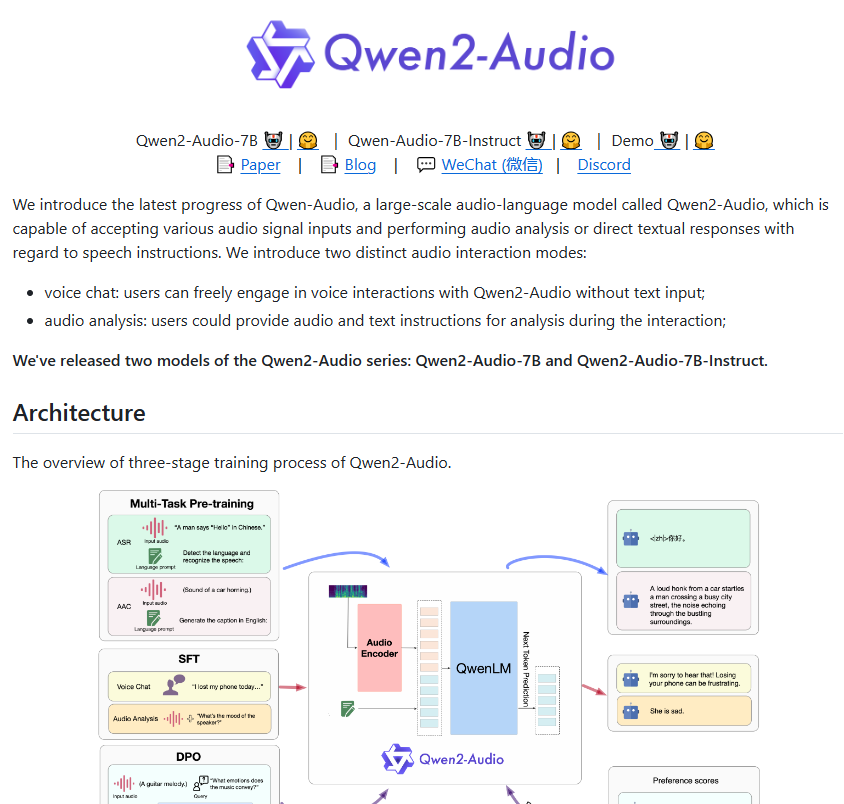
Dibandingkan dengan Qwen-Audio generasi pertama, Qwen2-Audio telah sepenuhnya dioptimalkan dalam arsitektur dan kinerja. Pada tahap pra-pelatihan, model baru ini menggunakan isyarat bahasa yang lebih alami untuk menggantikan label hierarki kompleks sebelumnya. Peningkatan ini membuat model lebih mudah untuk memahami dan merespons berbagai tugas, dan kemampuan generalisasinya juga meningkat secara signifikan.
Kemampuan mengikuti perintah Qwen2-Audio juga telah ditingkatkan secara signifikan, dan dapat memahami perintah pengguna dengan lebih akurat. Misalnya, ketika pengguna mengeluarkan perintah "analisis kecenderungan emosional dalam audio ini", Qwen2-Audio dapat secara akurat menentukan emosi yang terkandung dalam audio tersebut. Selain itu, model ini memperkenalkan dua mode: obrolan suara dan analisis audio, menjadikan interaksi suara pengguna lebih alami. Dalam mode analisis audio, Qwen2-Audio dapat menganalisis berbagai jenis audio secara mendalam dan memberikan hasil analisis yang detail dan akurat.
Untuk memastikan bahwa keluaran model memenuhi harapan manusia, Qwen2-Audio juga memperkenalkan teknologi canggih seperti penyempurnaan yang diawasi dan optimalisasi preferensi langsung. Model tampil lebih natural dan akurat saat berinteraksi dengan manusia.
Dalam hal pengujian kinerja, Qwen2-Audio berkinerja baik dalam beberapa tes benchmark mainstream, terutama dalam akurasi pengenalan suara dan terjemahan, melampaui Whisper-large-v3 OpenAI. Performa model baru ini tidak hanya menarik perhatian luas di industri, namun juga menandai masa depan baru bagi teknologi suara.
Menyorot:
Qwen2-Audio adalah model ucapan open source terbaru dari Alibaba, yang mendukung berbagai bahasa dan memiliki kemampuan pengenalan dan analisis yang kuat.
Dibandingkan dengan generasi sebelumnya, Qwen2-Audio telah sangat dioptimalkan dalam performa dan arsitektur, meningkatkan kemampuannya untuk memahami dan merespons.
? Dalam beberapa tes kinerja, Qwen2-Audio mengungguli Whisper OpenAI, menunjukkan daya saing yang kuat.
Sumber terbuka Qwen2-Audio akan mendorong perkembangan bidang teknologi suara, menyediakan alat canggih bagi pengembang, dan mendorong lahirnya aplikasi yang lebih inovatif. Keunggulannya dalam dukungan dan kinerja multi-bahasa menjadikannya arah penting bagi pengembangan teknologi suara di masa depan. Menantikan penerapan Qwen2-Audio dalam lebih banyak skenario.