Apple dan Meta AI bersama-sama meluncurkan teknologi baru yang disebut LazyLLM, yang dirancang untuk meningkatkan efisiensi model bahasa besar (LLM) secara signifikan dalam memproses penalaran teks panjang. Ketika LLM saat ini memproses permintaan yang lama, kompleksitas komputasi dari mekanisme perhatian meningkat seiring dengan kuadrat jumlah token, sehingga mengakibatkan kecepatan yang lambat, terutama pada tahap pra-pengisian. LazyLLM secara dinamis memilih token penting untuk perhitungan, secara efektif mengurangi jumlah perhitungan, dan memperkenalkan mekanisme Aux Cache untuk memulihkan token yang dipangkas secara efisien, sehingga meningkatkan kecepatan sekaligus memastikan akurasi.
Baru-baru ini, tim peneliti Apple dan peneliti Meta AI bersama-sama meluncurkan teknologi baru yang disebut LazyLLM, yang meningkatkan efisiensi model bahasa besar (LLM) dalam penalaran teks panjang.
Seperti yang kita ketahui bersama, LLM saat ini sering menghadapi masalah kecepatan lambat saat memproses prompt yang panjang, terutama pada tahap pre-charge. Hal ini terutama karena kompleksitas komputasi arsitektur transformator modern saat menghitung perhatian tumbuh secara kuadrat dengan jumlah token dalam petunjuknya. Oleh karena itu, ketika menggunakan model Llama2, waktu penghitungan token pertama seringkali 21 kali lipat dari langkah penguraian kode berikutnya, yang merupakan 23% dari waktu pembuatan.
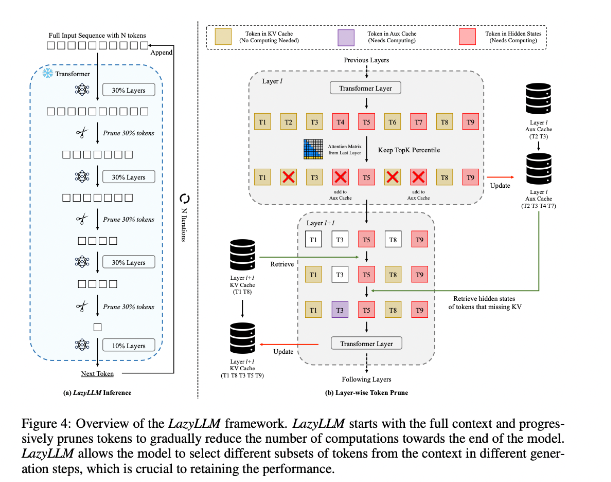
Untuk memperbaiki situasi ini, peneliti mengusulkan LazyLLM, yang merupakan metode baru untuk mempercepat inferensi LLM dengan memilih metode penghitungan token penting secara dinamis. Inti dari LazyLLM adalah mengevaluasi pentingnya setiap token berdasarkan skor perhatian lapisan sebelumnya, sehingga secara bertahap mengurangi jumlah penghitungan. Tidak seperti kompresi permanen, LazyLLM dapat memulihkan token yang dipangkas bila diperlukan untuk memastikan keakuratan model. Selain itu, LazyLLM memperkenalkan mekanisme yang disebut Aux Cache, yang dapat menyimpan keadaan implisit dari token yang dipangkas untuk memulihkan token ini secara efisien dan mencegah penurunan kinerja.
LazyLLM unggul dalam kecepatan inferensi, terutama pada tahap pra-pengisian dan decoding. Tiga keuntungan utama teknik ini adalah kompatibel dengan LLM berbasis transformator apa pun, tidak memerlukan pelatihan ulang model selama implementasi, dan bekerja dengan sangat efektif pada berbagai tugas bahasa. Strategi pemangkasan dinamis LazyLLM memungkinkannya mengurangi jumlah penghitungan secara signifikan sambil tetap mempertahankan token paling penting, sehingga meningkatkan kecepatan pembuatan.
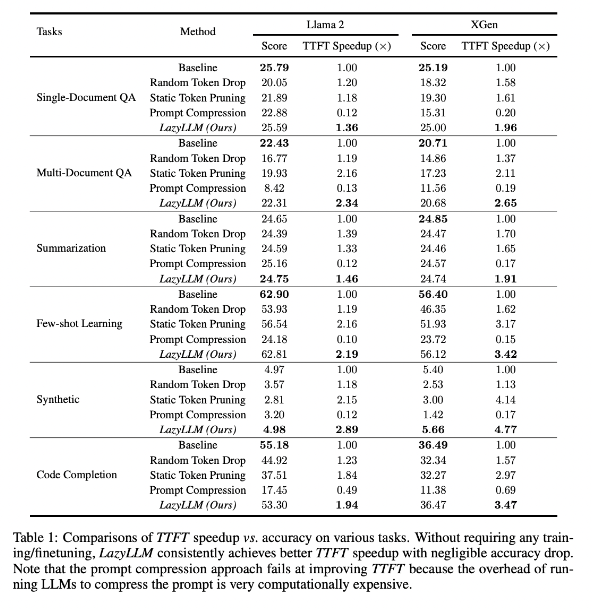
Hasil penelitian menunjukkan bahwa LazyLLM berkinerja baik pada tugas berbagai bahasa, dengan kecepatan TTFT meningkat 2,89 kali (untuk Llama2) dan 4,77 kali (untuk XGen), sedangkan akurasinya hampir sama dengan baseline. Baik itu menjawab pertanyaan, pembuatan ringkasan, atau tugas penyelesaian kode, LazyLLM dapat mencapai kecepatan pembuatan yang lebih cepat dan mencapai keseimbangan yang baik antara kinerja dan kecepatan. Strategi pemangkasan progresif ditambah dengan analisis lapis demi lapis meletakkan dasar bagi kesuksesan LazyLLM.
Alamat makalah: https://arxiv.org/abs/2407.14057
Highlight:
LazyLLM mempercepat proses penalaran LLM dengan memilih token penting secara dinamis, terutama dalam skenario teks panjang.
Teknologi ini dapat meningkatkan kecepatan inferensi secara signifikan, dan kecepatan TTFT dapat ditingkatkan hingga 4,77 kali lipat, dengan tetap menjaga akurasi yang tinggi.
LazyLLM tidak memerlukan modifikasi pada model yang ada, kompatibel dengan LLM berbasis konverter apa pun, dan mudah diterapkan.
Secara keseluruhan, kemunculan LazyLLM memberikan ide-ide baru dan solusi efektif untuk memecahkan masalah efisiensi penalaran teks panjang LLM. Performanya yang luar biasa dalam kecepatan dan akurasi menunjukkan bahwa ia akan memainkan peran penting dalam aplikasi model besar di masa depan. Teknologi ini memiliki prospek penerapan yang luas dan layak untuk dinantikan pengembangan dan penerapannya lebih lanjut.