Model bahasa besar (LLM) menghadapi tantangan dalam pemahaman teks yang panjang, dan ukuran jendela konteksnya membatasi kemampuan pemrosesannya. Untuk mengatasi masalah ini, peneliti mengembangkan tes benchmark LooGLE untuk mengevaluasi kemampuan pemahaman konteks panjang LLM. LooGLE berisi 776 dokumen ultra-panjang (rata-rata 19,3 ribu kata) yang dirilis setelah tahun 2022 dan 6448 contoh pengujian, yang mencakup berbagai bidang, yang bertujuan untuk mengevaluasi kemampuan model secara lebih komprehensif dalam memahami dan memproses teks panjang. Tolok ukur ini mengevaluasi kinerja LLM yang ada dan memberikan referensi berharga untuk pengembangan model masa depan.
Di bidang pemrosesan bahasa alami, pemahaman konteks panjang selalu menjadi tantangan. Meskipun model bahasa besar (LLM) bekerja dengan baik pada berbagai tugas bahasa, model tersebut sering kali terbatas saat memproses teks yang melebihi ukuran jendela konteksnya. Untuk mengatasi keterbatasan ini, para peneliti telah bekerja keras untuk meningkatkan kemampuan LLM untuk memahami teks yang panjang, yang tidak hanya penting untuk penelitian akademis, tetapi juga untuk skenario aplikasi dunia nyata, seperti pemahaman pengetahuan khusus domain, panjang pembuatan dialog, dan cerita panjang. Atau pembuatan kode, dll., juga penting.
Dalam penelitian ini, penulis mengusulkan tes benchmark baru - LooGLE (Long Context Generic Language Evaluation), yang dirancang khusus untuk mengevaluasi kemampuan pemahaman konteks panjang LLM. Tolok ukur ini berisi 776 dokumen ultra-panjang setelah tahun 2022, setiap dokumen berisi rata-rata 19,3 ribu kata, dan memiliki 6448 contoh pengujian, yang mencakup berbagai bidang, seperti akademik, sejarah, olahraga, politik, seni, acara dan hiburan, dll.
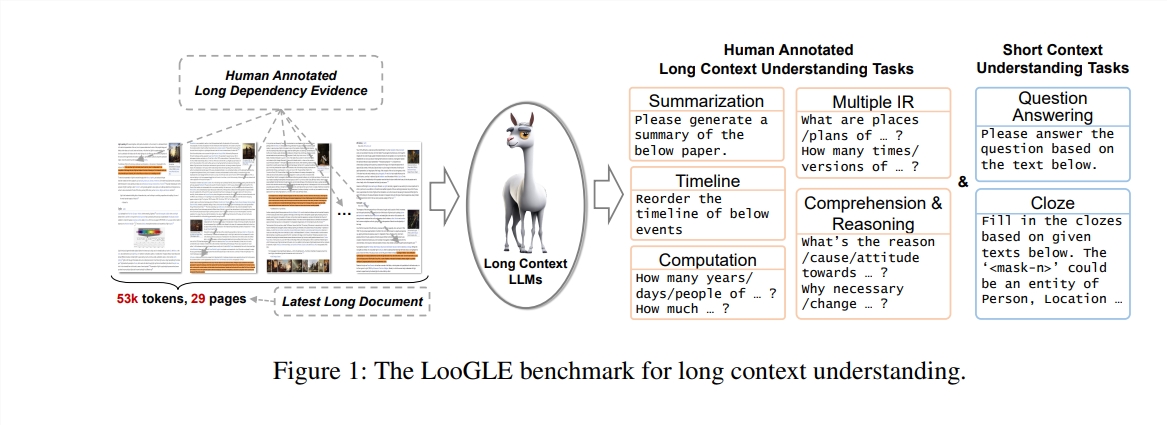
Fitur LooGLE
Dokumen nyata yang sangat panjang: Panjang dokumen di ooGLE jauh melebihi ukuran jendela konteks LLM, yang mengharuskan model untuk dapat mengingat dan memahami teks yang lebih panjang.
Tugas ketergantungan panjang dan pendek yang dirancang secara manual: Tes benchmark berisi 7 tugas utama, termasuk tugas ketergantungan pendek dan ketergantungan panjang, untuk mengevaluasi kemampuan LLM dalam memahami konten ketergantungan panjang dan pendek.
Dokumen yang relatif baru: Semua dokumen dirilis setelah tahun 2022, yang memastikan bahwa sebagian besar LLM modern belum terpapar dokumen-dokumen ini selama pra-pelatihan, sehingga memungkinkan penilaian yang lebih akurat terhadap kemampuan pembelajaran kontekstual mereka.
Data umum lintas domain: Data tolok ukur berasal dari dokumen sumber terbuka populer, seperti makalah arXiv, artikel Wikipedia, skrip film dan TV, dll.
Para peneliti melakukan evaluasi komprehensif terhadap delapan LLM mutakhir, dan hasilnya mengungkapkan temuan utama berikut:
Model komersial mengungguli model open source dalam hal kinerja.
LLM bekerja dengan baik pada tugas-tugas ketergantungan pendek namun menghadirkan tantangan pada tugas-tugas ketergantungan panjang yang lebih kompleks.
Metode yang didasarkan pada pembelajaran konteks dan rantai pemikiran hanya memberikan perbaikan terbatas dalam pemahaman konteks jangka panjang.
Teknik berbasis pengambilan menunjukkan keuntungan yang signifikan dalam menjawab pertanyaan singkat, sementara strategi untuk memperluas panjang jendela konteks melalui arsitektur Transformer yang dioptimalkan atau pengkodean posisi memiliki dampak yang terbatas pada pemahaman konteks yang panjang.
Tolok ukur LooGLE tidak hanya memberikan skema evaluasi yang sistematis dan komprehensif untuk mengevaluasi LLM konteks panjang, namun juga memberikan panduan untuk pengembangan model di masa depan dengan kemampuan "pemahaman konteks panjang yang sebenarnya". Semua kode evaluasi telah dipublikasikan di GitHub untuk referensi dan digunakan oleh komunitas riset.
Alamat makalah: https://arxiv.org/pdf/2311.04939
Alamat kode: https://github.com/bigai-nlco/LooGLE
Tolok ukur LooGLE menyediakan alat penting untuk mengevaluasi dan meningkatkan kemampuan pemahaman teks panjang LLM, dan hasil penelitiannya sangat penting dalam mendorong pengembangan bidang pemrosesan bahasa alami. Arahan perbaikan yang diusulkan oleh para peneliti patut mendapat perhatian. Saya percaya bahwa LLM yang lebih kuat akan muncul di masa depan untuk menangani teks panjang dengan lebih baik.