Apple, bersama dengan Universitas Washington dan institusi lainnya, merilis model bahasa canggih yang disebut DCLM sebagai sumber terbuka, dengan ukuran parameter 700 juta dan jumlah data pelatihan yang mencengangkan mencapai 2,5 triliun token data. DCLM bukan hanya model bahasa yang efisien, namun yang lebih penting, DCLM menyediakan alat yang disebut "Dataset Competition" (DataComp) untuk mengoptimalkan kumpulan data model bahasa. Inovasi ini tidak hanya meningkatkan kinerja model, tetapi juga memberikan metode dan standar baru untuk penelitian model bahasa, yang patut mendapat perhatian.
Baru-baru ini, tim kecerdasan buatan Apple bekerja sama dengan banyak institusi seperti Universitas Washington untuk meluncurkan model bahasa sumber terbuka yang disebut DCLM. Model ini memiliki 700 juta parameter dan menggunakan hingga 2,5 triliun token data selama pelatihan untuk membantu kita lebih memahami dan menghasilkan bahasa.
Jadi, apa itu model bahasa? Sederhananya, ini adalah program yang dapat menganalisis dan menghasilkan bahasa, membantu kita menyelesaikan berbagai tugas seperti penerjemahan, pembuatan teks, dan analisis sentimen. Agar model ini berperforma lebih baik, kita memerlukan kumpulan data yang berkualitas. Namun, memperoleh dan mengatur data ini bukanlah tugas yang mudah karena kami perlu menyaring konten yang tidak relevan atau berbahaya dan menghapus informasi duplikat.
Untuk mengatasi tantangan ini, tim riset Apple meluncurkan DataComp for Language Models (DCLM), alat pengoptimalan kumpulan data untuk model bahasa. Mereka baru-baru ini melakukan open source model DCIM dan kumpulan data pada platform Hugging Face. Versi open source termasuk DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 dan dclm-baseline-1.0-parquet dan menemukan solusi terbaik.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
Kekuatan inti DCLM adalah alur kerjanya yang terstruktur. Peneliti dapat memilih model dengan ukuran berbeda tergantung kebutuhannya, mulai dari 412 juta hingga 700 juta parameter, dan juga dapat bereksperimen dengan metode kurasi data yang berbeda, seperti deduplikasi dan pemfilteran. Melalui eksperimen sistematis ini, peneliti dapat dengan jelas menilai kualitas kumpulan data yang berbeda. Hal ini tidak hanya menjadi landasan bagi penelitian di masa depan, namun juga membantu kita memahami cara meningkatkan performa model dengan menyempurnakan kumpulan data.
Misalnya, dengan menggunakan kumpulan data benchmark yang dibuat oleh DCLM, tim peneliti melatih model bahasa dengan 700 juta parameter, dan mencapai akurasi 5 tembakan sebesar 64% dalam pengujian benchmark MMLU! Ini merupakan peningkatan 6,6 dibandingkan sebelumnya tingkat tertinggi. poin persentase dan menggunakan sumber daya komputasi 40% lebih sedikit. Performa model dasar DCLM juga sebanding dengan Mistral-7B-v0.3 dan Llama38B, yang memerlukan lebih banyak sumber daya komputasi.
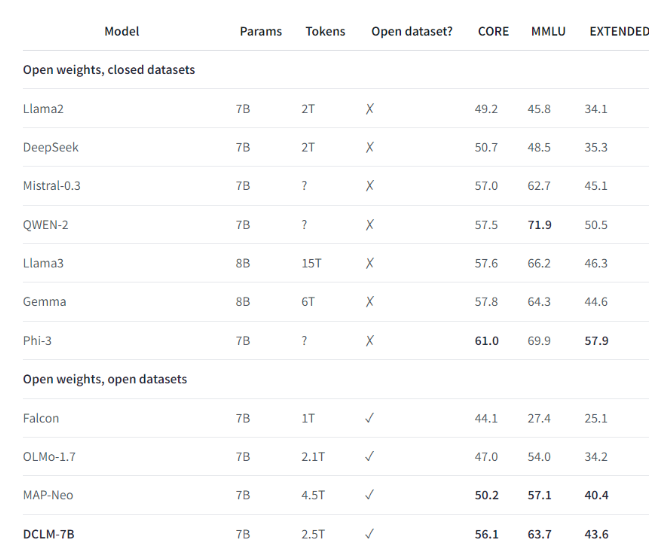
Peluncuran DCLM memberikan tolok ukur baru untuk penelitian model bahasa, membantu para ilmuwan meningkatkan kinerja model secara sistematis sekaligus mengurangi sumber daya komputasi yang diperlukan.
Highlight:
1️⃣ Apple AI bekerja sama dengan banyak institusi untuk meluncurkan DCLM, menciptakan model bahasa sumber terbuka yang kuat.
2️⃣ DCLM menyediakan alat pengoptimalan kumpulan data standar untuk membantu peneliti melakukan eksperimen yang efektif.
3️⃣ Model baru ini membuat kemajuan signifikan dalam pengujian penting sekaligus mengurangi kebutuhan sumber daya komputasi.
Secara keseluruhan, sumber terbuka DCLM telah memberikan vitalitas baru ke dalam bidang penelitian model bahasa, dan model yang efisien serta alat pengoptimalan kumpulan datanya diharapkan dapat mendorong pengembangan yang lebih cepat di bidang tersebut dan mendorong lahirnya model bahasa yang lebih kuat dan efisien. Di masa depan, kami berharap DCLM dapat memberikan hasil penelitian yang lebih mengejutkan.